- Wahrscheinlichkeitsbaum
-
Entscheidungsbäume sind eine spezielle Darstellungsform von Entscheidungsregeln. Sie veranschaulichen aufeinanderfolgende, hierarchische Entscheidungen. Sie haben eine Bedeutung
- in der Stochastik zur Veranschaulichung bedingter Wahrscheinlichkeiten (Beispiel bei Absolute Häufigkeit),
- im Data-Mining,
- in der Entscheidungstheorie sowie in der ärztlichen Entscheidungsfindung (Medizin) und in der Notfallmedizin,
- in Business-Rule-Management-Systemen (BRMS) für die Definition von Regeln.
Inhaltsverzeichnis
Funktionsweise
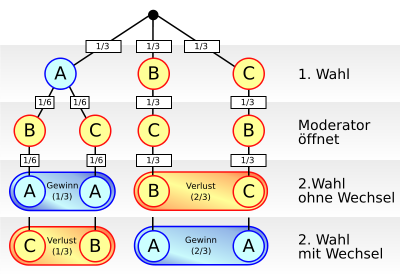 Entscheidungsbaum für das Ziegenproblem
Entscheidungsbaum für das ZiegenproblemEntscheidungsbäume sind Bäume, bei denen bei jeder Verzweigung die Verzweigungsmöglichkeiten (Äste) mit Wahrscheinlichkeiten versehen sind. Sie werden verwendet, um besser und mit weniger Fehlern eine Entscheidung treffen zu können. Im binären Entscheidungsbaum wird eine Serie von Fragen gestellt, welche alle mit Ja oder Nein beantwortet werden können. Diese Serie ergibt ein Resultat, welches durch eine Regel bestimmt ist. Die Regel ist einfach ablesbar, wenn man von der Wurzel her den Ästen des Baumes folgt, bis man zu einem bestimmten Blatt gelangt, welches das Resultat der Fragereihe darstellt.
Entscheidungsbäume trennen die Daten in mehrere Gruppen, welche jeweils durch eine Regel mit mindestens einer Bedingung bestimmt werden. Um eine Klassifikation abzulesen, geht man entlang des Baumes abwärts. Bei jedem Knoten wird ein Attribut abgefragt und eine Entscheidung getroffen. Diese Prozedur wird so lange fortgesetzt, bis man ein Blatt erreicht.
Generiert werden die Entscheidungsbäume üblicherweise im Top-down-Prinzip. Bei jedem Schritt wird das Attribut gesucht, mit welchem man die Daten am besten klassifizieren kann. Um dieses zu ermitteln, muss der beste Schnitt (split) gefunden werden, d. h. die Aufteilung der Daten muss so gewählt werden, dass sie nach der Aufteilung möglichst rein sind. Ein Maß für die Reinheit ist die Entropie. Aus der Entropie lässt sich dann berechnen, welches Attribut für den Schnitt den höchsten Informationsgewinn bietet. Ein weiteres Maß für die Bestimmung des besten Schnitts ist der Gini-Index. Das ermittelte Attribut wird nun zur Aufteilung der Daten verwendet, so dass man die verbliebenen, noch nicht klassifizierten Daten in weiteren Schritten separat betrachten kann. Entscheidungsbäume werden deshalb auch Klassifikationsbäume genannt.
Entscheidungsbäume können als Systeme zur Regelinduktion angesehen werden. Sie sind einfach und verständlich präsentierbar und ihre Generierung ist schnell durchführbar.
Ein weiterer Typus von Entscheidungsbaum
Im Rahmen einer anderen Anwendung werden Entscheidungsbäume von links nach rechts gezeichnet (und umgekehrt berechnet), um Payoffs aus Ausgaben und Einnahmen zu errechnen und die Entscheidung für maximalen Payoff zu optimieren.
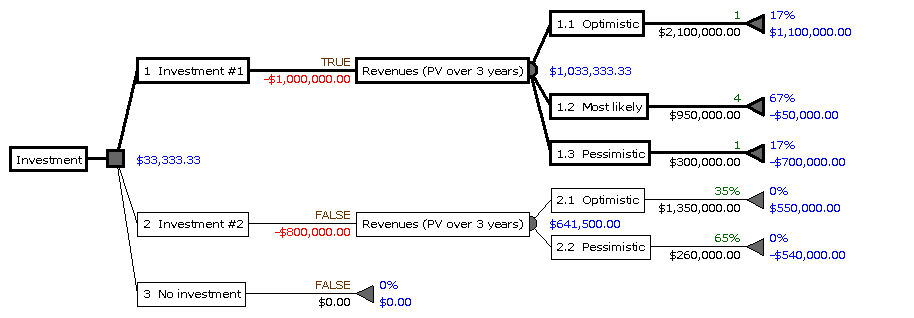
Bei diesen Entscheidungsbäumen stehen Quadrate für Entscheidungen, Kreise für Möglichkeiten, und Dreiecke terminieren die Zweige. Entscheidungsbäume dieses Typs können mit anderen Verfahren kombiniert werden, im Beispiel oben werden NPV (Net Present Value, Netto-Barwert), lineare Verteilung von Annahmen (Investment #2) und PERT 3-Punkt-Schätzung (Investment #1) verwendet.
Beispiel einer Anwendung
 Beispiel:Entscheidungsbaum für das Hochladen von Bildern in Wikipedia
Beispiel:Entscheidungsbaum für das Hochladen von Bildern in WikipediaEine Bank möchte mit einer Direct-Mailing-Aktion einen neuen Service verkaufen. Um den Gewinn zu maximieren, sollen mit der Aktion diejenigen Haushalte angesprochen werden, welche der Kombination von demografischen Variablen entsprechen, die der entsprechende Entscheidungsbaum als optimal erklärt hat. Dieser Prozess wird Data Segmentation oder auch Segmentation Modeling genannt.
Der Entscheidungsbaum liefert also gute Tipps, wer positiv auf den Versand reagieren könnte. Dies erlaubt der Bank, nur diejenigen Haushalte anzuschreiben, welche der Zielgruppe entsprechen.
Vor- und Nachteile
Die mögliche Größe der Entscheidungsbäume kann sich negativ auswirken. Jede einzelne Regel ist zwar leicht abzulesen, den Gesamtüberblick zu haben ist jedoch sehr schwierig. Es wurden deshalb so genannte Pruning-Methoden entwickelt, welche die Entscheidungsbäume auf eine vernünftige Größe kürzen. Beispielsweise kann man die maximale Tiefe der Bäume beschränken oder eine Mindestanzahl der Objekte pro Knoten festlegen.
Oft bedient man sich der Entscheidungsbäume nur als Zwischenschritt zu einer effizienteren Darstellung des Regelwerkes. Um zu den Regeln zu gelangen, werden durch verschiedene Verfahren unterschiedliche Entscheidungsbäume generiert. Dabei werden häufig auftretende Regeln extrahiert. Die Optimierungen werden überlagert, um einen robusten, allgemeinen und korrekten Regelsatz zu erhalten. Dass die Regeln in keinerlei Beziehungen zueinander stehen und dass widersprüchliche Regeln erzeugt werden können, wirkt sich nachteilig auf diese Methode aus.
Ein großer Vorteil von Entscheidungsbäumen ist, dass sie gut erklärbar und nachvollziehbar sind. Dies erlaubt dem Benutzer, das Ergebnis auszuwerten und Schlüsselattribute zu erkennen. Dies ist vor allem nützlich, wenn die Qualität der Daten nicht bekannt ist. Die Regeln selber können ohne großen Aufwand in eine einfache Sprache wie SQL übernommen werden.
Wirksamkeit und Fehlerrate
Die Wirksamkeit eines Entscheidungsbaumes kann an der Anzahl Prozentpunkte abgelesen werden, welche die Daten korrekt klassifizieren. Einige Regeln funktionieren besser als andere. Ein Phänomen des Entscheidungsbaum ist die Überanpassung. Man hat experimentell festgestellt, dass mit zunehmender Komplexität des Baumes die Klassifikationsgüte abnimmt. Als Lösung für das Problem wird Pruning eingesetzt.
Kombination mit Neuronalen Netzen
Entscheidungsbäume werden häufig als Basis für Neuronale Netze verwendet. Sie brauchen nicht so viele Beispiele wie die Neuronalen Netze. Dafür können sie ziemlich ungenau sein, besonders wenn sie klein sind. Große Bäume hingegen bergen die Gefahr, dass etliche Beispiele bei den Trainingsfällen nicht gesehen und registriert werden. Deshalb versucht man, Entscheidungsbäume mit Neuronalen Netzen zu kombinieren. Daraus entstanden die so genannten TBNN (Tree-Based Neural Network), welche die Regeln der Entscheidungsbäume in die Neuronalen Netze übersetzen.
Algorithmen im Vergleich
Die Methoden der Entscheidungsfindung änderten sich mit dem Aufkommen der aktuellen Algorithmen ziemlich stark in den letzten Jahrzehnten. Einige Fachbegriffe wie Wurzel, Kante, Knoten u.ä. wurden allerdings schon sehr früh benutzt. Noch nicht sehr alt sind die verschiedenen Algorithmen, die zur Berechnung der Entscheidungsbäume verwendet werden.
Die Praxis unterscheidet verschiedene Baumtypen. Am bekanntesten sind die CARTs (Classification And Regression Trees) und die CHAIDs (Chi-square Automatic Interaction Detectors). In letzter Zeit häufig verwendet wurde auch der C4.5-Algorithmus. Früher wurde stattdessen oft der ID3-Algorithmus verwendet.
Anwendungsprogramme
Es gibt etliche Anwendungsprogramme, die Entscheidungsbäume implementiert haben, so werden sie zum Beispiel in den Statistiksoftwarepaketen GNU R, SPSS und SAS angeboten. Die letzteren beiden Pakete verwenden übrigens – wie die meisten anderen Data Mining-Software-Pakete auch – den CHAID-Algorithmus.
Siehe auch


Wikimedia Foundation.