- Arrayprozessor
-
 Prozessorplating eines CRAY-YMP-Vektor-Computers
Prozessorplating eines CRAY-YMP-Vektor-ComputersVektorprozessoren (auch Vektorrechner oder Array-Prozessoren genannt) führen eine Berechnung gleichzeitig auf vielen Daten (in einem Vektor bzw. Array) aus. Wenn viele gleichartige Daten auf gleiche Weise bearbeitet werden sollen (beispielsweise bei Matrizenoperationen), so sind Vektorprozessoren reinen Allzweck-Prozessoren (z. B. x86), die jedes Datum nacheinander bearbeiten, weit überlegen. Dies ist zumindest dann der Fall, wenn der Vektorrechner auch einen parallelen Zugriff auf den Hauptspeicher hat.
Inhaltsverzeichnis
Funktionsweise und Anwendungsfelder
Vektorprozessoren werden vor allem im High-Performance-Computing (HPC) genutzt. Die legendären Cray-Supercomputer nutzten Vektorprozessoren und der über mehrere Jahre hinweg leistungsfähigste Computer der Welt, der Earth Simulator, arbeitet mit Vektorprozessoren von NEC. Weitere Anbieter von Vektorrechnern waren die Convex Computer Corporation, z. B. mit der C38xx-Serie, die GaAs-Technologie einsetzte, oder Fujitsu Siemens Computers mit ihrer VPP-Serie.
Erhebliche Performancegewinne ergeben sich auch durch vektorisierende Algorithmen: Man vergleiche beispielsweise den Performancegewinn bei vektorisierten numerischen Operationen gegenüber ‚herkömmlicher‘ Numerik in MATLAB.
Gerade in HPC-Anwendungen fallen oft viele gleichartige Daten an, die auf ähnliche Weise verarbeitet werden sollen, so zum Beispiel bei Simulationen in der Meteorologie und Geologie, wo vielfach Vektorrechner verwendet werden.
Vektorrechner haben in den letzten Jahren große Konkurrenz durch massiv parallel aufgebaute Rechencluster bekommen, die aus vielen Tausend Standardprozessoren aufgebaut sind. Durch den Rückgriff auf Standardkomponenten, die über den HPC-Sektor hinaus verbreitet sind, lassen sich Kosten sparen, zumal solche Standardprozessoren durch die intensive technologische Entwicklung sehr leistungsfähig geworden sind. Noch günstiger geht es mit verteiltem Rechnen.
Wegen der Vorteile, die sich durch die gleichzeitige Ausführung einer Rechenoperation auf mehreren Daten ergeben (Single Instruction, Multiple Data, SIMD) haben auch Standardprozessoren seit den 1990er Jahren Erweiterungen der jeweiligen Architektur erfahren, um diese Art von Berechnungen zu beschleunigen. Siehe dazu Architektur des x86-Prozessors.
Neben der oben genannten Anwendungen für Vektorprozessoren gehört auch die graphische Simulation zu einer Hauptanwendung. Gerade aufwendige 3D-Spiele verlangen enorm viele Berechnungen (Matrizenoperationen auf 3D-Koordinaten, Antialiasing der Bildschirmausgabe) auf großen Datenmengen, weshalb heutige Grafikprozessoren große Ähnlichkeiten zu reinen Vektorprozessoren aufweisen.
Vektorprozessor bei der Arbeit
Anhand eines einfachen Beispiels soll der Unterschied zwischen Skalar- und Vektorprozessor gezeigt werden.
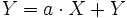
X und Y sind zwei Vektoren gleicher Länge und a ist eine skalare Größe. Dieses Problem wird auf Skalarprozessoren durch eine Schleife gelöst. Die gleiche Schleife wird auch im Linpack-Benchmark verwendet, um die Leistung der getesteten Rechner zu bestimmen. In C-Syntax sieht das folgendermaßen aus:
for (i=0; i <= 63; i++) Y[i] = a * X[i] + Y[i];Hier wird angenommen, dass die Vektoren eine Länge von 64 Zeilen haben.
In MIPS-Code sieht dieses Programmfragment folgendermaßen aus:
L.D F0, a ; Skalar a laden DADDIU R4, Rx, #512 ; letzte Adresse 512/8 = 64 Loop: L.D F2, 0(Rx) ; X(i) laden MUL.D F2, F2, F0 ; a * X(i) L.D F4, 0(Ry) ; Y(i) laden ADD.D F4, F4, F2 ; a * X(i) + Y(i) S.D 0(Ry), F4 ; Y(i) speichern DADDIU Rx, Rx, #8 ; Index (i) von X inkrementieren DADDIU Ry, Ry, #8 ; Index (i) von Y inkrementieren DSUBU R20, R4, Rx ; Rand berechnen BNEZ R20, Loop ; wenn 0, dann fertigIn VMIPS-Code sieht das Ganze jedoch so aus:
L.D F0, a ; Skalar a laden LV V1, Rx ; Vector X laden MULVS.D V2, V1, F0 ; Vector-Skalar Multiplikation LV V3, Ry ; Vector Y laden ADDV.D V4, V2, V3 ; Vektor Addition SV Ry, V4 ; Resultat speichernDieses Beispiel zeigt, wie elegant der Vektorprozessor die Aufgabe löst. Bei VMIPS genügen 6 Befehle, während bei MIPS 64*9 + 2 = 578 Befehle ausgeführt wurden. Hauptsächlich entfällt die Schleife. Bei VMIPS muss also nur ein Bruchteil der Befehle aus dem Speicher geholt und dekodiert werden.
Bei der MIPS-Architektur werden Multiplikationen und Additionen abwechselnd ausgeführt, d. h. die Addition muss immer auf die langsamere Multiplikation warten. Beim Vektorrechner hingegen werden zuerst alle unabhängigen Multiplikationen ausgeführt und darauf folgend alle abhängigen Additionen. Dies ist ein weiterer bedeutender Unterschied.
Programmierung von Vektorprozessoren mit höheren Programmiersprachen
Das obige Beispiel ist direkt in der Maschinensprache codiert, was heutzutage allerdings nicht mehr üblich ist. Architekturen mit speziellen Maschinenanweisungen für Vektoren benötigen zur Nutzung dieser aus höheren Programmiersprachen entweder eine Unterstützung durch
- parallelisierende Compiler (also solche, die eine ganze Schleife im Quellcode in eine SIMD-Rechenanweisung umwandeln können)
- eine Spracherweiterung für die Generierung der Array-Funktionen
- oder zumindest durch spezielle Bibliotheksfunktionen
Zumindest in den letzten beiden Fällen muss der Entwickler auf jeden Fall die Architektur kennen und die speziellen Funktionen dann auch verwenden, um die Vektorverarbeitung zu nutzen.
Siehe auch
- Flynnsche Klassifikation
- Parallelrechner – Datenverarbeitung in verteilten CPUs
Weblinks

Wikimedia Foundation.