- UTF32
-
 Unicode
UnicodeKodierungen Techniken UTF-32 ist eine Methode zur Kodierung von Unicode-Zeichen, bei der jedes Zeichen mit vier Byte (32 Bit) kodiert wird. Sie kann deshalb als die einfachste Kodierung bezeichnet werden, da alle anderen UTF-Kodierungen variable Bytelängen benutzen. Im aktuellen Unicode Standard 5.1 ist UTF-32 eine Untermenge von UCS-4.
Vorteile
UTF-32 zeigt seine besonderen Vorteile beim wahlfreien Zugriff auf ein bestimmtes Zeichen, da die Adresse des n-ten Zeichens durch einfachste Zeigerarithmetik in
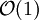 ermittelt werden kann. Es ist auch möglich, anhand der Größe eines Dokuments in Bytes, umgehend die Anzahl der enthaltenen Zeichen auszurechnen (nämlich durch eine simple Division durch 4). Diese Eigenschaft relativiert sich allerdings dadurch, dass oftmals ein Unicodezeichen nicht einem Schriftzeichen entspricht (z. B. bei Ligaturen).
ermittelt werden kann. Es ist auch möglich, anhand der Größe eines Dokuments in Bytes, umgehend die Anzahl der enthaltenen Zeichen auszurechnen (nämlich durch eine simple Division durch 4). Diese Eigenschaft relativiert sich allerdings dadurch, dass oftmals ein Unicodezeichen nicht einem Schriftzeichen entspricht (z. B. bei Ligaturen).Nachteile
Der entscheidende Nachteil von UTF-32 ist der hohe Speicherbedarf. Bei Texten, die überwiegend aus lateinischen Buchstaben bestehen, wird verglichen mit dem verbreiteten UTF-8- oder den ISO-8859-Zeichensätzen etwa der vierfache Speicherplatz belegt. Deshalb wird es auch kaum zum externen Speichern verwendet.
Wikimedia Foundation.