- ANOVA
-
Als Varianzanalyse bezeichnet man eine große Gruppe datenanalytischer und mustererkennender statistischer Verfahren, die zahlreiche unterschiedliche Anwendungen zulassen. Ihnen gemeinsam ist, dass sie Varianzen und Prüfgrößen berechnen, um Aufschlüsse über die hinter den Daten steckenden Gesetzmäßigkeiten zu erlangen. Die Varianz einer oder mehrerer Zielvariable(n) wird dabei durch den Einfluss einer oder mehrerer Einflussvariablen (Faktoren) erklärt.
Je nachdem, ob eine oder mehrere Zielvariablen vorliegen, unterscheidet man zwei Formen der Varianzanalyse:
- die univariate Varianzanalyse, nach der englischen Bezeichnung analysis of variance auch als ANOVA bezeichnet
- die multivariate Varianzanalyse, nach der englischen Bezeichnung multivariate analysis of variance auch als MANOVA bezeichnet
Je nachdem, ob ein oder mehrere Faktoren vorliegen, unterscheidet man zwischen einfaktorieller (einfacher) und mehrfaktorieller (multipler) Varianzanalyse.
Inhaltsverzeichnis
Begriffe
- Zielvariable (abhängige Variable)
- Die metrische Zufallsvariable, deren Wert durch die kategorialen Variablen erklärt werden soll. Die abhängige Variable enthält Messwerte.
- Einflussvariable (Faktor; unabhängige Variable)
- Die kategoriale Variable (= Faktor), die die Gruppen vorgibt. Ihr Einfluss soll überprüft werden.
- Die Kategorien eines Faktors heißen dann Faktorstufen. Diese Bezeichnung ist nicht identisch mit jener bei der Faktorenanalyse.
Grundidee der Varianzanalyse
Die Verfahren untersuchen, ob (und gegebenenfalls wie) sich die Erwartungswerte der metrischen Zufallsvariablen in verschiedenen Gruppen (auch Klassen) unterscheiden. Mit den Prüfgrößen des Verfahrens wird getestet, ob die Varianz zwischen den Gruppen größer ist als die Varianz innerhalb der Gruppen. Dadurch kann ermittelt werden, ob die Gruppeneinteilung sinnvoll ist oder nicht bzw. ob sich die Gruppen signifikant unterscheiden oder nicht.
Wenn sie sich signifikant unterscheiden, kann angenommen werden, dass in den Gruppen unterschiedliche Gesetzmäßigkeiten wirken. So lässt sich beispielsweise klären, ob das Verhalten einer Kontrollgruppe mit dem einer Experimentalgruppe identisch ist. Ist beispielsweise die Varianz einer dieser beiden Gruppen bereits auf Ursachen (Varianzquellen) zurückgeführt, kann bei Varianzgleichheit geschlossen werden, dass in der anderen Gruppe keine neue Wirkungsursache (z.B. durch die Experimentalbedingungen) hinzukam.
Siehe auch: Diskriminanzanalyse, Bestimmtheitsmaß
Bedeutung der Varianzanalyse
Die Varianzanalyse spielt in der Wissenschaft eine wesentliche Rolle. Sie kann als die wissenschaftlich fundierte Form der Attributierung (Ursachenzuschreibung) angesehen werden, welche Menschen in naiver Weise ständig im Alltag betreiben und dabei Häufigkeiten und Variabilität von Handlungen oder Vorgängen auf mutmaßliche Gründe zurückführen. Alltagsvorgänge, die oft gemeinsam auftreten oder unter Umgebungsveränderungen in ähnlicher Weise variieren/kovariieren, werden als kausal miteinander im Zusammenhang stehend interpretiert. So kann die Häufigkeit (Intensität, Art und Weise usw.), mit der eine Person ihre Hände wäscht, mit der Häufigkeit in Bezug gesetzt werden, mit der sie schmutzige Tätigkeiten ausführt (z.B. Automechaniker). Im Alltag wird dann naiv der Fehlschluss gezogen, dass eine Person, die gerade ihre Hände wäscht, zuvor eine Verschmutzung hatte, die als Grund für das Händewaschen angesehen wird (eine sog. Abduktion). Diese Ursachenzuschreibung kann jedoch falsch sein, da es auch andere Gründe für Händewaschen gibt.
Der statistischen Varianzanalyse kommt deshalb eine wesentliche Rolle zu, da sie das Alltagsdenken in konsequenter Form fortsetzt. Viele andere multivariate Verfahren setzen das Alltagsdenken nicht fort, sondern basieren auf künstlich entwickelten Modellannahmen.
Die statistische Signifikanz einer ermittelten Gruppeneinteilung lässt sich anhand der F-Verteilung testen. Die Werte in dieser Verteilung sind die Prüfgröße der Varianzanalyse.
Beispiele für die Anwendung der Varianzanalyse sind die Untersuchung der Wirksamkeit von Medikamenten in der Medizin und die Untersuchung des Einflusses von Düngemitteln auf den Ertrag von Anbauflächen in der Landwirtschaft.
Voraussetzungen der Varianzanalyse
Die Anwendung jeder Form der Varianzanalyse ist an Voraussetzungen gebunden, deren Vorliegen vor jeder Berechnung geprüft werden muss. Erfüllen die Datensätze diese Voraussetzungen nicht, so sind die Ergebnisse unbrauchbar. Die Voraussetzungen sind je nach Anwendung etwas unterschiedlich, allgemein gelten folgende:
- Varianzhomogenität der Stichprobenvariablen
- Normalverteilung der Stichprobenvariablen
Die Überprüfung erfolgt mit anderen Tests außerhalb der Varianzanalyse, die allerdings heute standardmäßig in Statistik-Programmen als Option mitgeliefert werden. Die Normalverteilung kann beispielsweise für jede Variable mit dem Kolmogorow-Smirnow-Test überprüft werden. Wenn diese Voraussetzungen nicht erfüllt sind, bieten sich verteilungsfreie, nicht-parametrische (verteilungsfreie) Verfahren an, die robust sind, aber weniger genau rechnen.
- nicht-parametrische Verfahren:
- für zwei Stichproben (t-Test Alternativen):
- gepaarte Sp.: Wilcoxon-Vorzeichen-Rang-Test
- unabhängige Sp.: Mann-Whitney-U-Test auch Wilcoxon-Mann-Whitney-Test, U-Test, Mann-Whitney-Wilcoxon, (MWW)-Test oder Wilcoxon-Rangsummentest genannt.
- für zwei Stichproben (t-Test Alternativen):
-
- für drei oder mehr Stichproben:
- gepaarte Daten: Friedman-Test
- ungepaarte Daten: Kruskal-Wallis-Test, Jonckheere-Terpstra-Test, Umbrella-Test
- für drei oder mehr Stichproben:
Einfaktorielle ANOVA
Bei einer einfaktoriellen Varianzanalyse untersucht man den Einfluss einer unabhängigen Variable (Faktor) mit k verschiedenen Ausprägungen auf eine abhängige Variable, welche die Messwerte enthält.
Voraussetzungen
- Die Fehlerkomponenten müssen normalverteilt sein. Fehlerkomponenten bezeichnen die jeweiligen Varianzen (Gesamt-, Treatment- und Fehlervarianz). Die Gültigkeit dieser Voraussetzung setzt gleichzeitig eine Normalverteilung der Messwerte in der jeweiligen Grundgesamtheit voraus.
- Die Fehlervarianzen müssen zwischen den Gruppen (also den k Faktorstufen) gleich bzw. homogen sein (Homoskedastizität).
- Die Messwerte bzw. Faktorstufen müssen unabhängig voneinander sein.
Beispiel
Diese Form der Varianzanalyse ist angezeigt, wenn beispielsweise untersucht werden soll, ob Rauchen einen Einfluss auf die Aggressivität hat. Rauchen ist hier eine unabhängige Variable, welche in drei Ausprägungen (k=3 Faktorstufen) unterteilt werden kann: Nichtraucher, schwache Raucher und starke Raucher. Die durch einen Fragebogen erfasste Aggressivität ist die abhängige Variable. Zur Durchführung der Untersuchung werden die Versuchspersonen den drei Gruppen zugeordnet. Danach wird der Fragebogen vorgelegt, mit dem die Aggressivität erfasst wird.
Hypothesen
Die Nullhypothese einer einfaktoriellen Varianzanalyse lautet:
H0:μ1 = μ2 = ... = μk
Die Alternativhypothese lautet:
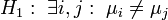
Die Nullhypothese besagt demnach, dass zwischen den Mittelwerten der Gruppen (die den Faktorausprägungen bzw. Faktorstufen entsprechen) kein Unterschied besteht. Die Alternativhypothese besagt, dass zwischen mindestens zwei Mittelwerten ein Unterschied besteht. Wenn wir beispielsweise k=fünf Faktorstufen haben, dann ist die Alternativhypothese bestätigt, wenn sich mindestens zwei der Gruppenmittelwerte unterscheiden. Es können sich aber auch drei Mittelwerte oder vier oder alle fünf deutlich voneinander unterscheiden.
Wird die Nullhypothese verworfen, liefert die Varianzanalyse also weder Aufschluss darüber, zwischen wievielen noch zwischen welchen Faktorstufen ein Unterschied besteht. Wir wissen dann nur mit einer bestimmten Wahrscheinlichkeit (siehe Signifikanzniveau), dass mindestens zwei Ausprägungen einen bedeutsamen Unterschied aufweisen.
Man kann nun fragen, ob es zulässig wäre, mit verschiedenen t-Tests jeweils paarweise Einzelvergleiche zwischen den Mittelwerten durchzuführen. Vergleicht man mit der Varianzanalyse nur zwei Gruppen (also zwei Mittelwerte), dann führen t-Test und Varianzanalyse zum gleichen Ergebnis. Liegen jedoch mehr als zwei Gruppen vor, ist die Überprüfung der globalen Nullhypothese der Varianzanalyse über paarweise t-Tests nicht zulässig - es kommt zur sogenannten Alphafehler-Kumulierung.
Aus diesem Grund ist es möglich, nach einem signifikanten ANOVA-Ergebnis anhand multipler Vergleichstechniken zu überprüfen, bei welchem Mittelwertspaar der oder die Unterschiede liegen. Beispiele solcher Vergleichstechniken sind der Bonferroni-Test und der Scheffé-Test. Der Vorteil dieser Verfahren liegt darin, dass sie den Aspekt der Alphainflation berücksichtigen.
Grundgedanken der Rechnung
- Bei der Berechnung der Varianzanalyse berechnet man zunächst die beobachtete Gesamtvarianz in allen Gruppen. Dazu fasst man alle Messwerte aus allen Gruppen zusammen, errechnet den Gesamtmittelwert und die Gesamtvarianz.
- Dann möchte man den Varianzanteil der Gesamtvarianz, der allein auf den Faktor zurückgeht, ermitteln. Wenn die gesamte beobachtete Varianz auf den Faktor zurückginge, dann müssten alle Messwerte in einer Faktorstufe gleich sein - dann dürften nur Unterschiede zwischen den Gruppen bestehen. Da alle Messwerte innerhalb einer Gruppe dieselbe Faktorausprägung aufweisen, müssten sie folglich alle den gleichen Wert haben, da der Faktor die einzige varianzgenerierende Quelle wäre. In der Praxis werden sich aber auch Messwerte innerhalb einer Faktorstufe unterscheiden. Diese Unterschiede innerhalb der Gruppen müssen also von anderen Einflüssen stammen (entweder Zufall oder sogenannten Störvariablen).
- Um nun auszurechnen, welche Varianz allein auf die Ausprägungen des Faktors zurückgeht, stellt man seine Daten für einen Moment gewissermaßen „ideal“ um: Man weist allen Messwerten innerhalb einer Faktorstufe den Mittelwert der jeweiligen Faktorstufe zu. Somit macht man alle Werte innerhalb einer Faktorstufe gleich, und der einzige Unterschied besteht nun noch zwischen den Faktorstufen. Nun errechnet man mit diesen „idealisierten“ Daten erneut die Varianz. Diese kennzeichnet die Varianz, die durch den Faktor zustande kommt ("Treatment-Varianz").
- Teilt man die Treatmentvarianz durch die Gesamtvarianz, erhält man den relativen Anteil, der auf den Faktor zurückzuführenden Varianz.
- Zwischen der Gesamtvarianz und der Treatmentvarianz besteht in aller Regel eine Diskrepanz - die Gesamtvarianz ist größer als die Treatmentvarianz. Die Varianz, die nicht auf den Faktor (das "Treatment") zurückzuführen ist, bezeichnet man als Fehlervarianz. Diese beruht entweder auf Zufall oder anderen, nicht untersuchten Variablen (Störvariablen).
- Die Fehlervarianz lässt sich berechnen, indem man seine Daten erneut umstellt: Man errechnet für jeden einzelnen Messwert dessen Abweichung vom jeweiligen Gruppenmittelwert seiner Faktorstufe. Daraus berechnet man erneut die gesamte Varianz. Diese kennzeichnet dann die Fehlervarianz.
- Eine wichtige Beziehung zwischen den Komponenten ist die Additivität der Quadratsummen. Als Quadratsummen bezeichnet man den Teil der Varianzformel, der im Zähler steht. Lässt man also bei der Berechnung der Treatmentvarianz den Nenner (die Freiheitsgrade) weg, erhält man die Treatmentquadratsumme. Die Gesamtquadratsumme (also Gesamtvarianz ohne Nenner) ergibt sich aus der Summe von Treatment- und Fehlerquadratsumme.
- Die letztendliche Signifikanzprüfung erfolgt über einen „gewöhnlichen“ F-Test. Man kann mathematisch zeigen, dass bei Gültigkeit der Nullhypothese der Varianzanalyse gleichzeitig gilt, dass Treatment- und Fehlervarianz gleich sein müssen. Mit einem F-Test kann man die Nullhypothese überprüfen, dass zwei Varianzen gleich sind, indem man den Quotienten aus ihnen bildet.
- Im Falle der Varianzanalyse bildet man den Quotienten aus Treatmentvarianz, geteilt durch Fehlervarianz. Dieser Quotient ist F-verteilt mit (k-1) Zählerfreiheitsgraden und k×(n-1) bzw. N-k Nennerfreiheitsgraden (k ist die Anzahl der Gruppen, N ist die Gesamtzahl aller Versuchspersonen, n ist die jeweilige Zahl der Versuchspersonen pro Faktorstufe).
- In Tabellen der F-Verteilung kann man dann den entsprechenden F-Wert mit entsprechenden Freiheitsgraden nachschlagen und liest ab, wieviel Prozent der F-Verteilungsdichte dieser Wert „abschneidet“. Einigen wir uns beispielsweise vor der Durchführung der Varianzanalyse auf ein Signifikanzniveau von 5 %, dann müsste der F-Wert mindestens 95 % der F-Verteilung auf der linken Seite abschneiden. Ist dies der Fall, dann haben wir ein signifikantes Ergebnis und können die Nullhypothese auf dem 5 %-Niveau verwerfen.
Mathematisches Modell
Das Modell in Effektdarstellung lautet:
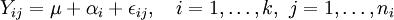
Yij: Zielvariable; annahmegemäß in den Gruppen normalverteilt k: Anzahl der Faktorstufen des betrachteten Faktors ni: Stichprobenumfänge für die einzelnen Faktorstufen μ: Mittelwert der Gesamtstichprobe αi: Effekt der i-ten Faktorstufe εij: Störvariablen, unabhängig und normalverteilt mit Erwartungswert 0 und gleicher Varianz.
Beispielrechnung einer einfachen Varianzanalyse
Bei dem folgenden Beispiel handelt es sich um eine einfache Varianzanalyse mit zwei Gruppen (auch Zwei-Stichproben F-Test). In einem Versuch erhalten zwei Gruppen von Tieren (k = 2) unterschiedliche Nahrung. Nach einer gewissen Zeit wird ihr Gewicht mit folgenden Werten gemessen:
- Gruppe 1: 45, 23, 55, 32, 51, 91, 74, 53, 70, 84 (Anzahl der Tiere n1 = 10)
- Gruppe 2: 64, 75, 95, 56, 44, 130, 106, 80, 87, 115 (Anzahl der Tiere n2 = 10)
Es soll untersucht werden, ob die unterschiedliche Nahrung einen signifikanten Einfluss auf das Gewicht hat. Der Mittelwert und die Varianz (hier "Schätzwert" , Stichprobenvarianz) der beiden Gruppen betragen
Das zugrunde liegende Wahrscheinlichkeitsmodell setzt voraus, dass die Gewichte der Tiere normalverteilt sind und pro Gruppe dieselbe Varianz aufweisen. Die zu testende Nullhypothese ist
- H0: "Die Mittelwerte der beiden Gruppen sind gleich"
Offensichtlich unterscheiden sich die Mittelwerte
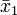 und
und 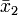 . Diese Abweichung könnte jedoch auch im Bereich der natürlichen Schwankungen liegen. Um zu prüfen, ob die Unterscheidung signifikant ist, wird eine Testgröße F mit bekannter Wahrscheinlichkeitsverteilung berechnet. Dazu wird zunächst die gemeinsame Varianz varg bestimmt:
. Diese Abweichung könnte jedoch auch im Bereich der natürlichen Schwankungen liegen. Um zu prüfen, ob die Unterscheidung signifikant ist, wird eine Testgröße F mit bekannter Wahrscheinlichkeitsverteilung berechnet. Dazu wird zunächst die gemeinsame Varianz varg bestimmt:Anmerkung: Manchmal wird bei dieser Berechnung auch die um eins verringerte Größe der Stichproben verwendet, also ni − 1 statt ni ("Schätzwert"). Mit Hilfe der gemeinsamen Varianz berechnet sich die Testgröße F als:
Die Größe F ist nach dem zugrunde liegenden Modell eine Zufallsvariable mit einer Fk − 1,n − k-Verteilung, wobei k die Anzahl der Gruppen (Faktorstufen) und n die Anzahl der Messwerte sind. Die Indizes werden als Freiheitsgrade bezeichnet. Der Wert der F-Verteilung für gegebene Freiheitsgrade (F-Quantil) kann in einer Fisher-Tafel nachgeschlagen werden. Dabei muss noch ein gewünschtes Signifikanzniveau (die Irrtumswahrscheinlichkeit) angegeben werden. Im vorliegenden Fall ist
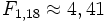 das F-Quantil zur Irrtumswahrscheinlichkeit 5 %. Das heißt, dass bei allen Werten der Testgröße F bis 4,41 die Nullhypothese nicht abgelehnt werden kann. Da 6,21 > 4,41, kann die Nullhypothese bei den vorliegenden Werten abgelehnt werden.
das F-Quantil zur Irrtumswahrscheinlichkeit 5 %. Das heißt, dass bei allen Werten der Testgröße F bis 4,41 die Nullhypothese nicht abgelehnt werden kann. Da 6,21 > 4,41, kann die Nullhypothese bei den vorliegenden Werten abgelehnt werden.Es kann also davon ausgegangen werden, dass die Tiere in den beiden Gruppen im Mittel wirklich ein unterschiedliches Gewicht aufweisen. Die Wahrscheinlichkeit, sich damit zu irren liegt unter 5 %.
Zweifaktorielle ANOVA
Die zweifaktorielle Varianzanalyse berücksichtigt zur Erklärung der Zielvariablen zwei Faktoren (Faktor A und Faktor B).
Beispiel
Diese Form der Varianzanalyse ist z. B. bei Untersuchungen angezeigt, welche den Einfluss von Rauchen und Kaffeetrinken auf die Nervosität darstellen wollen. Rauchen ist hier der Faktor A, welcher in zwei Ausprägungen (Faktorstufen) unterteilt werden kann: raucht gerade und raucht gerade nicht. Der Faktor B kann der Kaffeegenuss in einer bestimmten Situation sein. Die durch eine peripherphysiologische Messung erfasste Nervosität ist die abhängige Variable. Zur Durchführung der Untersuchung werden die Raucher in zwei Gruppen geordnet, wobei eine der Gruppen Kaffee getrunken hat. Jede dieser beiden Gruppen wird ihrerseits in zwei Hälften geteilt, von denen eine Zigaretten zu rauchen bekommt. Dabei wird die Messung der Nervosität durchgeführt, die metrische Daten liefert.
Grundgedanken der Rechnung
Das Modell (für den Fall mit festen Effekten) in Effektdarstellung lautet:
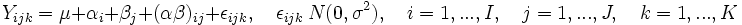
Yijk: Zielvariable; annahmegemäß in den Gruppen normalverteilt I: Anzahl der Faktorstufen des ersten Faktors (A) J: Anzahl der Faktorstufen des zweiten Faktors (B) K: Anzahl der Beobachtungen pro Faktorstufe (hier für alle Kombinationen von Faktorstufen gleich) αi: Effekt der i-ten Faktorstufe des Faktors A βj: Effekt der j-ten Faktorstufe des Faktors B (αβ)ij: Interaktion (Wechselwirkung) der Faktoren auf der Faktorstufenkombination (i,j). Die Interaktion beschreibt einen besonderen Effekt, der nur auftritt, wenn die Faktorstufenkombination (i,j) vorliegt. εijk: Störvariablen, unabhängig und normalverteilt mit Erwartungswert 0 und gleichen Varianzen.
Mehrfaktorielle ANOVA mit mehr als zwei Faktoren
Auch mehrere Faktoren sind möglich. Allerdings steigt der Datenbedarf für eine Schätzung der Modellparameter mit der Anzahl der Faktoren stark an. Auch die Darstellungen des Modells (z.B. in Tabellen) werden mit zunehmender Anzahl der Faktoren unübersichtlicher. Mehr als drei Faktoren können nur noch schwer dargestellt werden.
Literatur
- Fahrmeir u.A. (Hrsg): Multivariate statistische Verfahren. Walter de Gruyter, 1996. ISBN 3-11-013806-9
- Fahrmeir u.A.: Statistik - Der Weg zur Datenanalyse. Springer, 1999
- Hartung/Elpelt: Multivariate Statistik: Lehr- und Handbuch der angewandten Statistik. Oldenbourg, 1999. ISBN 3-486-25287-9
- Backhaus u.A.: Multivariate Analysemethoden. Eine anwendungsorientierte Einführung. Springer, 2006. ISBN 3-540-27870-2
Siehe auch
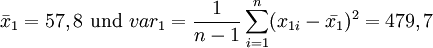
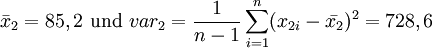
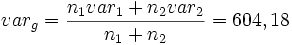
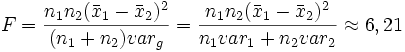
Wikimedia Foundation.