- Befehls-Pipeline
-
Die Pipeline (auch Befehls-Pipeline oder Prozessor-Pipeline) bezeichnet bei Mikroprozessoren eine Art „Fließband“, mit dem die Abarbeitung der Maschinenbefehle in Teilaufgaben zerlegt wird, die für mehrere Befehle parallel durchgeführt werden. Dieses Prinzip, oft auch kurz Pipelining genannt, stellt eine weit verbreitete Mikroarchitektur heutiger Prozessoren dar.
Statt eines gesamten Befehls wird während eines Taktzyklus des Prozessors nur jeweils eine Teilaufgabe abgearbeitet, allerdings werden die verschiedenen Teilaufgaben mehrerer Befehle dabei gleichzeitig bearbeitet. Da diese Teilaufgaben einfacher (und somit schneller) sind als die Abarbeitung des gesamten Befehls am Stück, kann durch Pipelining die Taktfrequenz des Mikroprozessors gesteigert werden. Insgesamt benötigt ein einzelner Befehl nun mehrere Takte zur Ausführung, da aber durch die quasiparallele Bearbeitung mehrerer Befehle in jedem Zyklus ein Befehl „fertiggestellt“ wird, wird der Gesamtdurchsatz durch dieses Verfahren erhöht.
Die einzelnen Teilaufgaben einer Pipeline nennt man Pipeline-Stufen, Pipeline-Stages oder auch Pipeline-Segmente. Diese Stufen werden durch getaktete Pipeline-Register getrennt. Neben einer Befehls-Pipeline kommen in modernen Systemen verschiedene weitere Pipelines zum Einsatz, beispielsweise eine Arithmetik-Pipeline in der Gleitkommaeinheit.
Inhaltsverzeichnis
Beispiel
Beispiel einer vierstufigen Befehlspipeline:
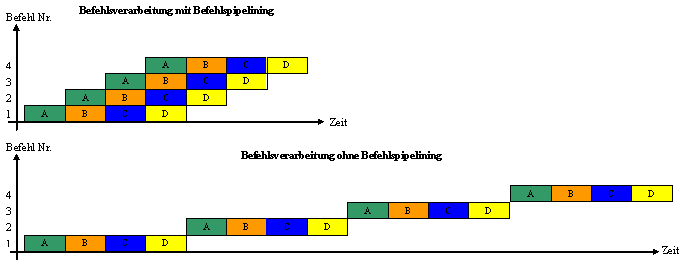
- A – Befehlscode laden (IF, Instruction Fetch)
- In der Befehlsbereitstellungsphase wird der Befehl, der durch den Befehlszähler adressiert ist, aus dem Arbeitsspeicher geladen. Der Befehlszähler wird anschließend hochgezählt.
- B – Instruktion dekodieren und Laden der Daten (ID, Instruction Decoding)
- In der Dekodier- und Ladephase wird der geladene Befehl dekodiert (1. Takthälfte) und die notwendigen Daten aus dem Arbeitsspeicher und dem Registersatz geladen (2. Takthälfte).
- C – Befehl ausführen (EX, Execution)
- In der Ausführungsphase wird der dekodierte Befehl ausgeführt. Das Ergebnis wird durch den Pipeline-latch gepuffert.
- D – Ergebnisse zurückgeben (WB, Write Back)
- In der Resultatspeicherphase wird das Ergebnis in den Arbeitsspeicher oder in den Registersatz zurückgeschrieben.
Taktung
Je einfacher eine einzelne Stufe aufgebaut ist, desto höher ist die Frequenz, mit der sie betrieben werden kann. In einer modernen CPU mit einem Kerntakt im Gigahertz-Bereich (1 GHz ~ 1 Milliarde Takte pro Sekunde) kann die Befehlspipeline über 30 Stufen lang sein (vgl. NetBurst). Der Kerntakt ist die Zeit, die ein Befehl braucht, um eine Stufe der Pipeline zu durchwandern. In einer k-stufigen Pipeline wird ein Befehl also in k Takten von k Stufen bearbeitet. Da in jedem Takt ein neuer Befehl geladen wird, verlässt im Idealfall auch ein Befehl pro Takt die Pipeline.
Der Takt wird durch die Zykluszeit der Pipeline bestimmt und berechnet sich aus der Summe der maximalen Stufenverzögerung τm aus allen Stufenverzögerungen τi und einem Zusatzaufwand d, welcher durch die Zwischenspeicherung der Ergebnisse in Pipeline-Registern verursacht wird.
Zykluszeit:
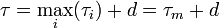
Leistungssteigerung
Durch das Pipelining wird der Gesamtdurchsatz gegenüber Befehlsabarbeitung ohne Pipelining erhöht. Die Gesamtzeit für die Pipeline-Verarbeitung mit k Stufen und n Befehlen bei einer Zykluszeit τ ergibt sich aus:
Gesamtzeit:
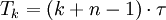
Anfangs ist die Pipeline leer und wird in
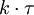 Schritten gefüllt. Nach jeder Stufe wird ein neuer Befehl in die Pipeline geladen, und ein anderer Befehl wird fertiggestellt. Die restlichen Befehle werden daher in
Schritten gefüllt. Nach jeder Stufe wird ein neuer Befehl in die Pipeline geladen, und ein anderer Befehl wird fertiggestellt. Die restlichen Befehle werden daher in 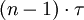 Schritten fertiggestellt.
Schritten fertiggestellt.Bildet man nun den Quotienten aus der Gesamtzeit für Befehlsabarbeitung mit und ohne Pipelining, so erhält man den Speed-Up. Dieser repräsentiert den Leistungsgewinn, der durch das Pipelining-Verfahren erreicht wird:
Speed-Up:
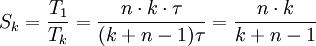
Geht man davon aus, dass immer genügend Befehle vorhanden sind, welche die Pipeline füllen, so ergibt sich der Grenzwert des Speed-Ups für n gegen unendlich:
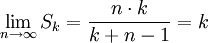
Das bedeutet, dass mit zunehmender Stufenanzahl k die Leistung beliebig gesteigert werden kann. Jedoch lässt sich die Befehlsabarbeitung nicht in beliebig viele Stufen unterteilen. Eine Steigerung der Stufenanzahl hat ebenfalls schwerere Auswirkungen beim Auftreten von Daten- oder Steuerungskonflikten zur Folge. Ebenfalls steigt der Aufwand der Hardware mit steigender Stufenanzahl k.
Konflikte
Ist es für die Bearbeitung eines Befehls in einer Stufe der Pipeline notwendig, dass ein Befehl, der sich weiter vorne in der Pipeline befindet, zuerst abgearbeitet wird, so spricht man von Abhängigkeiten. Diese können zu Konflikten (engl. Hazards) führen. Es können drei Konfliktarten auftreten:
- Ressourcenkonflikte, wenn eine Stufe der Pipeline Zugriff auf eine Ressource benötigt, die bereits von einer anderen Stufe belegt ist
- Datenkonflikte,
- auf Befehlsebene: Daten, die in einem Befehl benutzt werden, stehen nicht zur Verfügung
- auf Transferebene: Registerinhalte, die in einem Schritt benutzt werden, stehen nicht zur Verfügung
- Kontrollflusskonflikte, wenn die Pipeline abwarten muss, ob ein bedingter Sprung ausgeführt wird oder nicht.
Diese Konflikte erfordern es, dass entsprechende Befehle am Anfang der Pipeline warten („stallen“), was „Lücken“ (auch „Bubbles“) in der Pipeline erzeugt. Dies führt dazu, dass die Pipeline nicht optimal ausgelastet ist und der Durchsatz sinkt. Daher ist man bemüht, diese Konflikte soweit wie möglich zu vermeiden:Ressourcenkonflikte lassen sich durch Hinzufügen zusätzlicher Funktionseinheiten lösen. Viele Datenkonflikte lassen sich durch Forwarding lösen, wobei Ergebnisse aus weiter hinten liegenden Pipeline-Stufen nach vorn transportiert werden, sobald diese verfügbar sind (und nicht erst am Ende der Pipeline).
Kontrollflusskonflikte lassen sich durch eine Sprungvorhersage (engl. Branch-Prediction) verhindern. Hierbei wird spekulativ weitergerechnet, bis feststeht, ob sich die Vorhersage als richtig erwiesen hat. Im Falle einer falschen Sprungvorhersage müssen in der Zwischenzeit ausgeführte Befehle verworfen werden (Pipeline-Flush), was besonders bei Architekturen mit langer Pipeline (wie etwa bei Intel Pentium 4 oder IBM Power5) viel Zeit kostet. Deshalb besitzen diese Architekturen sehr ausgeklügelte Techniken zur Sprungvorhersage, so dass die CPU nur in weniger als einem Prozent der stattfindenden Sprünge den Inhalt der Befehlspipeline verwerfen muss.
Vorteile und Nachteile
Der Vorteil langer Pipelines besteht in der starken Steigerung der Verarbeitungsgeschwindigkeit. Der Nachteil besteht gerade darin, dass sich sehr viele Befehle gleichzeitig in Bearbeitung befinden. Im Falle eines Pipeline-Flushs müssen alle Befehle in der Pipeline verworfen werden und die Pipeline anschließend neu gefüllt werden. Dies bedarf des Nachladens von Befehlen aus dem Arbeitsspeicher oder dem Befehlscache der CPU, so dass sich hohe Latenzzeiten ergeben, in denen der Prozessor untätig ist. Anders formuliert ist der Gewinn durch Pipelining umso größer, je höher die Anzahl der Befehle zwischen Kontrollflußänderungen ist, da die Pipeline dann erst nach längerer Benutzung unter Volllast wieder geflusht werden muss.
Siehe auch
Weblinks
- Artikel über Pipelining bei arstechnica.com (englisch) (teil 1) (teil 2)
- Ausarbeitung zu den grundlegendsten Themen der Rechnerarchitektur (Überblick) (Kapitel 6 - Pipelining)
Wikimedia Foundation.