- Blockkode
-
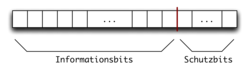 systematischer Blockcode
systematischer BlockcodeEin Blockcode ist eine Art von Kanalkodierung, gekennzeichnet dadurch, dass die benutzten Codewörter alle dieselbe Anzahl an Symbolen aus einem Alphabet (Informatik), z. B. Bits haben.
Obwohl Blockcodes häufig nicht optimal im Sinne einer minimalen mittleren Codewortlänge sind, schränkt man sich oft auf Blockcodes ein, da die Erforschung von Codes mit beliebiger Länge weitaus schwieriger ist. Eine weitere Spezialisierung stellen die linearen Codes dar.
Wichtige Parameter eines Blockcodes sind die Informationsrate (eine Kenngröße für die in einer festen Datenmenge enthaltenen Informationsmenge) sowie die Korrekturrate (Hamming-Abstand - eine Kenngröße für die Fehlerresistenz bei einer festen Datenmenge). Es ist im Allgemeinen nicht möglich, diese Eigenschaften gleichzeitig zu optimieren. Deshalb muss in der Praxis stets neu entschieden werden, welcher Blockcode den besten Kompromiss für eine bestimmte Anwendung bietet.
Die Spannung zwischen Effizienz (große Informationsrate) und Korrekturfähigkeit lässt sich auch durch den Versuch erkennen, bei einer bestimmten Anzahl Bits pro Codewort und einer bestimmten Korrekturrate (dargestellt durch den Hamming-Abstand d) die gesamte Anzahl der Codewörter zu maximieren.
Man bezeichnet allgemein C als einen (n,d,q)-Code ,falls
- A ein Alphabet mit | A | = q ist,
- für den Code
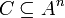 ,
, - für den Minimalabstand
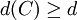 gilt.
gilt.
Betrachtet man lineare Codes, so spricht man von (n,k,d,q)-Codes, wobei k hier die Dimension von C über dem Körper
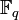 ist. n und d haben dabei die gleiche Bedeutung wie bei Blockcodes.
ist. n und d haben dabei die gleiche Bedeutung wie bei Blockcodes.Man interessiert sich also nun für Max(n,d,q):=max{ |C| : C ist (n,d,q)-Code }, da hierbei eine bei gegebenem n,d,q optimale Informationsrate erzielt wird. Siehe hierzu Singleton-Schranke (MDS-Code), Hamming-Schranke (Perfekter Code), Plotkin-Schranke, Optimaler Code.
Inhaltsverzeichnis
Definition
Formal heißt der Code
Blockcode, wobei A als Alphabet bezeichnet wird und n die Länge eines Codewortes 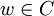 ist.
ist.Blockcodes, die aus m Informationssymbolen am Blockanfang und k Prüfsymbolen am Blockende bestehen werden Systematische Blockcodes genannt (siehe Abbildung).
Informationsrate für Blockcodes
Sei
ein Blockcode und es gelte |A|=q, das Alphabet habe also q verschiedene Elemente. Dann lautet für C die Definition der Informationsrate: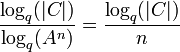 .
.
Wenn z. B. C ein binärer Code ist mit s verschiedenen Elementen, dann benötigt man höchstens log2(s)+1 Bits, um s verschiedene Codewörter zu erhalten. Die Informationsrate setzt daher die tatsächlich benötigte Anzahl an Zeichen mit der geringstmöglichen Anzahl an Zeichen ins Verhältnis.
Wenn beispielsweise die ersten k Bits eines binären Codeworts Informationsbits sind, die in alle theoretisch möglichen Kombinationen existieren, dann ist die Informationsrate:
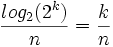 .
.
Fehlerkorrektur
Blockcodes können zur Fehlererkennung und Fehlerkorrektur bei der Übertragung von Daten über fehlerbehaftete Kanäle verwendet werden. Dabei ordnet der Sender dem zu übertragenen Informationswort der Länge m ein Codewort der Länge n zu, wobei n > m. Durch das Hinzufügen der n − m zusätzlichen Symbole entsteht Redundanz und die Informationsrate sinkt; jedoch kann der Empfänger die redundante Information nun dazu nutzen Übertragungsfehler zu erkennen und zu korrigieren.
Verwendet man beispielsweise, im Fall der Binärkodierung, die Zuordnung
Informationswort Codewort 0 000 1 111 so können empfangene Codewörter mit genau einem Bitfehler korrigiert werden, indem man mit Hilfe einer Mehrheits-Funktion das abweichende Bit umkehrt:
Fehlerhaftes Codewort Korrigiertes Codewort Zugeordnetes Informationswort 001 000 0 010 000 0 011 111 1 100 000 0 101 111 1 110 111 1 Siehe auch: Hamming-Code
Siehe auch

Wikimedia Foundation.