- Prozessor-Cache
-
Cache [kæʃ] bezeichnet in der EDV eine Methode, um Inhalte, die bereits einmal vorlagen, beim nächsten Zugriff schneller zur Verfügung zu stellen. Caches sind als Puffer-Speicher realisiert, die die Kopien zwischenspeichern. Sie können als Hardware- oder Softwarestruktur ausgebildet sein.
Gründe für den Einsatz eines Caches sind ein (relativ gesehen) langsamer Zugriff auf ein Hintergrund-Medium oder ein relativ hoher Aufwand, oft benötigte Daten neu zu generieren.
Wörtlich aus dem Englischen übersetzt bedeutet Cache (gesprochen käsch, entlehnt vom französischen cacher – verbergen) geheimes Lager. Der Name verdeutlicht den Umstand, dass ein Cache seine Arbeit zumeist im Verborgenen verrichtet. Ein Programmierer muss dessen Größe prinzipiell also nicht kennen, denn der Cache ist als solches abstrakt und wird nicht direkt angesprochen. Praktisch ist er eine gespiegelte Ressource, die stellvertretend für das Original bearbeitet werden kann. Damit alle Geräte auf ein identisches Speicherabbild zugreifen können, ist es notwendig, die Änderungen des Caches in den Hauptspeicher zu übernehmen. Cachestrategien wie Write-Through oder Write-Back sind hier praktikabel. Im Extremfall muss ein kompletter Cache-Flush erfolgen.
Inhaltsverzeichnis
Nutzen
Die Ziele beim Einsatz eines Caches sind eine Verringerung der Zugriffszeit bzw. eine Verringerung der Anzahl der Zugriffe auf den zu cachenden Speicher. Das bedeutet insbesondere, dass sich der Einsatz von Caches nur dort lohnt, wo die Zugriffszeit auch signifikanten Einfluss auf die Gesamtleistung hat. Während das bei den meisten (skalaren) Mikroprozessoren der Fall ist, trifft das z. B. nicht auf Vektorrechner zu, wo die Zugriffszeit keine sehr wichtige Rolle spielt. Deswegen wird dort üblicherweise auch auf Caches verzichtet, weil diese keinen oder nur wenig Nutzen bringen.
Ein weiterer wichtiger Effekt beim Einsatz von Caches ist die verringerte Bandbreitenanforderung an die nächsthöhere Speicherebene der Speicherhierarchie. Dadurch, dass oftmals der Großteil der Anfragen vom Cache beantwortet werden kann (Cache-Hit, s. u.), sinkt die Anzahl der Zugriffe und damit die Bandbreitenanforderung an den zu cachenden Speicher. Ein moderner Mikroprozessor ohne Cache würde selbst mit unendlich kleiner Zugriffszeit des Hauptspeichers dadurch ausgebremst, dass nicht genügend Speicherbandbreite zur Verfügung steht, weil durch den Wegfall des Caches die Anzahl der Zugriffe auf den Hauptspeicher und damit die Anforderung an die Speicherbandbreite stark zunehmen würde. Ein Cache kann daher also auch genutzt werden, um die Bandbreitenanforderungen an den zu cachenden Speicher zu reduzieren, was sich z. B. in geringeren Kosten für diesen niederschlagen kann.
Bei CPUs kann der Einsatz von Caches somit zum Verringern des Von-Neumann-Flaschenhals der Von-Neumann-Architektur beitragen. Die Ausführungsgeschwindigkeit von Programmen kann dadurch im Mittel enorm gesteigert werden.
Ein Nachteil von Caches ist das schlecht vorhersagbare Echtzeitverhalten, da die Ausführungszeit eines Befehls aufgrund von Cache-Misses nicht immer konstant ist.
Cache-Hierarchie
Da es technisch nicht oder nur sehr schwer möglich ist, einen Cache zu bauen, der gleichzeitig sowohl groß als auch schnell ist, kann man mehrere Caches verwenden – z. B. einen kleinen schnellen und einen großen langsameren Cache (der aber immer noch Größenordnungen schneller ist als der zu cachende Speicher). Damit kann man die konkurrierenden Ziele von geringer Zugriffszeit und Cachegröße (wichtig für Hit-Rate) gemeinsam realisieren.
Existieren mehrere Caches, so bilden diese eine Cache-Hierarchie, die Teil der Speicherhierarchie ist. Die einzelnen Caches werden als Level-1 bis Level-n durchnummeriert (kurz: L1, L2 usw.). Die niedrigste Nummer bezeichnet dabei den Cache mit der kleinsten Zugriffszeit – welcher also als erstes durchsucht wird. Enthält der L1 Cache die benötigten Daten nicht, so wird der nächste (meist etwas langsamere, aber größere) Cache (also der L2) durchsucht usw. Das geschieht solange, bis die Daten entweder in einem Cache-Level gefunden oder alle Caches ohne Erfolg durchsucht wurden (Cache Miss, s. u.). In diesem Fall muss auf den verhältnismäßig langsamen Speicher zugegriffen werden.
Moderne CPUs haben meist zwei oder drei Cache-Levels. Mehr als drei ist eher unüblich. Festplatten haben nur einen Cache.
Cache-Größe
Um den Nutzen des meist mehrere Größenordnungen kleineren Caches im Vergleich zum Hintergrundspeicher zu maximieren, werden bei der Funktionsweise und Organisation eines Caches die Lokalitätseigenschaften der Zugriffsmuster ausgenutzt. Beobachtet man die Aktivität eines laufenden Programms über ein kurzes Zeitintervall, so stellt man fest, dass wiederholt auf wenige kleine Speicherbereiche (z. B. Code innerhalb Schleifen, Steuervariablen, lokale Variablen und Prozedurparameter) zugegriffen wird. Darum können bereits kleine Cache-Speicher mit einigen KByte sehr wirksam sein.
Prozessor-Cache
Bei CPUs kann der Cache direkt im Prozessor integriert oder extern auf der Hauptplatine platziert sein. Je nach Ort des Caches arbeitet dieser mit unterschiedlichen Taktfrequenzen: Der L1 ist fast immer direkt im Prozessor integriert und arbeitet daher mit dem vollen Prozessortakt – also u. U. mehrere Gigahertz. Ein externer Cache hingegen wird oftmals nur mit einigen hundert Megahertz getaktet.
Gängige Größen für L1-Caches sind 4 bis 256 KB und für den L2 64 bis 12288 KB.
Moderne Prozessoren haben getrennte L1-Caches für Programme und Daten (Lese- und Schreibcache), teilweise ist das auch noch beim L2 der Fall (Montecito). Man spricht hier von einer Harvard-Cachearchitektur. Das hat den Vorteil, dass man für die unterschiedlichen Zugriffsmuster für das Laden von Programmcode und Daten unterschiedliche Cachedesigns verbauen kann. Außerdem kann man bei getrennten Caches diese räumlich besser zu den jeweiligen Einheiten auf dem Prozessor-Die platzieren und damit die kritischen Pfade beim Prozessorlayout verkürzen. Des Weiteren können Instruktionen und Daten gleichzeitig gelesen/geschrieben werden, wodurch der Von-Neumann-Flaschenhals weiter verringert werden kann. Ein Nachteil ist, dass selbstmodifizierender Code nicht sehr gut auf modernen Prozessoren läuft. Allerdings wird diese Technik heute ohnehin nur noch sehr selten verwendet.
Festplatten-Cache
Bei Festplatten befindet sich der Cache auf der Steuerplatine und ist 1–64 MB groß. Für mehr Informationen siehe auch Festplattencache.
Lokalitätsausnutzung
Caches sollen schnell sein. Um das zu erreichen, verwendet man für den Cache meist eine andere (schnellere) Speichertechnologie als für den zu cachenden Speicher (SRAM ggü. DRAM, DRAM ggü. Magnetscheibe etc.). Daher sind Caches meist wesentlich teurer in Bezug auf das Preis/Bit Verhältnis, weswegen Caches deutlich kleiner ausgelegt werden. Das führt dazu, dass ein Cache nicht alle Daten gleichzeitig vorrätig haben kann. Um das Problem zu lösen, welche Daten denn nun im Cache gehalten werden sollen, werden Lokalitätseigenschaften der Zugriffe ausgenutzt:
- zeitliche (temporale) Lokalität: Da sich Zugriffe auf Daten wiederholen (z. B. beim Abarbeiten einer Programmschleife), ist es eher wahrscheinlich, dass auf Daten, auf die schon einmal zugegriffen wurde, auch noch ein weiteres Mal zugegriffen wird. Diese Daten sollten also bevorzugt im Cache gehalten werden. Dadurch ergibt sich auch eine Notwendigkeit, alte Daten, die lange nicht benutzt wurden, aus dem Cache zu entfernen, um Platz für neuere zu machen. Diesen Vorgang nennt man auch „Verdrängung“.
- räumliche (spatiale) Lokalität: Da Programmcode und -daten nicht wild verstreut im Adressraum herumliegen, sondern „hintereinander“ und teilweise auch nur in bestimmten Adressbereichen angeordnet sind (Code-, Daten-, Stack-Segment, Heap etc.) ist es bei einem stattgefundenen Zugriff auf eine bestimmte Adresse wahrscheinlich, dass auch auf eine „naheliegende“ Adresse (sprich: Betrag der Differenz der beiden Adressen sehr klein) zugegriffen wird. Bei der Abarbeitung eines Programms wird z. B. ein Befehl nach dem anderen abgearbeitet, wobei diese „nacheinander“ im Speicher liegen (wenn es kein Sprung ist). Viele Datenstrukturen wie Arrays liegen ebenfalls „hintereinander“ im Speicher.
Die räumliche Lokalität ist der Grund, warum man bei Caches nicht einzelne Bytes, sondern die Daten ganzer Adressbereiche („Cache-Block“ oder manchmal auch „Cache-Line“ genannt) speichert. Zusätzlich dazu erleichtert es die Implementation, weil man nicht für jedes Byte Daten dessen Adresse im Speicher festhalten muss, sondern nur für jeden Cache-Block (der aus vielen Bytes besteht). Die Wahl der Blockgröße ist ein wichtiger Designparameter für einen Cache, der die Leistung – positiv wie auch negativ – stark beeinflussen kann.
Organisation
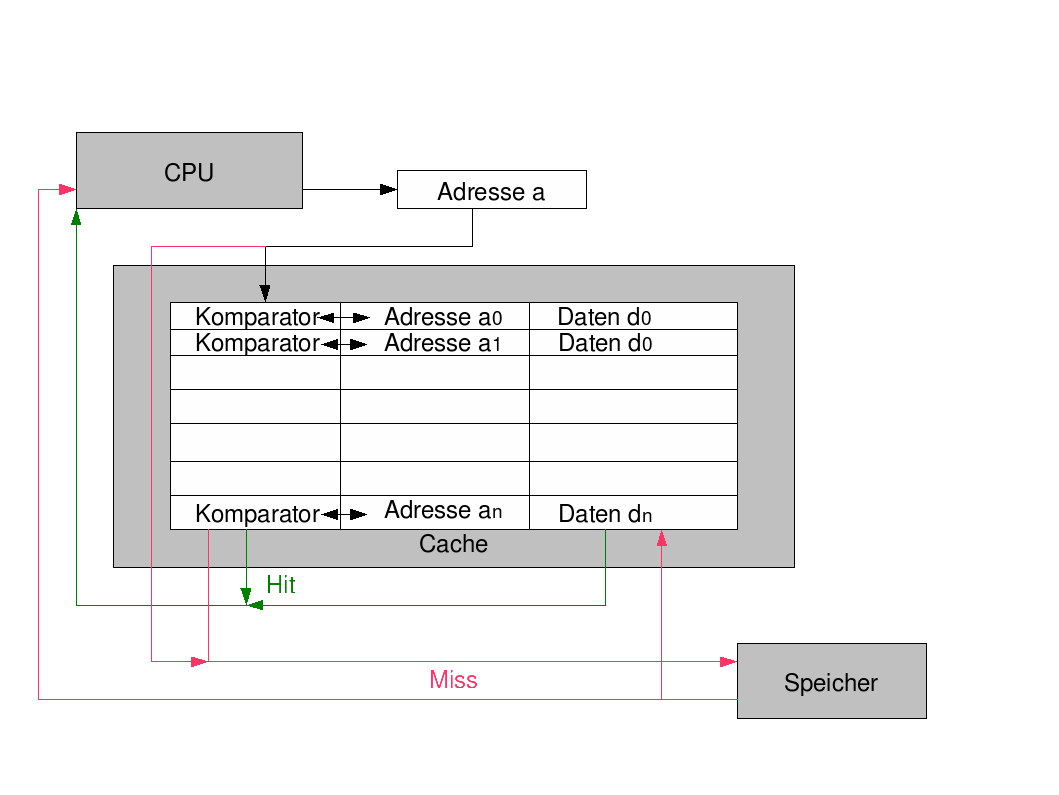 Vollassoziativer Cache
Vollassoziativer CacheEs existieren drei Möglichkeiten der Cacheorganisation: Direkt abgebildet (direct mapped, abgekürzt mit DM), Vollassoziativ (fully associative, FA) und Satzassoziativ (SA, manchmal auch „Mengenassoziativ“ (set associative) genannt). Die ersten beiden sind ein Spezialfall des satzassoziativen Cache.
- Direct mapped: Für eine gegebene Adresse gibt es nur eine Möglichkeit bzw. Cache-Block, in dem sich die Daten befinden können. (Abbildung von Adresse auf genau einen Cacheblock, daher der Name „direkt abgebildet“). Dadurch muss man bei einer Anfrage an den Cache auch nur für einen Cache-Block „nachschauen“ (d. h. den zugehörigen Tag überprüfen, s. u.). Das minimiert den Hardwareaufwand für die Tag-Vergleicher (Komparatoren; engl. compare vergleichen).
- Fully associative: Hier können sich die Daten einer Adresse in jedem beliebigen Block im Cache befinden. Bei einer Anfrage an den Cache ist es daher notwendig, alle Tags des Caches zu überprüfen. Da Caches möglichst schnell sein müssen, wird das parallel ausgeführt, was den notwendigen Hardwareaufwand an Komparatoren (Tag-Vergleichern) vergrößert.
- Set associative: Hier werden n direkt zuordnende Caches vollassoziativ (also frei) angewählt. Diesen Cache nennt man dann n-fach satzassoziativ (oder kurz: n-fach assoziativ). Der direkt abgebildete und der vollassoziative Cache lassen sich somit vom satzassoziativen Cache ableiten (n=1 für direkt abgebildeten bzw. n=Anzahl der Cachezeilen für vollassoziativen Cache).
Eine kleine Übersicht der drei Typen: Hierzu sei m die Anzahl der Cache-Blocks und n die Assoziativität des Caches.
Typ Anzahl Sätze Assoziativität DM m 1 FA 1 m bzw. n SA m/n n Ein DM-Cache ist somit ein SA-Cache mit einer Assoziativität von Eins und so vielen Sätzen wie Cache-Blocks vorhanden sind. Ein FA-Cache ist ein SA-Cache mit einer so großen Assoziativität wie Cache-Blocks vorhanden sind und nur einem Satz.
Cache-Hit, Cache-Miss
Den Vorgang, dass die Daten einer Anfrage an einen Cache in selbigem vorrätig sind, bezeichnet man als „Cache-Hit“ (dt.: Cache-Treffer), den umgekehrten Fall als „Cache-Miss“ (dt.: „Cache-Verfehlen“).
Um quantitative Maßzahlen für die Bewertung der Effizienz eines Caches zu erhalten, definiert man zwei Größen:
- Hit-Rate: Die Anzahl der Anfragen, bei denen ein Cache-Hit auftrat geteilt durch die Anzahl der insgesamt an diesen Cache gestellten Anfragen. Wie man aus der Definition leicht sehen kann, liegt diese Größe zwischen Null und Eins. Eine Hitrate von z. B. 0,7 (oder auch 70 %) bedeutet, dass bei 70 % aller Anfragen an den Cache dieser die Daten sofort liefern konnte und bei 30 % aller Anfragen passen musste.
- Analog dazu ist die Miss-Rate definiert. Das ist die Anzahl der Anfragen, bei denen die Daten nicht im Cache vorhanden waren geteilt durch die Anzahl der gesamten Anfragen. Es gilt: Missrate = 1 − Hitrate.
Dabei werden drei Arten von Cache-Misses unterschieden:
- Capacity: Der Cache ist zu klein. Daten waren im Cache vorrätig, wurden aber wieder aus dem Cache entfernt. Erfolgt dann ein erneuter Zugriff auf diese Adresse, so wird dieser Miss als „Capacity-Miss“ bezeichnet. Abhilfe schafft nur ein größerer Cache.
- Conflict: Durch die satz-assoziative Organisation (gilt somit auch für DM-Caches) ist es möglich, dass in einem Satz nicht mehr genug Platz ist, während in anderen Sätzen noch freie Cache-Blocks vorhanden sind. Dann muss in dem überfüllten Satz ein Block entfernt werden, obwohl der Cache eigentlich noch Platz hat. Wird auf diesen entfernten Block erneut zugegriffen, so bezeichnet man diesen Cache Miss als „Conflict-Miss“. Abhilfe schafft eine Erhöhung der Cache-Blocks pro Satz – also eine Erhöhung der Assoziativität. Bei vollassoziativen Caches (welche nur einen Satz haben) gibt es somit keine Conflict-Misses.
- Compulsory: Beim erstmaligen Zugriff auf eine Adresse befinden sich normalerweise die dazugehörigen Daten noch nicht im Cache. Diesen Miss bezeichnet man als „Compulsory Miss“. Er ist nicht oder nur schwer zu verhindern. Moderne Prozessoren besitzen eine Einheit namens „Prefetcher“, welche selbstständig spekulativ Daten in die Caches laden, wenn dort noch Platz ist. Damit wird probiert die Anzahl der Compulsory-Misses zu verringern.
Diese drei Typen bezeichnet man auch kurz als „Die drei C“. In Multiprozessorsystemen kann beim Einsatz eines Cache-Kohärenz-Protokolls vom Typ Write-Invalidate noch ein viertes „C“ hinzukommen, nämlich ein Kohärenz-Miss (engl.: „Coherency Miss“). Wenn durch das Schreiben eines Prozessors in einen Cache-Block der gleiche Block im Cache eines zweiten Prozessors hinausgeworfen werden muss, so führt der Zugriff des zweiten Prozessors auf eine Adresse, die durch diesen entfernten Cache-Block abgedeckt war, zu einem Miss, den man als Kohärenz-Miss bezeichnet.
Arbeitsweise
Bei der Verwaltung des Caches ist es sinnvoll, immer nur die Blöcke im Cache zu halten, auf die auch häufig zugegriffen wird. Zu diesem Zweck gibt es verschiedene Ersetzungsstrategien. Eine häufig verwendete Variante ist dabei die LRU-Strategie (engl. least recently used), welche immer den am längsten nicht mehr zugegriffenen Block im Cache austauscht. Moderne Prozessoren (AMD Athlon u. v. m.) implementieren meist eine Pseudo-LRU-Ersetzungsstrategie, die also fast wie echtes LRU arbeitet, aber leichter in Hardware zu implementieren ist.
Verdrängungsstrategien
- FIFO (First In First Out): Der jeweils älteste Eintrag wird verdrängt.
- LRU (Least Recently Used): Der Eintrag, auf den am längsten nicht zugegriffen wurde, wird verdrängt.
- LFU (Least Frequently Used): Der am wenigsten gelesene Eintrag wird verdrängt. Dabei werden jedoch keineswegs vollständige Zeitstempel gespeichert, die eine relativ lange Integer-Zahl erfordern würden. Vielmehr werden wenige Bits (zwei sind häufig, aber auch nur eines ist möglich), um einen Cache-Eintrag als mehr oder weniger häufig benutzt zu markieren. Die Aktualisierung der Bits erfolgt parallel zu einer Verdrängung.
- Random: Ein zufälliger Eintrag wird verdrängt.
- Climb: Bei der Climb-Strategie wird eine neue Seite stets unten im Speicher eingesetzt und steigt bei jedem Zugriff eine Ebene nach oben. Muss eine Seite ausgetauscht werden, so wird die unterste Seite ersetzt.
- CLOCK: Wenn auf ein Datum zugegriffen wird, wird ein Bit gesetzt. Die Daten werden in der Reihenfolge des Zugriffs abgelegt. Bei einem Miss wird in dieser Reihenfolge nach einem Datum ohne gesetztes Bit gesucht, das wird ersetzt. Bei allen dabei gesehenen Daten wird das Bit gelöscht. Es wird ebenfalls markiert, welches Datum zuletzt in den Cache geladen wurde. Von da beginnt die Suche nach einem Datum, welches ersetzt werden kann.
- Optimal: Das Verfahren von Laszlo Belady, bei dem derjenige Speicherbereich verdrängt wird, auf den am längsten nicht zugegriffen werden wird, ist optimal. Es ist allerdings nur dann anwendbar, wenn der komplette Programmablauf im voraus bekannt ist (d. h. er ist ein so genanntes Offline-Verfahren, im Gegensatz zu FIFO und LRU, die Online-Verfahren sind). Der Programmablauf ist aber fast nie im voraus bekannt; deshalb kann das optimale Verfahren in der Praxis nicht eingesetzt werden. Allerdings kann der optimale Algorithmus als Vergleich für andere Verfahren dienen.
Schreibstrategie
Bei einem Schreibzugriff auf einen Block, der im Cache vorhanden ist, gibt es prinzipiell zwei Möglichkeiten:
- Zurückkopieren (write-back)
- Beim Schreiben wird der zu schreibende Block nicht sofort in der nächsthöheren Speicherebene abgelegt, sondern zunächst im Cache. Dabei entsteht eine Inkonsistenz zwischen Cache und zu cachendem Speicher. Letzterer enthält somit veraltete Information. Erst wenn das Wort aus dem Cache verdrängt wird, wird es auch in die nächsthöhere Speicherebene geschrieben. Dazu bekommt jeder Cacheblock ein dirty bit, welches anzeigt, ob der Block beim Ersetzen zurückkopiert werden muss. Das führt bei Speicherzugriff durch andere Prozessoren oder DMA-Geräte zu Problemen, weil diese veraltete Informationen lesen würden. Abhilfe schaffen hier Cache-Kohärenz-Protokolle, wie z. B. MESI für UMA-Systeme.
- Durchgängiges Schreiben (write-through)
- Der zu schreibende Block wird sofort in der nächsthöheren Speicherebene abgelegt. Damit ist die Konsistenz gesichert. Damit der Prozessor nicht jedes Mal warten muss bis der Block in der nächsthöheren Speicherebene (die ja langsamer als der Cache ist) abgelegt ist benutzt man einen Pufferspeicher (write-buffer). Wenn dieser voll läuft, muss der Prozessor jedoch anhalten und warten.
Analog zu Obigem gibt es bei einem Schreibzugriff auf einen Block, der nicht im Cache vorhanden ist, prinzipiell ebenso zwei Möglichkeiten:
- write-allocate
- Wie bei einem normalen Cache-Miss wird der Block aus der nächsthöheren Speicherebene geholt. Die entsprechenden Bytes, die durch den Schreibzugriff geändert wurden, werden danach im gerade frisch eingetroffenen Block überschrieben.
- non-write-allocate
- Es wird am Cache vorbei in die nächsthöhere Speicherebene geschrieben, ohne dass der dazugehörige Block in den Cache geladen wird. Das kann für manche Anwendungen Vorteile bringen, bei denen viele geschriebene Daten nie wieder gelesen werden. Durch die Verwendung von non-write-allocate verhindert man das Verdrängen von anderen, möglicherweise wichtigen Blöcken und reduziert somit die miss-rate.
Einige Befehlssätze enthalten Befehle, die es ermöglichen am Cache vorbeizuschreiben.
Normalerweise wird entweder die Kombination write-back mit write-allocate oder write-through mit non-write-allocate verwendet. Die erste Kombination hat den Vorteil, dass aufeinander folgende Schreibzugriffe auf denselben Block (Lokalitätsprinzip) komplett im Cache abgewickelt werden (bis auf den ersten Miss). Dies gibt im 2. Fall keinen Vorteil, da sowieso jeder Schreibzugriff zum Hauptspeicher muss, weshalb die Kombination write-through mit write-allocate eher unüblich ist. [1]
Cache-Flush
Ein Cache-Flush („Pufferspeicher-Spülen“) bewirkt das komplette Zurückschreiben des Cache-Inhaltes in den Hauptspeicher. Dabei bleibt der Cache-Inhalt meist unangetastet. Ein solches Vorgehen ist nötig, wenn man die Cache-Hauptspeicher-Konsistenz wiederherstellen möchte.
Notwendig ist das immer dann, wenn die Daten von externer Hardware benötigt werden. Beispiele: Multiprozessor-Kommunikation; Übergabe eines als Ausgabepuffer benutzten Teils des Hauptspeichers an den DMA-Controller; Hardware-Register (so genannter Ein-/Ausgabebereich oder I/O-Bereich) – wobei letztere normalerweise gar nicht als zwischenspeicherbar eingestuft werden, d. h. bei ihrem Zugriff wird der Cache umgangen.
Sonstiges
Einträge im Cache
Für jeden Cache-Block wird im Cache folgendes gespeichert:
- die eigentlichen Daten
- der Tag (Rest der Adresse)
- mehrere Status-Bits wie:
- modified (wird auch manchmal als „dirty“ bezeichnet): Gibt an, ob dieser Cacheblock geändert wurde (nur bei write-back Cache)
- diverse Statusbits je nach Cache-Kohärenz-Protokoll. Also z. B. je ein Bit für:
- owner: Äquivalent zu „modified & shared“. Gibt an, dass der Block geändert wurde und in anderen Caches vorhanden ist. Der Owner ist dafür verantwortlich, den Hauptspeicher upzudaten, wenn er den Block aus seinem Cache entfernt. Derjenige Prozessor, der zuletzt auf den Cacheblock schreibt, wird neuer Owner.
- exclusive: Gibt an, dass der Block nicht geändert wurde und in keinem anderen Cache vorhanden ist.
- shared: Hat teilweise unterschiedliche Bedeutungen: Bei MESI gibt das an, dass der Block nicht geändert wurde, aber auch in Caches anderer Prozessoren vorhanden ist (dort ebenso nicht verändert). Bei MOESI bedeutet es nur, dass der Block in anderen Prozessorcaches vorhanden ist. Hier ist auch erlaubt, dass der Block verändert wurde, also inkonsistent zum Hauptspeicher ist. In diesem Fall gibt es aber einen „Owner“ (s. u.), der für das Updaten des Hauptspeichers verantwortlich ist.
- uvm.
- invalid: zeigt an, ob dieser Block frei oder belegt ist.
Heiße und kalte Caches
Ein Cache ist „heiß“, wenn er optimal arbeitet (sprich: gefüllt ist und nur wenige Cache-Misses hat), und „kalt“, wenn er das nicht tut. Ein Cache ist nach Inbetriebnahme zunächst kalt, da er noch keine Daten enthält und häufig zeitraubend Daten nachladen muss, und wärmt sich dann zunehmend auf, da die zwischengelagerten Daten immer mehr den angeforderten entsprechen und wenig Nachladen mehr erforderlich ist. Im Idealzustand werden Datenzugriffe fast ausschließlich aus dem Cache bedient, und das Nachladen kann vernachlässigt werden.
Software-Caches
Das Wort „Cache“ trifft man auch in der Software an. Hier beschreibt es dasselbe Prinzip wie bei der Hardwareimplementierung: Daten werden für einen schnelleren Zugriff auf ein schnelleres Medium zwischengespeichert.
Beispiele:
- Browser-Cache: (Netz → Festplatte)
- Anwendungen: (Festplatte → Hauptspeicher)
- Webanwendungen: (Datenbank → HTML-Datei)
Software-Caches werden meist im Form von temporären Dateien angelegt.
Man spricht auch von Caching, wenn ein Betriebssystem gewisse Ressourcen – wie z. B. Funktionsbibliotheken oder Schriftarten – vorerst im Arbeitsspeicher belässt, obwohl sie nach Ende ihrer Benutzung nicht mehr gebraucht werden. So lange kein Speichermangel herrscht, können sie im Arbeitsspeicher verbleiben, um dann ohne Nachladen von der Festplatte sofort zur Verfügung zu stehen, wenn sie wieder gebraucht werden. Wenn allerdings die Speicherverwaltung des Betriebssystems einen Speichermangel feststellt, werden diese Ressourcen als erste gelöscht.
Einzelnachweise
- ↑ John Hennessy, David Patterson: Computer Architecture. A Quantitative Approach., 4th Edition, Morgan Kaufmann Publishers, ISBN 978-0-12-370490-0 (engl.), S. C-11 - C-12
Weblinks
Wikimedia Foundation.