- Tomita-Parser
-
Ein Tomita-Parser (nach Masaru Tomita) ist ein Parsverfahren für kontextfreie Grammatiken, das eine Verallgemeinerung des LR(k)-Verfahrens ist. Das Verfahren wird deshalb auch GLR(k)-Verfahren (für Generalized LR(k)) genannt.
Ausgangspunkt des Tomita-Parsers ist der Tabellenerstellungsvorgang des LR(k)-Verfahrens. Bei Grammatiken, die nicht die LR(k)-Eigenschaft haben (u.a., aber nicht nur, ambige Grammatiken), führt dieser Vorgang zu Mehrfacheinträgen, sog. Konflikten:
- Shift-Reduce-Konflikt: es besteht die Möglichkeit, das nächste Eingabesymbol auf den Stapel des Parsers zu legen oder eine erkannte rechte Seite einer Produktionsregel durch die linke Regelseite zu ersetzen.
- Reduce-Reduce-Konflikt: es gibt mindestens zwei Produktionsregeln, mit deren Hilfe eine Reduktion erfolgen kann.
Der Algorithmus des Tomita-Parsers verfolgt diese Konflikte pseudo-parallel weiter. Als Datenstruktur wird ein sog. Graphstapel (graph structured stack) - ein gerichteter azyklischer Graph - verwendet, der alle bereits vollzogenen Parsoperationen repräsentiert.
Inhaltsverzeichnis
Graphstapel
Die verwendete Repräsentation der Parsergebnisse geschieht – ähnlich wie beim Chart-Parser - mittels eines gerichteten azyklischen Graphen.
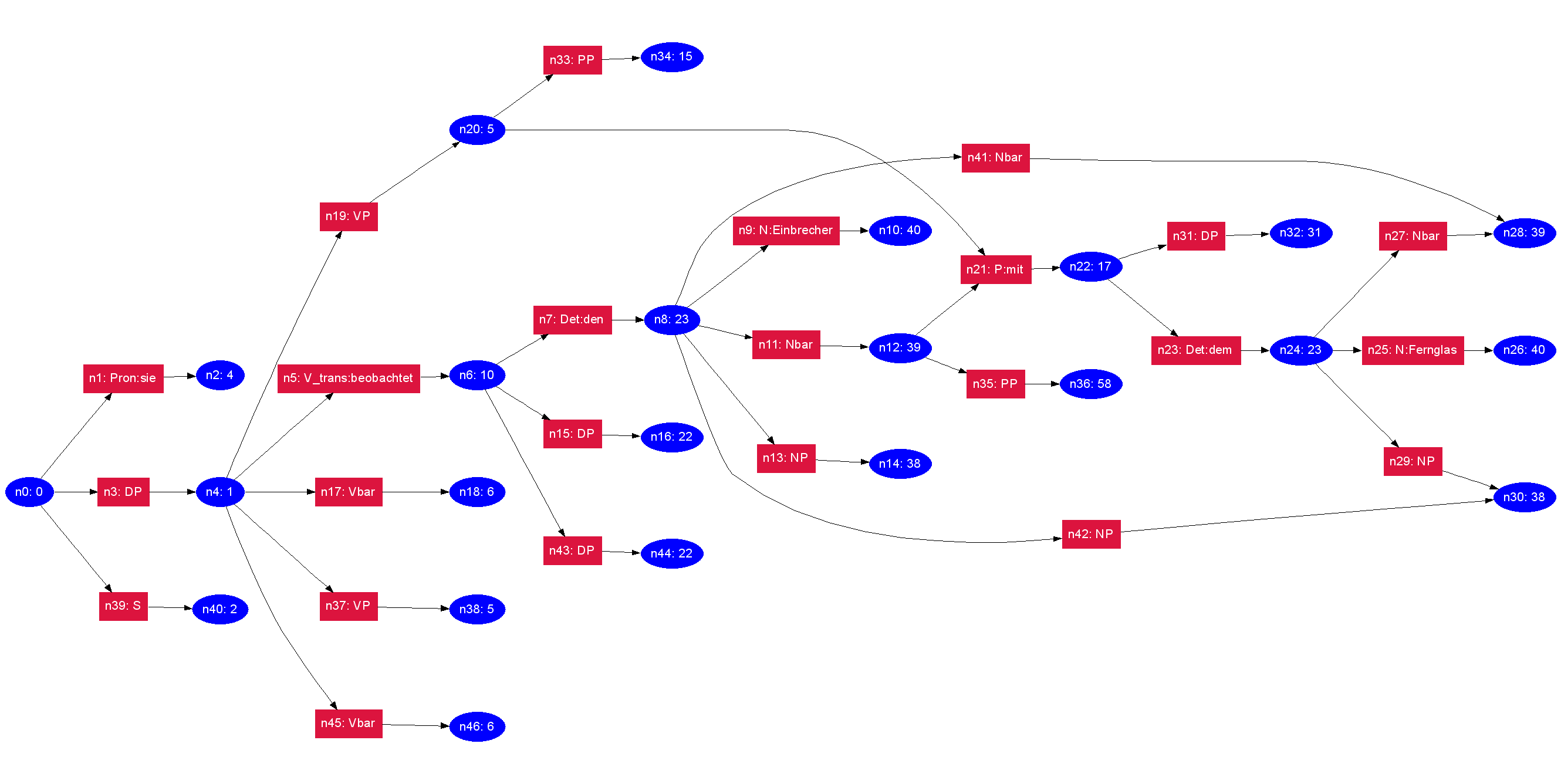
 Abb 1.: Graphstack für den Satz sie beobachtet den Einbrecher mit dem Fernglas
Abb 1.: Graphstack für den Satz sie beobachtet den Einbrecher mit dem Fernglas
Abb. 1 zeigt einen solchen Graphen nach Beendigung des Parsvorgangs für den Beispielsatz „sie beobachtet den Einbrecher mit dem Fernglas“.
Die dabei verwendete, ambige Grammatik ist:
- S → DP VP
- VP → Vbar
- VP → VP PP
- Vbar → Vtrans DP
- DP → Det NP
- DP → Pron
- NP → Nbar
- Nbar → N
- Nbar → Nbar PP
- PP → P DP
Für den Beispielsatz erlaubt sie zwei verschiedene syntaktische Analysen. Aufgrund dieser Ambiguität hat sie nicht die LR(k)-Eigenschaft, führt also zu Mehrfacheinträgen in der Parstabelle.
Jeder Graphknoten hat einen eindeutigen Knotennamen (dieser beginnt mit „n“). Die roten Knoten enthalten Elemente aus dem Vokabular der Grammatik, also einerseits Nichtterminalsymbole und andererseits Wörter (Terminalsymbole). Die blauen Knoten dagegen enthalten Zustandsnummern der LR-Parstabelle. Man kann schön sehen, wie im Knoten n21 zwei bis dahin verschiedene Analysen bei der Integration der Präposition „mit“ wieder zusammenlaufen. Die nachfolgende Präpositionalphrase „mit dem Fernglas“ wird also nur einmal analysiert.
Parsalgorithmus
Wie beim LR(k)-Verfahren besteht der Parsprozess aus eine Reihe von tabellengesteuerten Shift- bzw. Reduktionsschritten. Beim Shift-Schritt wird ein Wort aus der Eingabe entfernt und auf den Stapel gelegt. Bei einem Reduktionsschritt wird die rechte Seite (γ) einer Produktionsregel A → γ, die in umgekehrter Reihenfolge auf dem Stapel liegt, durch die linke Regelseite (A) ersetzt. Im Unterschied zum LR(k)-Verfahren wird der reduzierte Teil jedoch nicht aus dem Stapel gelöscht, sondern bleibt erhalten. Dies bedeutet, dass der Stapel monoton wächst.
Der Vorgang wird durch die GLR(k)-Tabelle gesteuert. Zu jedem Zeitpunkt befindet sich der Parser in einem definierten Zustand (vgl. Kellerautomat). Mit diesem Zustand und dem/den nächsten Symbol(en) der Eingabe wird die GLR(k)-Tabelle konsultiert und die nächsten Operationen (shift, reduce, accept, error) und der Folgezustand bestimmt. Im Fall von Mehrfacheinträgen (Konflikten) werden diese quasi parallel verfolgt. Nachfolgende Shift-Operationen können diese parallelen Verarbeitungsstränge jedoch wieder synchronisieren; dies ist wichtig für die Zeitkomplexität des Verfahrens.
Beziehung zu anderen Parsverfahren
Der Tomita-Parser ist ein vorkompilierter Chart-Parser.
Literatur
- Dick Grune, Jacobs, Ceriel J.H: Parsing Techniques. Springer Science+Business Media 2008, ISBN 978-0-387-20248-8
- Masaru Tomita: LR parsers for natural languages. In: Coling 1984: 10th International Conference on Computational Linguistics. 1984, S. 354–357.
- Masaru Tomita: An efficient context-free parsing algorithm for natural languages. In: International Joint Conference on Artificial Intelligence. 1985, S. 756–764.
Kategorien:- Compilerbau
- Theorie formaler Sprachen
Wikimedia Foundation.