- RFC 3066
-
ISO 639 ist ein internationaler Standard der Internationalen Organisation für Normung, der Kennungen für Namen von Sprachen (Sprachcodes) definiert. Der Standard besteht aus mehreren Teilnormen. Vier Teile für Kennungen mit zwei Buchstaben (ISO 639-1) und drei Buchstaben (ISO 639-2, ISO 639-3 und ISO 639-5) sind bereits verabschiedet und werden weitläufig verwendet; mit ISO 639-4 und 6 sind zwei weitere Teile in Entwicklung (Stand: Juni 2008).
Inhaltsverzeichnis
Anwendung
Die in der Norm definierten Kennungen werden unter anderem in der Lexikographie, Linguistik, in Bibliotheken, Informationsdiensten und im Datenaustausch verwendet. Sie dienen zur eindeutigen Angabe von Sprachen und ihrer Kennzeichnung in Dokumenten. Sie wurden nicht als Abkürzungen eingeführt[1], da unter anderem eine Ähnlichkeit mit der bezeichneten Sprache nicht in jedem Fall gegeben ist.
Eine Verwendung kann beliebig in Groß- und Kleinschreibung erfolgen, doch gibt es darauf aufbauende Normen, die eine gewisse Schreibung festlegen.
Die Sprachcodes dieser Norm umfassen natürliche Sprachen und Plansprachen, aber keine Sprachen, die für die maschinelle Verarbeitung erstellt wurden, wie z. B. Programmiersprachen.
Teilnormen
Die offiziell eingeführten Teilnormen sind[2]:
- ISO 639-1:2002 − Codes for the representation of names of languages − Part 1: Alpha-2 code
- ISO 639-2:1998 − Codes for the representation of names of languages − Part 2: Alpha-3 code
- ISO 639-3:2007 − Codes for the representation of names of languages − Part 3: Alpha-3 code for comprehensive coverage of languages
- ISO 639-5:2008 − Codes for the representation of names of languages − Part 5: Alpha-3 code for language families and groups
Weitere Teile befinden sich derzeit noch in Entwicklung:
- ISO 639-4 − Codes for the representation of names of languages − Part 4: Implementation guidelines and general principles for language coding
- ISO 639-6 − Codes for the representation of names of languages − Part 6: Alpha-4 representation for comprehensive coverage of language variation

ISO 639-1
Der Teilstandard ISO 639-1 wurde für den Einsatz in Terminologie, Lexikographie und Linguistik erstellt. Bis zu seiner offiziellen Verabschiedung 2002 wurde er unter dem Namen ISO 639 geführt. Vorläufer sind die Request for Comments RFC 1766 (März 1995) und RFC 3066 (Januar 2001). ISO 639-1 soll nicht nur die in der Literatur am meisten verbreiteten Sprachen abdecken, sondern auch die am weitesten „entwickelten“ Sprachen mit einem „spezialisierten“ Vokabular aufnehmen[1]. Dabei werden nicht nur Einzelsprachen, sondern auch Sprachfamilien aufgenommen. Jede Sprache wird durch eine Kennung aus zwei Buchstaben repräsentiert (Alpha-2 Code). Zum Beispiel steht
defür die deutsche Sprache oderfrfür die französische Sprache. Insgesamt sind durch Nutzung der 26 lateinischen Buchstaben 262 = 676 verschiedene Kennungen möglich, von denen 185 belegt sind (Stand: Januar 2007[3]). Verwaltet wird die Norm von dem durch die UNESCO gegründeten International Information Center for Terminology (Infoterm)[4].Aufnahmen weiterer Sprachcodes sind vorgesehen, jedoch nur für Kennungen, die gleichzeitig der ISO 639-2-Norm hinzugefügt werden. Für bereits bestehende Einträge der ISO 639-2 werden keine zwei-Buchstaben-Kennungen mehr vergeben. Dies soll Kompatibilität gewährleisten[5].
ISO 639-2
Die spätere Norm ISO 639-2 erweitert die ISO 639-1 durch eine größere Menge an Sprachen. Jeder in ISO 639-1 definierte Sprachcode findet sich mit einem Code aus drei Buchstaben auch in diesem Standard wieder (Alpha-3 Code).
Für die zweite Norm der ISO 639 wurde die Kennung auf drei Buchstaben erweitert, so dass theoretisch 263 = 17.576 Sprachcodes möglich sind. Bislang sind mehr als 480 (Stand: Januar 2007 [3]) Kennungen für Einzelsprachen und Sprachfamilien aufgenommen. Ziel der Norm ist der Einsatz in „Terminologie und Bibliographie“, um unter Anderem den Bedürfnissen des Bibliothekswesen nachzukommen und eine möglichst weite Auszeichnung von Werken der Welt zu ermöglichen. Aufgenommen wurden Sprachen, für die eine als geeignet empfundene Menge an Literatur herausgegeben wurde. Da der Schwerpunkt auf der geschriebenen Sprache liegt, wurde auf eine Unterscheidung von Sprachen verzichtet, die in der geschriebenen Form zwar große Übereinstimmungen besitzen, doch in ihrer gesprochenen Form abweichen. So gibt es zum Beispiel keine Unterscheidung für die chinesischen Sprachen wie Hochchinesisch und Kantonesisch[1].
Die US-amerikanische Library of Congress übernimmt die Pflege dieser Teilnorm[3].
Der Standard ISO 639-2 erweitert ISO 639-1 und führt alle dortigen Sprachcodes. Die Kennungen aus zwei Buchstaben werden in dieser Norm mit drei Buchstaben fortgesetzt, wobei weitestgehend für die jeweilige Kennung lediglich ein weiterer Buchstabe hinzugenommen und eine Ähnlichkeit damit gewährleistet wird (siehe unten für den Spezialfall der Kennungen ISO 639-2/B)[6]. Die Basis für die Sprachcodes dieser Norm war die MARC Code List for Languages[7], die seit 1968 verwendet und ebenfalls von der Library of Congress verwaltet wurde.
Unter den hinzugekommenen Kennungen sind historische Sprachen wie Mittelhochdeutsch (
gmhfür German, Middle High) oder Althochdeutsch (gohfür German, Old High).Kollektive Sprachcodes
Eine Besonderheit sind kollektive Sprachcodes (englisch collective language codes), die in der Norm ISO 639-1 nicht vorgesehen sind. Sie ermöglichen eine Kennzeichnung von Gruppen von Sprachen, für die eine Zuordnung von Kennungen zu den einzelnen Sprachen nicht vorgesehen ist. Dies kann für kleine Sprachen erfolgen, für die lediglich eine geringe Zahl an literarischen Werken vorhanden ist oder für die keine erhebliche Zunahme derer angenommen wird. Sie fassen einerseits Sprachfamilien zusammen wie die Irokesischen Sprachen unter der Kennung
irooder bieten eine Sammelbezeichnung für alle übrigen Einzelsprachen einer Familie, bei der einzelne zugehörige Sprachen einen eigenen Eintrag besitzen. Dies ist der Fall bei der Familie der samischen Sprachen (Kennungsmifür sonstige), bei der die zugehörige nordsamische Sprache bereits eine eigene Kennung besitzt (sme). In der Tabelle der Sprachcodes wird für erstere Gruppen in der Regel der Bezeichner languages (deutsch „Sprachen“), für letztere der Bezeichner (other) (deutsch „andere“) an den Namen angehängt, um kollektive Sprachcodes auszuzeichnen. Ist ein Sprachcode für eine einzelne Sprache verfügbar, soll dieser vorgezogen werden und keine Zuordnung eines kollektiven Codes erfolgen. Dies kann auch Sprachcodes betreffen, die neu in den Standard aufgenommen werden.Eine Beschreibung für die Zuordnung von Einzelsprachen (ohne eigenen Eintrag) zu einer der durch ISO 639-2 angebotenen kollektiven Sprachcodes findet sich nicht in dem Standard. Die Library of Congress verweist allerdings auf die oben genannte Liste der MARC Code List for Languages, die diese Funktion erfüllen kann.
Terminologische und bibliographische Sprachcodes (T/B)
Ein weiterer Unterschied zu ISO 639-1 und auch den anderen Teilnormen ist die Verwendung terminologischer (terminology code) und bibliographischer Kennungen (bibliographic code), die mit ISO 639-2/T und ISO 639-2/B bezeichnet werden. Diese Unterscheidung wird für 22 Einträge gemacht[8] und rührt weitestgehend daher, dass vor Einsatz der Norm bereits Konventionen im Bibliothekswesen für Drei-Buchstaben-Kennungen bestanden, die von der Benennung der bereits festgelegten Norm ISO 639-1 für zwei Buchstaben stark abwichen. Die deutsche Sprache gehört zu diesen Fällen, ihr B-Code ist ger, der T-Code deu.
Da in der Benennung eine Fortführung der ISO 639-1 angestrebt wurde, ist in den Fällen abweichender Bezeichner entschieden worden zwei Codes einzuführen. Die terminologische Kennung führt also die Benennung nach ISO 639-1 weiter, während die bibliographische Kennung aus Kompatibilitätsgründen geführt wird und die vorherige, weitläufige Benennung reflektiert. Der Standard erlaubt die Mischung von T- und B-Codes nicht und mahnt eine Festlegung der verwendeten Art vor dem Datenaustausch durch die betroffenen Parteien an.
Änderungen
Ein Hinzufügen und Ändern von Sprachcodes sowie das Ändern ihrer Beschreibung ist möglich, dabei wird auf Stabilität im beschriebenen Standard geachtet. Sprachcodes nach ISO 639-2/B, die nun Kompatibilität gewährleisten sollen, sind von Änderungen jedoch ausgeschlossen. Ein nach Änderungen aufgegebener Code soll frühestens nach fünf Jahren wiederverwendet werden.
ISO 639-3
Die Norm ISO 639-3 wurde am 5. Februar 2007 herausgegeben[9] und soll aufbauend auf die ersten beiden Teilnormen eine umfassende Abdeckung aller Sprachen der Welt ermöglichen. Die Kennungen aus drei Buchstaben aus der vorhergehenden Norm ISO 639-2 werden weitergeführt und somit kann auch ISO 639-3 theoretisch über 17.576 verschiedene Kennungen verfügen (praktisch unter anderem dadurch begrenzt, dass ISO 639-5 ebenfalls Alpha-3-Codes aufnimmt, die disjunkt zu denen aus ISO 639-3 sind). Aufgenommen werden alle bekannten Sprachen, worunter auch alle lebendigen, ausgestorbenen, historischen sowie auch konstruierten Sprachen fallen. Mehr als 6.900 Sprachen sind bisher in den Standard aufgenommen worden. Gedacht ist die komplette Liste vor allem für den Einsatz in der Informationstechnologie, wo eine komplette Auflistung aller Sprachen wünschenswert ist[10]. Darunter sind auch Einträge wie für die Alemannischen Dialekte (gsw), Kölsch (ksh) und die Bairischen Dialekte (bar).
Verwaltet wird sie von der Organisation SIL International, die mit dem Ethnologue bereits lebendige Sprachen (mit Ausnahmen[11]) und Sprachcodes erfasst. In der 15. Ausgabe des Ethnologue wurden die bisherig von SIL vergebenen Codes an jene von ISO 639-2 angepasst, um Konformität zu ermöglichen. Weitere historische und künstliche Sprachen stammen von Linguist List[2].
Bis auf bibliographische Kennungen (ISO 639-2/B) finden sich alle Kennungen für Einzelsprachen der ISO 639-2 in dieser Norm wieder. Kollektive Sprachkennungen werden nicht geführt. Die Codes mit drei Buchstaben sind im ganzen Standard eindeutig gehalten, so dass die Bezeichner von bibliographischen und kollektiven Kennungen in ISO 639-3 nicht neu belegt werden können[10].
Makrosprachen
Eine Erweiterung ist der Gebrauch so genannter Makrosprachen (engl. macrolanguage, als Dachsprache, nicht zu verwechseln mit Makrofamilien). Dabei werden mehrere Einzelsprachen in einem Eintrag subsumiert, wie z. B. die chinesischen Sprachen im Eintrag
zho, der unter anderem die Einzelsprachen Hochchinesisch, Hakka, Min Nan und Wu enthält. Formal werden die mehr als 50 Makrosprachen[12] in den Normen ISO 639-1 (wenn erfasst) und -2 als Einzelsprachen geführt.Im Gegensatz zu Sprachen, die über kollektive Sprachcodes repräsentiert werden, sollen Makrosprachen Einzelsprachen zusammenfassen, wenn unter bestimmten Gesichtspunkten die Betrachtung dieser Sprachen als eine einzelne notwendig erscheint. Dazu gibt die Registrierungsstelle Beispiele an[13]:
- es existiert eine einzelne hochentwickelte Sprache, die von Sprechern verwandter Sprachen verwendet wird, unter dem Eindruck einer gemeinsamen Identität (arabische Sprache),
- es existiert eine gemeinsame geschriebene Form (chinesische Sprachen mit der chinesischen Schrift) oder
- verschiedene Gruppen entwickeln sich getrennt, so dass eine eindeutige Kennzeichnung nötig ist, eine gemeinsame Identität aber noch existiert (Kroatische, Serbische, Bosnische Sprache).
Makrosprachen können als Konzept die verschiedenen Ansätze der Teilnormen -2 und -3 zusammenbringen. Ein einzelner Eintrag aus ISO 639-2, der mehrere Einträge aus ISO 639-3 subsumiert, wird so in das Gefüge der dritten Teilnorm eingefügt.[14] Jeder Makrosprachcode hat ein Äquivalent in ISO 639-2 mit Ausnahme der Serbokroatischen Sprache (Stand: August 2007), die ursprünglich über einen nun obsoleten Eintrag in ISO 639-1 verfügte.
Einige Einzelsprachen, die in Makrosprachen zusammengefasst werden, besitzen auch eigene Einträge in den Normen ISO 639-1 oder -2. So fungiert die Norwegische Sprache mit dem Code
norals Makrosprache, die beinhalteten Sprachen Bokmål (nb,nob) und Nynorsk (nn,nno) haben aber auch entsprechende Einträge in den anderen Normen.Bei der Zusammenfassung in Makrosprachen kann es wie bei der malaiischen Sprache zu Namenskonflikten kommen. Während der Code
mlydie Einzelsprache bezeichnet, stehtmsafür die den Eintrag des Malaiischen als Makrosprache. Um Verwechselungen auszuschließen, erhalten die Benennungen dieser Einträge einen qualifizierenden Zusatz in der Auflistung der Kennungen.ISO 639-4
Eine Erklärung zur Anwendung der Normen aus ISO 639 wird sich in dem Standard ISO 639-4 finden, der noch nicht erschienen ist. Diese Norm selbst wird keine Sprachcodes definieren[15]. Die Veröffentlichung ist für den 30. November 2008 angekündigt[16].
ISO 639-5
Eine Erweiterung der kollektiven Kennungen aus ISO 639-2 bietet ISO 639-5, die am 15. Mai 2008 herausgegeben wurde. Dabei wurden die bereits vorhanden Kennungen aus ISO 639-2 aufgenommen. Dieser Teilstandard teilt keine Sprachcodes mit ISO 639-3, die Mengen der geführten Kennungen sind disjunkt[15].
Diese Teilnorm bietet eine Hierarchie von Sprachfamilien und erlaubt eine Strukturierung der Codes aus den Teilnormen 1-3. Dies ermöglicht eine unterschiedliche Abstufung in der Generalisierung zur Auszeichnung von Sprachdaten.
ISO 639-6
Die noch in Arbeit befindliche Norm ISO 639-6 wird vier-buchstabige Codes definieren (alpha-4) und eine Erweiterung der Sprachcodes aus den Teilen 1-3 bieten.
Integration und Beziehungen der einzelnen Normen
Die in den verschiedenen Teilnormen definierten Sprachcodes spielen zusammen und erlauben eine Auszeichnung mit unterschiedlicher Granularität. Diese Integration wird erst mit Veröffentlichung der Normen ISO 639-4 und ISO 639-6 abgeschlossen sein.
Die Normen der ISO 639 stehen in unterschiedlicher Beziehung zueinander. ISO 639-3 definiert die Menge aller Einzelsprachen (ergänzt durch die Makrocodes), während Teil 5 eine Hierarchie aus Sprachfamilien definiert. Diese klar abgegrenzten Mengen finden sich zum Teil in den beiden älteren Teilnormen -1 und -2 und deren Elemente werden dort unstrukturiert nebeneinander gestellt. ISO 639-1 stellt eine Teilmenge von Teil 2 dar, da dort stärkere Kriterien für eine Aufnahme als zwei-buchstabige Codes existieren.
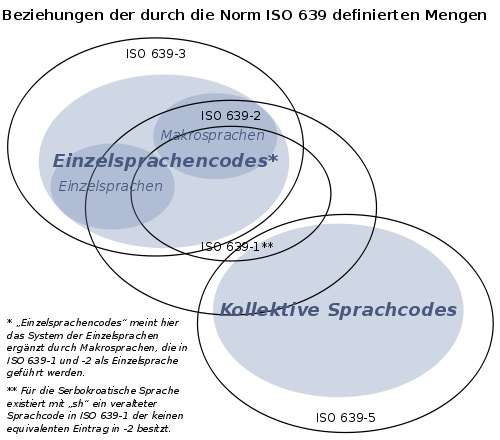 Darstellung der durch die Teilnormen definierten Mengenbeziehungen.
Darstellung der durch die Teilnormen definierten Mengenbeziehungen.Verwaltung
Die Verwaltung der Kennungslisten übernehmen ausgewählte Registrierungsstellen (Registration Authorities), deren Aufgabe in der Annahme und Prüfung der Anfragen zur Aufnahme neuer Kennungen sowie Änderungen bestehender Einträge ist[18]. Die Registrierungsstelle für ISO 693-1 ist Infoterm, für ISO 639-2 die Library of Congress und ISO 639-3 wird von SIL International verwaltet.
Die Benennung der Kennungen soll möglichst der landessprachlichen Bezeichnung der kodierten Sprache folgen. Ausnahmen werden unter Umständen gemacht, wenn Länder, in denen die betroffene Sprache gesprochen wird, eine andere Benennung wünschen.
Spezielle Kennungen
Die beiden Normen ISO 639-2 und ISO 639-3 verfügen über spezielle Kennungen, um einen flexiblen Umgang mit der Identifizierung von Texten zu ermöglichen.
Die Kennungen von
qaabisqtz(inklusive der alphabetisch dazwischen liegenden Kennungen) sind für die lokale Verwendung registriert und werden von der Registrierungsstelle nicht vergeben.Für eine Kennzeichnung für Dokumente ohne sprachlichen Inhalt wurde die Kennung
zxxerst später eingeführt[19]. Sie kann für die Kennzeichnung von Dokumenten verwendet werden, die keinen Text enthalten, z. B. Notendrucke oder Fotos[20].Mit
mul(von englisch multiple languages für „mehrere Sprachen“), der für die Auszeichnung mehrerer Sprachen gedacht ist, wenn eine Kennzeichnung durch alle einzelnen Kennungen nicht angebracht ist, sowieund(von englisch undetermined für „unbekannt“) für eine nicht identifizierbare Sprache gibt es zwei besondere Kennungen[8].Bezeichnung der Sprache nach Request for Comments 4646
Eine Kombination der Sprachcodes der ISO 639 Norm mit weiteren Normen zur Kennzeichnung von Sprachen und Schriften wird durch die Request for Comments 4646 (RFC 4646) gegeben. Dort wird das Zusammenspiel von Sprachcodes (ISO 639), geographischen Codes (ISO 3166-1) und Schriftcodes (ISO 15924) beschrieben.
Die Norm ISO 3166-1 kennzeichnet geographische Entitäten und kann so für die Bezeichnung von Sprachen und Dialekten einer bestimmten Region genutzt werden. Wie ISO 639-1 verwendet auch ISO 3166-1 zwei-buchstabige Kürzel. Dort wird empfohlen, geographische Codes in Großbuchstaben darzustellen. Sprach- und Regionscodes überschneiden sich, so bezeichnet
denach ISO 639-1 die deutsche Sprache undDEnach ISO 3166-1 das Land Deutschland,frdie Französische Sprache undFRanalog das Gebiet des Staates Frankreich. Es können aber gleiche Codes in den verschiedenen Standards auch unterschiedliche Begrifflichkeiten markieren, wieBEfür Belgien undbefür die weißrussische Sprache („Belarussisch“),EUfür die Europäische Union undeuandererseits für die baskische Sprache („Euskara“). Diese Überschneidungen spielen aber in der Praxis keine Rolle, da immer der Sprachcode an erster Stelle, vor dem Bindestrich, steht.Mit ISO 15924 können Schriftsysteme identifiziert werden. Typischerweise werden sie mit einem vier-buchstabigen Code dargestellt, dessen erster Buchstabe in der Regel groß geschrieben wird. So stehen
Cyrlfür die Schrift nach dem kyrillischen Alphabet undLatnfür die Schrift nach dem lateinischen Alphabet.Ein Beispiel für einen Code nach RFC 4646 ist
fr-Latn-CAfür Französisch nach dem lateinischen Alphabet wie es in Kanada geschrieben wird.RFC 4646 verlangt nicht, dass zwischen Groß- und Kleinschreibung unterschieden wird. So ist z. B.
fr-Latn-CAidentisch mitfr-latn-ca.Beispiel der Sprachkennungen nach ISO 639
Diese Tabelle zeigt (sortiert nach Sprachcodes) die verschiedenen Spracheinträge und stellt Zusammenhänge zwischen den Teilnormen der ISO 639 dar. So werden lebendige, historische und künstliche Sprachen aufgeführt. Manche Kennungen existieren nicht in den anderen Normen, oder sie existieren in einer anderen Form.
Sprache ISO 639-1 ISO 639-2 (B/T) ISO 639-3 Art des Beispiels Altkirchenslawisch cu chu chu Historische Sprache, Sakralsprache Deutsch de ger/deu deu B- und T-Kennung für ISO 639-2 Esperanto eo epo epo Konstruierte Sprache (Plansprache) Obersorbisch – hsb hsb Minderheitensprache Irokesische Sprachen – iro – Kollektive Kennung für Sprachfamilie Japanische Sprache ja jpn jpn Alpha-2- und Alpha-3-Kennung teilen sich nicht zwei Buchstaben Lettgallisch lv lav lav Fällt ohne eigenen Eintrag unter die Lettische Sprache[21] Ladakhische Sprache – sit lbj Sprache ohne eigenen Sprachcode für ISO 639-2, dort unter sonstige sinotibetischen Sprachen Sanskrit sa san san Historische Sprache, als Zweitsprache noch in Verwendung Nordsamische Sprache se sme sme Sprache mit eigenem Sprachcode, trotz Existenz einer zugehörigen, kollektiven Kennung andere Samische Sprachen – smi – Sprachfamilie mit kollektiver Kennung, nur für Sprachen ohne eigenen Eintrag Klingonisch – tlh tlh Konstruierte Sprache, für die Unterhaltungsindustrie erfunden Chinesische Sprachen zh chi/zho zho Eintrag für Sprachfamilie mit gleicher Schriftsprache aber ohne gegenseitige Verständlichkeit in der gesprochenen Sprache; in ISO 639-3 Makrosprache Weitere Vorläufer und verwandte Standards
- Im deutschen Sprachraum wurde früher die 1986 verabschiedete Norm DIN 2335 verwendet.
- ISO 15924 (Script Codes) zu Kennzeichnung von Schriftsystemen
- Die Library of Congress führt auch die MARC Code List for Languages [7].
- Die National Information Standards Organization führt mit ANSI/NISO Z39.53 (Codes for the Representation of Languages for Information Interchange) einen Standard zu Sprachkennungen, der ebenfalls durch die Library of Congress verwaltet wird.
Einzelnachweise
- ↑ a b c Frequently Asked Questions (FAQ) - Codes for the representation of names of languages (Library of Congress). In: ISO 639-2 Registration Authority. Library of Congress. Abgerufen am 24.10.2006.
- ↑ a b Internationale Organisation für Normung (ISO) (Hrsg.): Codes for the representation of names of languages — Part 3: Alpha-3 code for comprehensive coverage of languages, 1. Auflage, 1. Februar 2007
- ↑ a b c Registration Authority bei der Library of Congress
- ↑ International Information Centre For Terminology
- ↑ H. Alvestrand: RFC 3066 − Tags for the Identification of Languages. Januar 2001
- ↑ Working principles for ISO 639 maintenance. In: ISO 639-2 Registration Authority. Library of Congress, 02.06.2006. Abgerufen am 05.08.2007.
- ↑ a b MARC Code List for Languages. In: MARC. Library of Congress, 17.12.2007. Abgerufen am 31.12.2007.
- ↑ a b ISO 639 codes arranged alphabetically by alpha-3 code: downloadable text files. In: ISO 639-2 Registration Authority. Library of Congress, 29.10.2007. Abgerufen am 08.11.2007.
- ↑ ISO 639-3:2007. In: ISO Standards. Internationale Organisation für Normung (ISO). Abgerufen am 06.08.2007.
- ↑ a b Relationship between ISO 639-3 and the other parts of ISO 639. In: ISO 639-3. SIL International. Abgerufen am 28.03.2007.
- ↑ COPTIC: a n extinct language of Egypt. In: Ethnologue 14. SIL International. Abgerufen am 05.08.2007.
- ↑ ISO 639-3 Macrolanguage Mappings. In: ISO 639-3. SIL International. Abgerufen am 28.03.2007.
- ↑ Scope of denotation for language identifiers – Macrolanguages. In: ISO 639-3. SIL International. Abgerufen am 28.03.2007.
- ↑ John Cowan und Don Osborn: Wikimedia language codes. E-Mail-Austausch zwischen John Cowan und Don Osborn auf der Mailingliste ietf-languages, 13. September 2006
- ↑ a b John Cowan und Peter Constable: What's the plan for ISO 639-3 and RFC 3066 ter?. E-Mail-Austausch zwischen John Cowan und Peter Constable auf der Mailingliste ietf-languages, 20. August 2004
- ↑ ISO/DIS 639-4. Internationale Organisation für Normung (ISO). Abgerufen am 12. Mai 2008.
- ↑ Lee Gillam, Debbie Garside, Chris Cox: Developments in Language Codes standards. In Rehm, Witt and Lemnitzer (Hrsg.): Datenstrukturen für linguistische Ressourcen und ihre Anwendungen / Data Structures for Linguistic Resources and Applications. Proc. of GLDV 2007, 11-13 April 2007. Gunter Narr Verlag, Tübingen. ISBN 978-3-8233-6314-9.
- ↑ siehe z. B. die Änderungsmitteilung zu ISO 639-2: ISO 639-2/RA Change Notice (englisch)
- ↑ ISO 639-2/RA Change Notice. In: ISO 639-2 Registration Authority. Library of Congress, 29.09.2006. Abgerufen am 26.10.2006.
- ↑ %5D=preview_objectFile&we_objectID=6541&we_cmd%5B2 %5D=93 Aktualisierung der Sprachcodes nach ISO 639-2. Hessisches BibliotheksInformationsSystem, 26.10.2006. Abgerufen am 26.10.2006.
- ↑ MARC Code List for Languages. In: MARC. Library of Congress, 26.03.2008. Abgerufen am 15.06.2008.
Weblinks



Wikimedia Foundation.