- Stichprobenfehler
-
Der Standardfehler oder Stichprobenfehler (selten Schätzfehler) ist ein Streuungsmaß für eine Stichprobenverteilung. Der Standardfehler des Mittelwertes ist definiert als die Wurzel aus der Varianz der Verteilung der Stichproben-Mittelwerte von gleichgroßen Stichproben aus einer gegebenen Grundgesamtheit. Bezeichnen n die Größe der Stichprobe und σ2 die Varianz der Grundgesamtheit, so ist der Standardfehler durch folgende Formel gegeben:
Herleitung der Formel
Der Mittelwert einer Stichprobe vom Umfang n ist definiert durch
Betrachtet man diesen als Zufallsvariable
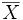 , so ist der Standardfehler definiert als die Wurzel aus deren Varianz, also aus
, so ist der Standardfehler definiert als die Wurzel aus deren Varianz, also auswobei μ den (in der Regel unbekannten) Mittelwert der Grundgesamtheit bezeichnet. Der Standardfehler ist also
Mit einige Zeilen Rechnung
folgt dann die obige Formel für den Standardfehler.
Interpretation und Beispiele
Der Standardfehler liefert so eine Aussage über die Güte des ermittelten Mittelwertes. Je mehr Einzelwerte es gibt, desto robuster ist der Mittelwert und desto kleiner der Standardfehler. Der Standardfehler findet zum Beispiel Anwendung bei der Messung von Naturkonstanten (Lichtgeschwindigkeit, Bindungskonstanten von Enzymen, o. ä.). Wenn hier bei mehreren Messungen unterschiedliche Ergebnisse ermittelt werden, variiert nicht die Naturkonstante, sondern die Abweichungen werden durch Messfehler verursacht, das heißt Ungenauigkeiten des Messgerätes. Misst man häufiger, nähert man sich dem wahren Mittelwert an.
Im Gegensatz dazu bildet die Standardabweichung die in einer Population (= Grundgesamtheit) tatsächlich vorhandene Streuung ab, die auch bei höchster Messgenauigkeit und unendlich vielen Einzelmessungen vorhanden ist (z. B. bei Gewichtsverteilung, Größenverteilung, Monatseinkommen). Sie zeigt ob die Einzelwerte nahe beieinander liegen oder eine starke Spreizung der Daten vorliegt.
- Beispiel: Angenommen, man untersucht die Population von Kindern, die Gymnasien besuchen, hinsichtlich ihrer Intelligenzleistung. Wenn nun zufällig aus dieser Population eine Stichprobe des Umfanges n (also mit n Kindern) gezogen wird, dann kann man aus allen n Messergebnissen den Mittelwert berechnen. Wenn nun nach dieser Stichprobe noch eine weitere, zufällig gezogene Stichprobe mit der gleichen Anzahl von n Kinder gezogen und deren Mittelwert ermittelt wird, so werden die beiden Mittelwerte nicht exakt übereinstimmen. Zieht man noch eine Vielzahl weiterer zufälliger Stichproben des Umfanges n, dann kann die Streuung aller empirisch ermittelten Mittelwerte um den Populationsmittelwert ermittelt werden. Diese Streuung ist der Standardfehler. Da der Mittelwert der Stichprobenmittelwerte der beste Schätzer für den Populationsmittelwert ist, entspricht der Standardfehler der Streuung der empirischen Mittelwerte um den Populationsmittelwert. Er bildet nicht die Intelligenzstreuung der Kinder, sondern die Genauigkeit des errechneten Mittelwerts ab.
Für den Standardfehler des Stichprobenmittelwertes benutzt man meist die Bezeichnungen
um zu verdeutlichen, dass es sich um die Streuung der Mittelwerte von Stichproben handelt. Hierbei ist der Stichprobenumfang n in der Regel bekannt, während die Standardabweichung σ in der Regel unbekannt ist; als Schätzwert für σ benutzt man meist die Wurzel der Stichprobenvarianz.
Für
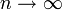 nähert sich die standardisierte Verteilung der Mittelwerte nach dem zentralen Grenzwertsatz einer Normalverteilung an. In der Praxis ist n > 30 meist ausreichend.
nähert sich die standardisierte Verteilung der Mittelwerte nach dem zentralen Grenzwertsatz einer Normalverteilung an. In der Praxis ist n > 30 meist ausreichend.Der Standardfehler macht die gemessene Streuung (Standardabweichung) von zwei Datensätzen mit unterschiedlichen Stichprobenumfang vergleichbar, indem er die Standardabweichung auf den Stichprobenumfang normiert.
Bestimmung des Standardfehlers bei einigen bestimmten Verteilungen
Bei der Binomialverteilung zum Parameter p wird der Standardfehler wie folgt berechnet:
Exponentialverteilung zum Parameter λ (Erwartungswert = Standardabweichung = 1 / λ):
Poissonverteilung zum Parameter λ (Erwartungswert = Varianz = λ):
Dabei bezeichnen
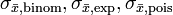 die Standardfehler der jeweiligen Verteilung, und
die Standardfehler der jeweiligen Verteilung, und- n den Stichprobenumfang.
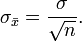
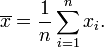
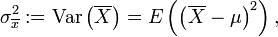
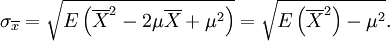
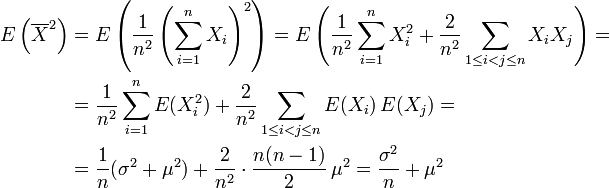
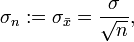
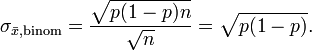
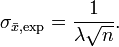
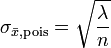
Wikimedia Foundation.