- Polyedermodell
-
Das Polytopmodell (oder allgemeiner auch Polyedermodell) ist ein mathematisches Modell, das von Compilern zur Optimierung von Schleifensätzen benutzt werden kann. Dabei werden die Schleifen im Quellprogramm durch Polytope beschrieben, auf die dann eine korrektheitserhaltende Transformation angewandt wird. Im letzten Schritt werden die entstandenen Polytope wieder in (Ziel-)Code übersetzt.
Inhaltsverzeichnis
Aufstellen der Transformationsmatrix
Eine Transformation besteht aus zwei Teilen, dem Schedule und der Allokation. Der Schedule legt fest, wann eine Berechnung stattfinden soll, während die Allokation festlegt, wo die Berechnung erfolgt (d.h. auf welchem Prozessor sie ausgeführt wird).
Berechnung eines gültigen Schedules
Ein Schedule ist gültig, wenn er alle Datenabhängigkeiten erhält.
Wenn eine Iteration mit den Schleifenindices
 , die Ergebnisse der Berechnung
, die Ergebnisse der Berechnung  benötigt, muss für den Schedule t gelten:
benötigt, muss für den Schedule t gelten: 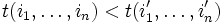 . Das heißt, alle benötigten Werte müssen zu einem früheren Zeitpunkt berechnet worden sein.
. Das heißt, alle benötigten Werte müssen zu einem früheren Zeitpunkt berechnet worden sein.Berechnung einer gültigen Allokation
Im Gegensatz zum Schedule gibt es für die Allokation keine Beschränkungen.
Grundsätzlich besteht immer die Möglichkeit, die Berechnung nur von einem Prozessor durchführen zu lassen. Allerdings verliert man damit alle Parallelität. Deshalb bietet es sich an, die Berechnung auf möglichst viele Prozessoren zu verteilen, um die Parallelität zu maximieren. Dabei muss man allerdings berücksichtigen, dass dadurch mehr Daten zwischen den Prozessoren verschickt werden müssen. Diese zusätzliche Kosten für die Kommunikation können leicht den Gewinn durch die parallele Berechnung überschreiten.
Beispiel (Automatische Parallelisierung)
Vom Quellprogramm zum Polytop
Betrachten wir das folgende Programm, das aus einem perfekt verschachteltem Schleifensatz besteht. Der Rumpf der Schleife enthält ein Statement S.
for i := 0 to n do for j := 0 to i+2 do S: A(i, j) := A(i-1, j) + A(i, j-1) end endUm die Schleife als Polytop darzustellen, genügt es, die oberen und unteren Schranken als Ungleichungen zu schreiben:
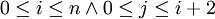
oder in Matrixdarstellung (eine Zeile entspricht einer Ungleichung, Spalten: i, j, n, 1)
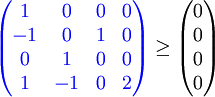
Abhängigkeitsanalyse
In jedem Schleifendurchlauf wird die Arrayzelle
A(i,j)überschrieben. Für die Berechnung vonA(i,j)benötigt man die Werte vonA(i-1,j)undA(i,j-1). Dadurch entstehen zwei Datenabhängigkeiten: Jede Iteration(i,j)hängt sowohl von der Iteration(i-1,j)als auch von(i,j-1)ab. Beide Abhängigkeiten müssen im nächsten Schritt bei der Berechnung des Schedules berücksichtigt werden.Algorithmisch lassen sich alle Abhängigkeiten mithilfe eines Verfahrens zur Abhängigkeitsanalyse berechnen.
Aufstellen der Transformationsmatrix
Ein korrekter Schedule, der beide Abhängigkeiten erhält, ist z.B. t(i,j) = i + j.
Interpretation:
- Im ersten Schritt wird
A(0,0)berechnet - Im zweiten Schritt wird
A(1,0)undA(0,1)berechnet - Im dritten Schritt
A(2,0),A(1,1)undA(0,2) - usw.
Um in jedem Berechungsschritt maximale Parallelität zu ermöglichen, wählen wir als Allokation p(i,j) = i
Dadurch ergibt sich folgende Transformationsmatrix:
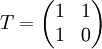
(Erklärung: Erste Zeile = Schedule (i+j), Zweiter Zeile = Allokation (i), Erste Spalte: i, Zweite Spalte: j)
Transformiertes Polytop
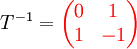
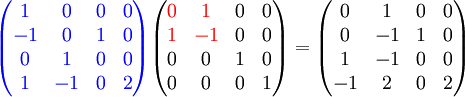
Die Schleifenindices werden ebenfalls durch T − 1 transformiert: i = p und j = t − p
Generierung des Zielprogramms
Der letzte Schritt besteht darin, Code zu generieren, der genau die Punkte aus dem Zielpolyeder aufzählt und dabei die richtige Reihenfolge (genauer die lexikographische Ordnung) einhält. Algorithmisch wird dies von sogenannte Scanning-Algorithmen berechnet (z.B. Fourier-Motzkin Elimination oder dem Verfahren von Quillerè).
Man erhält das folgende (synchrone) Zielprogramm:
for t := 0 to 2n+2 do parfor p := max(0, ceil(t/2)-1) to min(t, n) do A(p, t-p) := A(p-1, t-p) + A(p, t-p-1) end endDie äußere Schleife gibt globale Zeitschritte vor, während die zweite Schleife die parallele Berechnung darstellt. Da in diesem Programm der Code für die Kommunikation zwischen den Prozessoren fehlt, ist es auf Systemen mit verteilten Speicher nicht direkt lauffähig. Allerdings lässt es sich mit gemeinsamen Speicher direkt umsetzten, z.B. als OpenMP Programm.
Anwendung
Zu den wichtigsten Anwendungsmöglichkeiten zählen:
- Cacheoptimierung
- Loop Tiling
- Schleifenparallelisierung
- Im ersten Schritt wird
Wikimedia Foundation.