- ΤΕΧ
-
(TeX) 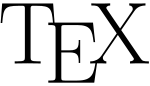
Entwickler: Donald E. Knuth Aktuelle Version: 3.1415926
(März 2008)Betriebssystem: viele Kategorie: Schriftsatz Lizenz: eigene www.tug.org ΤΕΧ [tɛχ] (im deutschsprachigen Raum auch: [tɛç]) ist ein von Donald E. Knuth ab 1977 entwickeltes und 1986 fertig gestelltes Textsatzsystem mit eingebauter Makrosprache, die ebenfalls als „TeX“ bezeichnet wird. Häufig wird die Makro-Sammlung LaTeX fälschlich ebenfalls „TeX“ genannt.
Inhaltsverzeichnis
Aussprache und Herkunft
Das „Χ“ ist eigentlich der großgeschriebene griechische Buchstabe χ (Chi), denn TeX soll eine Abkürzung für griechisch Τέχνη sein, was Kunst bedeutet. Von diesem Wort sind im Deutschen Wörter wie Technik und Technokrat abgeleitet. Deshalb soll laut Knuth das X nicht [ks], sondern als Ach-Laut wie in Bach ausgesprochen werden: [tɛχ]. Dieser Laut ist nach einem vorderen Vokal wie e für deutsche Sprecher ungewohnt. Daher hat sich auch die Form [tɛç] mit Ich-Laut wie in Technik eingebürgert.
„Τ“ und „Ε“ stehen ebenfalls für die großgeschriebenen griechischen Buchstaben τ und ε (Tau und Epsilon). In der Aussprache sind diese jedoch identisch mit lateinischem T und E.
Verwendung
TeX kann für alle Arten von Texten verwendet werden, vom kurzen Brief bis zu mehrbändigen Büchern. Viele große wissenschaftliche Verlage nutzen es für den Buchdruck bzw. Werksatz. Eine besondere Stärke ist der mathematische Formelsatz sowie das Schriftbild.
Technik
Technisch gesehen handelt es sich bei TeX um einen Interpreter, der rund 300 fest eingebaute Befehle (sogenannte primitives) kennt und einen komplexen Mechanismus zur Definition eigener Makros bereitstellt. Der Textsatz erfolgt absatzweise, wobei nach einem raffinierten Optimierungsverfahren alle Zeilenumbrüche (inklusive Worttrennung) im Absatz gleichzeitig bestimmt werden. Ein einfacherer Algorithmus bestimmt danach den optimalen Seitenumbruch. Die Optimierungsverfahren arbeiten mit Bewertungspunkten (penalties), anhand derer die möglichen Umbruchspunkte bewertet werden. Zeilen- und Seitenumbruch werden von einer Vielzahl von Parametern, insbesondere Registern und elastischen Längen gesteuert, die auch im Dokument geändert werden können. (Eine genauere Beschreibung erfolgt unten.) TeX selbst kommt mit einem Minimum an Ressourcen aus und stellt nur die Grundfunktionen zur Verfügung.
TeX wird durch eine Vielzahl von Makropaketen ergänzt, die eine effiziente und komfortable Nutzung von TeX erst ermöglichen. Das bekannteste dieser Pakete ist das von Leslie Lamport entwickelte LaTeX. Darauf aufbauend gibt es Dutzende von Zusatzpaketen für alle erdenklichen Gebiete. Mit dem Paket hyperref lässt sich beispielsweise ohne großen Zusatzaufwand ein Hypertext erstellen, der die Navigation im Inhaltsverzeichnis und im Index in einem PDF-Leseprogramm ermöglicht. Ein anderes Makropaket ist ConTeXt, das im Gegensatz zu LaTeX mehr Funktionalität (wie Hypertext-Unterstützung) direkt eingebaut hat, für das es aber weniger Zusatzpakete gibt. Das Programm BibTeX ermöglicht die Erstellung und Verwaltung von Quellenangaben in TeX-Texten.
Die Definition des Befehlsumfanges von TeX steht seit 1990 fest. Knuths Anliegen war es, ein qualitativ hochstehendes Programm zu schaffen; das Programm wird als abgeschlossen betrachtet, es finden nur noch Fehlerkorrekturen statt. Die Versionsnummer wird entgegen den üblichen Konventionen der Software-Entwicklung seit den 1990ern so inkrementiert, dass sie sich langsam π annähert. Die aktuelle Version aus dem Jahr 2008 trägt die Nummer 3.1415926.
Beispiel
Das folgende Beispiel zeigt die Schritte, um in plain TeX Text zu setzen.
Zuerst wird eine Textdatei (zum Beispiel Text.tex) mit dem folgenden Inhalt erstellt:
Hallo \byeDer zu setzende Text ist in diesem Fall Hallo. Die Anweisung \bye ist ein TeX-Befehl, der das Ende der Datei angibt und in der Ausgabe nicht erscheint.
Danach gibt man in einem Kommandozeileninterpreter den Befehl
tex Text.tex
ein. TeX erzeugt die Datei Text.dvi (dvi steht für „device independent“, also „geräteunabhängig“).
Die Datei Text.dvi kann (etwa mit dem yap-Programm der MiKTeX-Distribution, oder mit xdvi unter UNIX) auf dem Bildschirm dargestellt werden. Auf dem Bildschirm erscheint eine Druckseite mit dem Wort „Hallo“.
Die dvi-Datei kann direkt vom Anzeigeprogramm aus ausgedruckt werden oder in ein Druckerformat (etwa PostScript, mit dem dvips-Programm) umgewandelt werden.
Mit pdftex bzw. pdflatex können direkt PDF-Dateien erzeugt werden:
pdftex Text.tex
Die Stärke von TeX liegt darin, dass für viele übliche Dokumente bereits Schablonen vorliegen, die man verwenden kann. LaTeX ist eine Sammlung von Makros, die in der Sprache TeX geschrieben sind. Das Beispiel skizziert, wie die minimale Struktur für ein Buch aussehen kann.
\documentclass[a4paper]{book} \usepackage[T1]{fontenc} \usepackage[latin1]{inputenc} %% \begin{document} \chapter{…Kapitel-Überschrift} \subsection{ … } %% Hier Text \end{document}
Um das Buch zu setzen ist auf der Kommandozeile folgendes aufzurufen.
latex myfile.tex // erzeuge myfile.dvi dvips myfile.dvi // erzeuge myfile.ps
oder
pdflatex myfile.tex // erzeuge myfile.pdf
Geschichte und Hintergrund
Knuth begann mit der Entwicklung des TeX-Systems, weil er mit der immer schlechter werdenden typographischen Qualität seiner Buchreihe The Art of Computer Programming (TAOCP) unzufrieden war:
Band 1 erschien 1968, Band 2 1969. Die Druckvorlagen wurden mit der Monotype-Technik gesetzt. Diese Art des Formelsatzes war aufwendig. Nach Erscheinen von Band 3 1973 verkaufte Knuths Verleger seine Monotype-Maschinen. Die korrigierten Neuauflagen von Band 1 und 3, die 1975 erschienen, mussten in Europa gesetzt werden, wo noch einige Monotype-Systeme in Gebrauch waren. Die Neuauflage von Band 2 sollte 1976 mit Fotosatz erstellt werden, doch die Qualität der ersten Proben enttäuschte Knuth sehr (Digital Typography, Kapitel 1). Er hatte 15 Jahre Arbeit in die Reihe gesteckt und wollte damit nur weitermachen, wenn die Bücher entsprechend gut gesetzt waren. Im Februar 1977 bot sich ein Ausweg, als Knuth im Rahmen einer Bücherevaluierung die Ausgabe eines digitalen Drucksystems mit 1000 dpi Auflösung vorgelegt bekam. Pat Winston hatte damit ein Buch über Artificial Intelligence geschrieben. Als Knuth dies klar wurde, unterbrach er die Arbeit an Band 4, von dem er die ersten 100 Seiten fertiggestellt hatte, und entschloss sich, selbst die Programme zu schreiben, die er und sein Verleger brauchten, um Band 2 neu zu setzen. Das Design von TeX begann am 5. Mai 1977. Knuth schätzte die notwendige Arbeit auf wenige Monate ein. Im Mai 1977 schrieb er an seinen Verleger, dass er die ersten Vorlagen im Juli fertig haben würde.
Nach vier Jahren Experimentierens mit einem Xerox-Satzsystem hatte er immer noch kein Ergebnis erzielt, welches den Fotosatz übertraf. Knuth aber gab nicht auf und traf viele wichtige Schriftdesigner, u. a. Hermann Zapf, von denen er lernte. Nach fünf weiteren Jahren Arbeit hatte er endlich einen Stand erzielt, mit dem er zufrieden war. Die Fertigstellung von TeX wurde am 21. Mai 1986 im Computer Museum, Boston, Massachusetts gefeiert.
In den Büchern der TAOCP-Reihe wollte Knuth bewusst einen Teil des Wissens der Informatik festhalten, von dem er annahm, dass es bereits eine solche Entwicklungsreife erlangt habe, dass dieses Wissen auch in hundert Jahren noch ähnlich dargestellt werde. Daher war es für ihn sehr ärgerlich, dass die typographische Qualität mit den damaligen Techniken von Auflage zu Auflage nachließ. Dass das TeX-Projekt dann fast zehn Jahre seiner Zeit in Anspruch nehmen würde, war nicht geplant.
“Ever since those beginnings in 1977, the TeX research project that I embarked on was driven by two major goals. The first goal was quality: we wanted to produce documents that were not just nice, but actually the best. (…) The second major goal was archival: to create systems that would be independent of changes in printing technology as much as possible. When the next generation of printing devices came along, I wanted to be able to retain the same quality already achieved, instead of having to solve all the problems anew. I wanted to design something that would be still usable in 100 years. ”
„Seit den Anfängen 1977 war das TeX-Forschungsprojekt, mit dem ich angefangen hatte, von zwei wesentlichen Zielen geprägt. Das erste war die Qualität: Unsere Druckwerke sollten nicht nur ‚ganz nett‘, sondern tatsächlich die besten sein (…) Das zweite große Ziel war die Archivierbarkeit: Das System sollte so unabhängig wie möglich von Änderungen in der Drucktechnik sein. Auch mit der nächsten Generation von Druckmaschinen wollte ich die bisherige Ausgabequalität erhalten und nicht all die Probleme von vorn lösen müssen. Ich wollte etwas entwerfen, das noch in 100 Jahren verwendet werden kann.“
– Donald E. Knuth: Digital Typography, S. 559
Zu den Programmen des TeX-Systems und ihrer Benutzung verfasste Knuth eine fünfbändige Reihe:
- je einen Band für den Quellcode (mit Kommentaren) für das Satzprogramm TeX und den Schriftgenerator METAFONT,
- je einen Band mit Benutzeranleitungen für den Einsatz von TeX und METAFONT,
- sowie einen Band mit den METAFONT-Quellprogrammen der Buchstaben der Computer-Modern-Schriften.
Neuartige Aspekte des TeX-Schriftsatzes
Der von TeX generierte Schriftsatz wies einige Aspekte auf, die zur Zeit des Erscheinens von TeX neuartig oder in anderen Textsatzsystemen von niedrigerer Qualität waren. Einigen dieser Innovationen liegen interessante Algorithmen zu Grunde, die Thema mehrerer Abschlussarbeiten von Knuths Studenten wurden. Bis heute einzigartig sind die Regeln für Abstände in mathematischen Formeln, andere von Knuths Entdeckungen finden inzwischen in verschiedenen Schriftsatzsystemen Verwendung.
Abstände in Formeln
Da das Hauptaugenmerk Knuths bei der Entwicklung von TeX auf hochqualitativem Textsatz für sein Buch The Art of Computer Programming lag, legte er viel Wert auf gut funktionierende Regeln für die Wahl von Abständen in mathematischen Formeln. Als Grundlage verwendete er Werke, die er für Beispielexemplare hochqualitativer mathematischer Typographie hielt: Die Bücher, die bei Addison-Wesley, dem Herausgeber von The Art of Computer Programming, gesetzt wurden – besonders die Arbeit von Hans Wolf –, Ausgaben der mathematischen Fachzeitschrift Acta Mathematica um das Jahr 1910 und ein Exemplar der niederländischen Fachzeitschrift Indigationes Mathematicae. Aus der genauen Analyse des Textsatzes in diesen Werken entwickelte Knuth einen Regelsatz für das Setzen von Abständen in TeX.[1] Während TeX nur einige grundlegende Regeln für die Abstandhaltung bereitstellt, hängen die exakten Parameter von der verwendeten Schriftart ab, die zum Formelsatz verwendet wird. Die Regeln für Knuths Computer-Modern-Schriftarten beispielsweise wurden in jahrelanger Arbeit feinabgestimmt und sind jetzt eingefroren. Als er aber andere Schriftarten wie AMS Euler zum ersten Mal verwendete, mussten neue Abstandhaltungsparameter definiert werden.[2]
Worttrennung und Blocksatz
Im Vergleich zu manuellem Schriftsatz lässt sich das Problem des Setzens im Blocksatz mit einem automatisierten System wie TeX prinzipiell leicht lösen. Ein solches System kann automatisch die Wortabstände in einer Zeile anpassen, wenn definiert wurde, an welcher Stelle ein Zeilenumbruch sinnvoll ist. Das eigentliche Problem besteht also darin, die Zeilenumbruchstellen zu finden, die den besten Gesamteindruck erzeugen. Viele Zeilenumbruchsalgorithmen verwenden einen sogenannten First-Fit-Ansatz: Die Zeilenumbrüche werden Zeile für Zeile festgelegt, und es wird kein Zeilenumbruchspunkt mehr geändert, nachdem er einmal festgelegt wurde.[3] Ein solches System kann einen Zeilenumbruchspunkt nicht danach beurteilen, welchen Effekt der Umbruch auf darauffolgende Zeilen hat. Im Gegensatz zu solchen Algorithmen zieht der Total-Fit-Algorithmus, den Knuth und Michael Plass für TeX entwickelten, alle möglichen Zeilenumbruchspunkte in einem Absatz in Betracht und findet die Kombination derer, die insgesamt das bestaussehende Arrangement hervorbringen.
Formal assoziiert der Algorithmus einen badness genannten Wert mit jedem möglichen Zeilenumbruch. Die badness wird erhöht, wenn die Wortabstände zu stark gestreckt oder gestaucht werden müssen, um eine Zeile in die richtige Länge zu bringen. Strafpunkte werden hinzuaddiert, wenn ein Zeilenumbruch besonders unerwünscht ist, beispielsweise wenn ein Wort getrennt werden muss, wenn zwei Zeilen hintereinander mit einer Worttrennung enden oder wenn eine sehr gestreckte Zeile unmittelbar auf eine sehr gestauchte folgt. Der Algorithmus findet dann den Satz von Umbruchpunkten, der eine minimale Summe der Quadrate der badness-Werte aufweist. Enthält ein Absatz n mögliche Umbruchpunkte, so müssten mit einem naiven Algorithmus 2n mögliche Zeilenumbruchskombinationen überprüft werden. Mit Methoden der Dynamischen Programmierung kann die Komplexität auf O(n2) gesenkt werden. Weitere Vereinfachungen (beispielsweise extrem unwahrscheinliche Umbruchstellen wie eine Worttrennung des ersten Wortes eines Absatzes nicht zu überprüfen) führen meist zu einer Laufzeit in der Ordnung n. Im Allgemeinen zeigte Michael Plass, dass das Problem, den besten Seitenumbruch zu finden, aufgrund der erhöhten Komplexität durch die Platzierung von Abbildungen und Tabellen NP-vollständig sein kann.[4] Ein ähnlicher Algorithmus wird verwendet, um Seitenumbrüche in Absätzen so zu platzieren, dass Hurenkinder und Schusterjungen verhindert werden.
Der Zeilenumbruchsalgorithmus von TeX wurde von mehreren anderen Programmen aufgenommen, zum Beispiel von Adobe InDesign[5] und dem GNU Unix-Kommandozeilenwerkzeug fmt.[6]
Wenn kein passender Zeilenumbruch gefunden werden kann, versucht TeX, ein Wort zu trennen. Die ursprüngliche Version von TeX verwendete einen Worttrennungsalgorithmus, der Wortpräfixe und -suffixe erkannte, bei Bedarf entfernte und Bindestriche zwischen den zwei Konsonanten einer Buchstabenkombination Vokal–Konsonant–Konsonant–Vokal einfügte, was in der englischen Sprache meistens möglich ist.[7] TeX82 verwendet einen neuen Worttrennungsalgorithmus, der von Frank Liang 1983 entwickelt wurde und Umbruchpunkten in Wörtern Prioritäten zuordnet. Zunächst wird eine Liste von Worttrennungsmustern aus einem großen Korpus getrennter Wörter generiert (solche Korpora enthalten 50.000 Wörter und mehr). Wenn TeX dann beispielsweise eine akzeptable Worttrennungsposition im Wort encyclopedia finden muss, erzeugt es eine Liste der Teilwörter von „.encyclopedia.“ (der Punkt ist ein Sonderzeichen, das Anfang und Ende des Wortes markiert). Diese Liste umfasst alle Teilwörter der Länge 1 (., e, n, c, y, usw.), der Länge 2 (.e, en, nc, usw.), bis zur Länge 14, dem Wort inklusive der Punkte selbst. TeX sucht in seiner Liste von Trennungsmustern solche Teilwörter heraus, für die es die Erwünschtheit einer Trennung errechnet hat. In unserem Fall werden 11 solcher Muster gefunden:
1c4l4 1cy 1d4i3a 4edi e3dia 2i1a ope5d 2p2ed 3pedi pedia4 y1c Für jede Wortposition errechnet TeX nun den Maximalwert aus allen passenden Mustern, was hier
- en1cy1c4l4o3p4e5d4i3a
ergibt. Die ungeraden Zahlen markieren mögliche Trennungspositionen; hier ist das Ergebnis also en-cy-clo-pe-di-a. Dieses auf Teilwörtern basierende System erlaubt die Definition sehr allgemeiner Muster wie 2i1a mit niedrigen Umbruchzahlen (gerade oder ungerade), die, wenn notwendig, durch spezifischere (längere) Muster wie 1d4i3a übergangen werden.
Durch geschickte Parameterwahl ist es möglich, Trennmuster so zu erzeugen, dass
- die Anzahl der Elemente möglichst klein ist – 1983 noch von sehr großer Bedeutung
- fast alle möglichen Trennstellen gefunden werden (über 90 %)
- der Algorithmus keine falschen Trennstellen erkennt (im Zusammenspiel mit einer Ausnahmenliste, die vom Benutzer erweitert werden kann)[8][9]
Die Nachteile des Liangschen Algorithmus zeigen sich bedauerlicherweise in Sprachen wie Deutsch, wo es eine praktisch beliebige Anzahl von Komposita gibt, die nicht bei Erzeugung der Trennmuster berücksichtigt werden können und daher oft falsch getrennt werden.
Benutzergruppen
Rund um TeX haben sich schon sehr früh Benutzergruppen organisiert, als erstes die TeX Users Group (TUG), die international agiert. Später kamen sprachbezogene und regionale Benutzergruppen hinzu wie die Deutschsprachige Anwendervereinigung TeX (DANTE) für den deutschen Sprachraum und GUTenberg für den französischen Sprachraum. Insgesamt gibt es zur Zeit etwa zwei Dutzend TeX-Benutzergruppen, die untereinander zusammenarbeiten.
Distributionen
Es gibt viele verschiedene Distributionen von TeX, die untereinander vollständig kompatibel sein sollten:
- MiKTeX ist eine TeX-Distribution (Programmsammlung) für Windows. Sie enthält alle zur Arbeit mit TeX nötigen Programme, wie LaTeX oder yap.
- TeX Live ist eine direkt von CD beziehungsweise DVD lauffähige TeX-Distribution für verschiedene Unices (unter anderen auch Linux), Mac OS X und Windows.
- teTeX ist eine von Thomas Esser erstellte TeX-Distribution für Unix. Diese Distribution wird nicht mehr weiter entwickelt (Mai 2006). Thomas Esser empfiehlt Interessenten, sich dem Projekt TeX Live zuzuwenden.
Der Verzeichnisbaum texmf, der durch die verschiedenen Installationen erzeugt wird, ist standardisiert.
Unterstützende Tools
Manche Texteditoren sind speziell zum Erstellen von TeX-Dokumenten ausgerichtet. Sie bieten meist eine Hilfe zu den Befehlen und die Möglichkeit einer Vorschau und einer Übersetzung in eine druckfähige PostScript-Datei. Beispiele sind Kile unter Linux, TeXnicCenter, WinEdt und LyX unter Microsoft Windows sowie TeXShop unter Mac OS X. Darüber hinaus bieten auch viele Texteditoren, die nicht speziell für den Umgang mit TeX entwickelt wurden, besondere Features bzgl. des Bearbeitens von TeX-Projekten. So gibt es beispielsweise für Emacs den AUCTeX-Modus, für Eclipse gibt es das Plug-in TeXlipse und auch für Vim werden viele unterstützende Scripts und Plug-ins bereitgestellt.
Quellen
- ↑ Donald E. Knuth. Questions and Answers II, TUGboat 17 (1996), 355–367. Auch gedruckt als Kapitel 32 von Digital Typography, S. 620.
- ↑ Donald E. Knuth. Typesetting Concrete Mathematics, TUGboat 10 (1989), 31–36, 342. Auch gedruckt als Kapitel 18 von Digital Typography.
- ↑ Michael P. Barnett. Computer Typesetting: Experiments and Prospects. Cambridge, Massachusetts: MIT Press, 1965.
- ↑ Donald E. Knuth und Michael F. Plass: Breaking Paragraphs Into Lines, Software – Practice and Experience 11 (1981), 1119–1184. Auch gedruckt als Kapitel 3 von Digital Typography, S. 67–155.
- ↑ Advogato. Interview of Donald E. Knuth (PDF-Datei, auch in HTML verfügbar), TUGboat 21 (2000), 103–110.
- ↑ GNU Project, GNU coreutils manual, version 6.9, 4.1 fmt: Reformat paragraph text. 2006.
- ↑ Franklin Mark Liang. Word Hy-phen-a-tion by Com-put-er, PhD-Abschlussarbeit, Department of Computer Science, Stanford University, August 1983.
- ↑ Liang, PhD-Abschlussarbeit
- ↑ The TeXbook, Appendix H: Hyphenation, S. 449–455.
Literatur
- Donald E. Knuth: Digital Typography. University of Chicago Press, 1999, ISBN 1-575-86010-4.
- Herbert Voß: Flotter Oldie. (La)TeX – 25 Jahre und kein Ende. In: c't. 9/2005. Verlag Heinz Heise, S. 172–175, ISSN 0724-8679
Weblinks
tex(1)– Linux-Manpage (Englisch)- Deutschsprachige Anwendervereinigung TeX e. V. (DANTE)
- FAQ über das Textsatzsystem TeX und DANTE
- TeX Users Group (englisch)
- Norman Walsh, Making TeX Work – freies Online-Buch
Wikimedia Foundation.