- Delta-Methode
-
Ein statistischer Test dient in der mathematischen Statistik dazu, anhand vorliegender Beobachtungen eine begründete Entscheidung über die Gültigkeit oder Ungültigkeit einer Hypothese zu treffen. Formal ist ein Test also eine mathematische Funktion. Da die vorhandenen Daten Realisationen von Zufallsvariablen sind, lässt sich niemals mit Sicherheit sagen, ob eine Hypothese stimmt oder nicht. Man versucht daher, die Wahrscheinlichkeiten für Fehlentscheidungen zu kontrollieren, was einem Test zu einem vorgegebenen Signifikanzniveau entspricht. Wir sprechen daher auch von einem Hypothesentest oder auch Signifikanztest.
Interpretation eines statistischen Tests
Ein statistisches Testverfahren lässt sich im Prinzip mit einem Gerichtsverfahren vergleichen. Es wird immer von der Unschuld eines Verdächtigen ausgegangen, und so lange große Zweifel an den Belegen für ein tatsächliches Vergehen bestehen, wird ein Angeklagter freigesprochen. Nur wenn die Indizien für die Schuld eines Angeklagten deutlich überwiegen, kommt es zu einer Verurteilung.
Es gibt demnach zu Beginn des Verfahrens die beiden Hypothesen H0 „der Verdächtige ist unschuldig“ und H1 „der Verdächtige ist schuldig“. Erstere nennt man Nullhypothese, von ihr wird vorläufig ausgegangen. Die zweite nennt man Alternativhypothese. Sie ist diejenige, die zu „beweisen“ versucht wird.
Um einen Unschuldigen nicht zu schnell zu verurteilen, wird die Hypothese der Unschuld erst dann verworfen, wenn ein Irrtum sehr unwahrscheinlich ist. Man spricht auch davon, die Wahrscheinlichkeit für einen Fehler erster Art (also das Verurteilen eines Unschuldigen) zu kontrollieren. Naturgemäß wird durch dieses unsymmetrische Vorgehen die Wahrscheinlichkeit für einen Fehler zweiter Art (also das Freisprechen eines Schuldigen) „groß“. Aufgrund der stochastischen Struktur des Testproblems lassen sich wie in einem Gerichtsverfahren Fehlentscheidungen grundsätzlich nicht vermeiden. Man versucht in der Statistik allerdings optimale Tests zu konstruieren, die die Fehlerwahrscheinlichkeiten minimieren.
Ein einführendes Beispiel
Es soll versucht werden, einen Test auf Hellsehfähigkeiten zu entwickeln.
Einer Testperson wird 25-mal die Rückseite einer rein zufällig gewählten Spielkarte gezeigt und sie wird danach gefragt, zu welcher der vier Farben (Kreuz, Pik, Herz, Karo) die Karte gehört. Die Anzahl der Treffer nennen wir X.
Da die Hellsehfähigkeiten der Person getestet werden sollen, gehen wir vorläufig von der Nullhypothese aus, die Testperson sei nicht hellsehend. Die Alternativhypothese lautet entsprechend: Die Testperson ist mehr oder weniger hellseherisch begabt.
Was bedeutet das für unseren Test? Wenn die Nullhypothese richtig ist, wird die Testperson nur versuchen können, die jeweilige Farbe zu erraten. Für jede Karte gibt es natürlich eine Wahrscheinlichkeit von 1/4, richtig zu antworten. Ist die Alternativhypothese richtig, hat die Person für jede Karte eine größere Wahrscheinlichkeit als 1/4. Wir nennen die Wahrscheinlichkeit einer richtigen Vorhersage p.
Die Hypothesen lauten dann:
und
Wenn die Testperson alle 25 Karten richtig benennt, werden wir sie als Hellseher betrachten und natürlich die Nullhypothese ablehnen. Und mit 24 oder 23 Treffern auch. Andererseits gibt es bei nur 5 oder 6 Treffern keinen Grund dazu. Aber was wäre mit 12 Treffern? Was ist mit 17 Treffern? Wo liegt die kritische Anzahl an Treffern c, von der an wir nicht mehr glauben können, es seien reine Zufallstreffer?
Wie bestimmen wir also den kritischen Wert c? Man sieht leicht ein, dass man mit c = 25 (also dass wir nur hellseherische Fähigkeiten erkennen wollen, wenn alle Karten richtig erkannt worden sind) deutlich kritischer ist als mit c = 10. Im ersten Fall wird man kaum eine Person als Hellseher ansehen, im zweiten Fall einige mehr.
In der Praxis kommt es also darauf an, wie kritisch man genau sein will, also wie oft man eine Fehlentscheidung erster Art zulässt. Mit c = 25 ist die Wahrscheinlichkeit einer solchen Fehlentscheidung:
also sehr klein. Es ist die Wahrscheinlichkeit, dass die Testperson rein zufällig 25 mal richtig geraten hat.
Weniger kritisch, mit c = 10, erhalten wir mit
eine wesentlich größere Wahrscheinlichkeit.
Vor dem Test wird eine Wahrscheinlichkeit für den Fehler erster Art festgesetzt. Typisch sind Werte zwischen 0,1 % und 5 %. Abhängig davon lässt sich (hier im Falle eines Signifikanzniveaus von 1 %) dann c so bestimmen, dass
gilt. Unter allen Zahlen c, die diese Eigenschaft erfüllen, wird man zuletzt c als die kleinste Zahl wählen, die diese Eigenschaft erfüllt, um die Wahrscheinlichkeit für den Fehler zweiter Art klein zu halten. In diesem konkreten Beispiel folgt: c = 12.
Mögliche Fehlentscheidungen
Auch wenn es wünschenswert ist, dass der Test aufgrund der vorliegenden Daten „richtig“ entscheidet, besteht die Möglichkeit von Fehlentscheidungen. Im mathematischen Modell bedeutet dies, dass man bei richtiger Nullhypothese und Entscheidung für die Alternative einen Fehler 1. Art (α-Fehler) begangen hat. Falls man die Nullhypothese bestätigt sieht, obwohl sie nicht stimmt, begeht man einen Fehler 2. Art (β-Fehler).
In der statistischen Praxis macht man aus diesem vordergründig symmetrischen Problem ein unsymmetrisches: Man legt also ein Signifikanzniveau α fest, das eine obere Schranke für die Wahrscheinlichkeit eines Fehlers erster Art liefert. Tests mit dieser Eigenschaft heißen Test zum Niveau α. Im Anschluss daran versucht man, einen optimalen Test zum vorgegebenen Niveau dadurch zu erhalten, dass man unter allen Tests zum Niveau α einen sucht, der die geringste Wahrscheinlichkeit für einen Fehler 2. Art aufweist.
Die formale Vorgehensweise
Generell geht man bei der Konstruktion eines Tests in folgenden Schritten vor:
- Formulierung einer Nullhypothese H0 und ihrer Alternativhypothese H1
- Berechnung einer Testgröße oder Teststatistik T (Wert der Beobachtung tobs) aus der Stichprobe (je nach Testverfahren etwa den t-Wert oder U oder H oder χ2…).
- Bestimmung des kritischen Bereiches K zum Signifikanzniveau α, das vor Realisation der Stichprobe feststehen muss. Der kritische Bereich wird aus den unter der Nullhypothese nur mit geringer Wahrscheinlichkeit auftretenden Werten der Teststatistik gebildet.
- Treffen der Testentscheidung:
- Liegt tobs nicht in K, so wird H0 beibehalten.
- Liegt tobs in K, so lehnt man H0 zugunsten von H1 ab.
Neyman-Pearson-Tests
Optimale Tests existieren in parametrischen Modellen nur für bestimmte Hypothesen. Im einfachsten Fall zweier Punkthypothesen H0:θ = θ0 und H1:θ = θ1 wählt man als Test einen Likelihood-Quotienten-Test, der die Nullhypothese ablehnt, falls
gilt. Dieser Test ist gleichmäßig bester Test zum Niveau α.
Neyman-Pearson-Tests lassen sich auf einseitige Hypothesen der Form
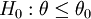 und H1:θ > θ0 ausdehnen, falls die Verteilungsfamilie einen monotonen Dichtequotienten besitzt.
und H1:θ > θ0 ausdehnen, falls die Verteilungsfamilie einen monotonen Dichtequotienten besitzt.Asymptotisches Verhalten des Tests
In den meisten Fällen ist die exakte Wahrscheinlichkeitsverteilung der Teststatistik unter der Nullhypothese nicht bekannt. Man steht also vor dem Problem, dass kein kritischer Bereich zum vorgegebenen Niveau festgelegt werden kann. In diesen Fällen erweitert man die Klasse der zulässigen Tests auf solche, die asymptotisch das richtige Niveau besitzen. Formal bedeutet dies, dass man den Bereich K so wählt, dass für alle
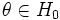 die Bedingung
die Bedingungerfüllt ist. In der Regel erhält man solche asymptotischen Tests via Normalapproximation, man versucht also, die Teststatistik so zu transformieren, dass sie gegen eine Normalverteilung konvergiert.
Einfache Beispiele hierfür sind der einfache und doppelte t-Test für Erwartungswerte. Hier folgt die asympotische Verteilung direkt aus dem Zentralen Grenzwertsatz in der Anwendung auf das arithmetische Mittel. Daneben gibt es aber eine Reihe weiterer statistischer Methoden, die die Herleitung der asymptotischen Normalverteilung auch für kompliziertere Funktionale erlauben. Hierunter fällt die Deltamethode für nichtlineare, differenzierbare Transformationen asymptotisch Normalverteilter Zufallsvariablene beruht:
Sei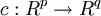 eine differenzierbare Funktion und sei ein Schätzer
eine differenzierbare Funktion und sei ein Schätzer 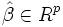
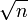 -normalverteilt mit Kovarianzmatrix V, dann hat
-normalverteilt mit Kovarianzmatrix V, dann hat 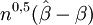 folgende Verteilung:
folgende Verteilung: 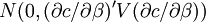 .
.Ferner hat die nichtparametrische Deltamethode (auch: Einflussfunktionsmethode) einige Fortschritte gebracht:
Sei T(F) ein Funktional, das von der Verteilung F abhängt. Sei
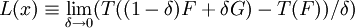 die Gateux-Ableitung der Statistik bei F (Einflussfunktion) und sei T Hadamard-differenzierbar bezüglich
die Gateux-Ableitung der Statistik bei F (Einflussfunktion) und sei T Hadamard-differenzierbar bezüglich 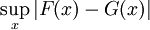 , dann hat
, dann hat 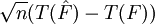 folgende Verteilung:
folgende Verteilung: 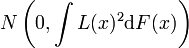 .
.Die Deltamethode erlaubt Normalverteilungsapproximationen für nichtlineare, differenzierbare Transformationen (asymptotisch) normalverteilter Zufallsvariablen, während die Einflussfunktionsmethode solche Approximationen für viele interessante Charakteristika einer Verteilung zulässt. Darunter fallen u. a. die Momente (also etwa: Varianz, Kurtosis usw.) aber auch Funktionen dieser Momente (etwa: Korrelationskoeffizient).
Eine wichtige weitere Anforderung an einen guten Test ist, dass er bei wachsendem Stichprobenumfang empfindlicher wird. In statistischen Termini bedeutet dies, dass bei Vorliegen einer konsistenten Teststatistik die Wahrscheinlichkeit dafür steigt, dass die Nullhypothese auch tatsächlich zu Gunsten der Alternative verworfen wird, falls sie nicht stimmt. Speziell wenn der Unterschied zwischen dem tatsächlichen Verhalten der Zufallsvariablen und der Hypothese sehr gering ist, wird er erst bei einem entsprechend großen Stichprobenumfang entdeckt. Ob diese Abweichungen jedoch von praktischer Bedeutung sind und überhaupt den Aufwand einer großen Stichprobe rechtfertigen, hängt von dem zu untersuchenden Aspekt ab.
Problem der Modellwahl
Die meisten mathematischen Resultate beruhen auf Annahmen, die bezüglich bestimmter Eigenschaften der beobachteten Zufallsvariablen gemacht werden. Je nach Situation werden verschiedene Teststatistiken gewählt, deren (asymptotische) Eigenschaften wesentlich von den Forderungen an die zu Grunde liegende Verteilungsfamilie abhängen. In der Regel müssen diese Modellannahmen zuvor empirisch überprüft werden, um überhaupt angewendet werden zu können. Kritisch ist dabei vor allem, dass die typischen Testverfahren strengen Voraussetzungen unterworfen sind, die in der Praxis selten erfüllt sind.
Parametrische und Nicht-parametrische Tests
Man unterscheidet parametrische und nicht-parametrische (parameterfreie) Tests
Parametrische Tests (parametrisches Prüfverfahren)
Bei Parametertests interessieren konkrete Werte wie Varianz oder Mittelwert. Ein parametrisches Prüfverfahren macht also Aussagen über Grundgesamtheitsparameter oder die in der Verteilungsfunktion einer Untersuchungsvariablen auftretenden Konstanten. Dazu müssen alle Parameter der GG bekannt sein (was oft nicht gegeben ist). Bei einem Parametertest hat jede der denkbaren Stichproben die gleiche Realisationschance. Parametrische Tests gehen davon aus, dass die beobachteten Stichprobendaten einer Grundgesamtheit entstammen, in der die Variablen oder Merkmale ein bestimmtes Skalenniveau und eine bestimmte Wahrscheinlichkeitsverteilung aufweisen, häufig Intervallskalenniveau und Normalverteilung. In diesen Fällen ist man also daran interessiert, Hypothesen über bestimmte Parameter der Verteilung zu testen.
Sofern die gemachten Verteilungannahmen nicht stimmen, sind die Ergebnisse des Tests in den meisten Fällen unbrauchbar. Speziell lässt sich die Wahrscheinlichkeit für einen Fehler zweiter Art nicht mehr sinnvoll minimieren. Man spricht dann davon, dass für viele Alternativen die power sinkt!
Nicht-parametrische Tests
Bei parameterfreien Tests (auch nichtparametrische Tests oder Verteilungstests genannt) wird der Typ der Zufallsverteilung überprüft: Man entscheidet, ob eine aus n Beobachtungen oder Häufigkeitsverteilungen bestehende Nullhypothese, die man aus einer Zufallsstichprobe gezogen hat, mit einer Null-Hypothese vereinbar ist, die man über die Verteilung in der Grundgesamtheit aufgestellt hat. Nicht-parametrische Tests kommen also mit anderen Vorannahmen aus, die Menge der für Hypothese und Alternative zugelassenen Verteilungen lässt sich nicht durch einen Parameter beschreiben.
Typische Beispiele sind Tests auf eine bestimmte Verteilungsfunktion wie der Kolmogorow-Smirnow-Test oder der Wilcoxon-Test zum Vergleich der Mediane zweier Stichproben.
Da jedoch parametrische Tests trotz Verletzung ihrer Annahmen häufig eine bessere Power bieten als nicht-parametrische, kommen letztere eher selten zum Einsatz.
Wichtige Tests
- Anpassungstest oder Verteilungstest: Hier wird geprüft, ob vorliegende Daten einer bestimmten Verteilung entstammen. Anpassungstests prüfen Hypothesen über die Verteilung einer Zufallsvariablen etwa H0: F(x)=F0(X), sie vergleichen beobachtete Verteilungen in einer Stichprobe mit einer erwarteten Verteilung. Der Anpassungstest prüft also, mit welcher Wahrscheinlichkeit eine Stichprobe aus einer Grundgesamtheit stammen kann, für die die erwartete Verteilung gilt. Die einfachste Form ist der Binominaltest.
Besondere Formen dieser Tests sind:
- Multipler Test: Verwendet man etwa anstelle eines H-Tests mit mehr als zwei unabhängigen Stichproben mehrere U-Tests als Einzeltests, so werden diese Einzeltests als multipler Test angesehen. Zu beachten ist hierbei besonders, dass bei den hintereinandergeschalteten Einzeltests sich die Wahrscheinlichkeit des Fehlers 1. Art mit der Anzahl des Tests vergrößert. Bei einem Vergleich muss dies unbedingt berücksichtigt werden.
- Konservativer Test: Bei einem konservativen Test ist die Prüfvariable diskret verteilt (etwa U-Test). Es gibt für ein vorgegebenes Signifikanzniveau keine Werte zum Beispiel für ur, die die Gleichung P(uur)=5 % erfüllen, deshalb ersetzt man die Gleichung durch die Ungleichung P(uur)%. Man wählt also generell als Rückweisungspunkt jenen Wert, der zu einem Signifikanzniveau von höchsten führt. Das vorgegebene Signifikanzniveau kann also praktisch erheblich unterschritten werden. Man verhält sich konservativ und begünstigt die Annahme der Nullhypothese.
- Exakter Test: Ein exakter Test ist ein Test, der für die zu testende Prüfvariable die exakt zuständige Stichprobenverteilung verwendet. Ein exakter Test approximiert also nicht. Exakte Test sind etwa der Fisher-Test, der Binomial-Test, der McNemar-Test. Nicht exakt arbeitet zum Beispiel ein Test, bei dem man nach dem Zentralen Grenzwert-Theorem die Normalverteilung approximativ für eine Binomialverteilung verwendet.
- Sequentieller Test: Bei einem sequentiellen Test ist der Stichprobenumfang nicht vorgegeben. Vielmehr wird bei der laufenden Datenerfassung für jede neue Beobachtung ein Test durchgeführt, ob man aufgrund der bereits erhobenen Daten eine Entscheidung für oder gegen die Nullhypothese treffen kann (siehe Sequential Probability Ratio Test).
Tests Kurzbeschreibung Verteilungsanpassungstests χ2-Anpassungstest Test einer Stichprobe auf Zugehörigkeit zu einer Verteilung Kolmogorow-Smirnow-Test Test einer Stichprobe auf Zugehörigkeit zu einer Verteilung Shapiro-Wilk-Test Test einer Stichprobe auf Zugehörigkeit zur Normalverteilung Parametrische Tests t-Tests (einfach, doppelt, doppelt mit gepaarten (=verbundenen, abhängigen) Stichproben) Test auf Erwartungswert; Vergleich zweier Erwartungswerte; Test auf Korrelation; Signifikanztest von Regressionskoeffizienten Korrelationstest (letztlich ein t-Test, s.o.) Test auf linearen Zusammenhang zweier metrischer Variablen F-Test Vergleich zweier Varianzen; Modelltest der Regressionsanalyse chi2-Test von Bartlett Vergleich von mehr als zwei Varianzen Test von Levene Test auf Homogenität von Varianzen zwischen Gruppen Verteilungsfreie (nichtparametrische) Tests χ2Unabhängigkeitstest Prüfung der Unabhängigkeit zweier Merkmale Test von Cochran/Cochrans Q Test auf Gleichverteilung mehrerer verbundener dichotomer Variablen Kendalls Konkordanzkoeffizient/Kendalls W Test auf Korrelation von Rangreihen Wilcoxon-Rangsummentest Test auf Gleichheit des Lageparameters, bei unbekannter aber identischer Verteilung im 2-Stichprobenfall mit ungepaarten Stichproben Mann-Whitney-U-Test äquivalent zum Wilcoxon-Rangsummentest Wilcoxon-Vorzeichen-Rang-Test Test auf Gleichheit des Lageparameters, bei unbekannter aber identischer Verteilung im 2-Stichprobenfall mit gepaarten Stichproben Kruskal-Wallis-Test Test auf Gleichheit des Lageparameters, bei unbekannter aber identischer Verteilung im c-Stichprobenfall mit ungepaarten Stichproben Friedman-Test Test auf Gleichheit des Lageparameters, bei unbekannter aber identischer Verteilung im c-Stichprobenfall mit gepaarten Stichproben Run(s)-Test Prüfung einer Reihe von Werten (etwa Zeitreihe) auf Stationarität Wald-Wolfowitz-Run(s)-Test Test auf Gleichheit zweier kontinuierlicher Verteilungen Auswahl des Signifikanztestverfahrens
abhängig oder verbunden: Zwei Stichproben A und B hängen voneinander im Bezug auf Störgrößen und Einflussgrößen ab (etwa Vorher-Nachher-Vergleiche, Medikament A und B werden an je einem Patienten gleichzeitig gegeben …)
METRISCH NOMINAL ORDINAL nicht normalverteilt,
aber ähnlichnormalverteilt unabhängig abhängig unabhängig abhängig unabhängig abhängig unabhängig abhängig
χ2
für:
k x l -Felder
2 × 2 Felder
χ2
McNemar-Test für:
2 × 2 Felder
Mann-Whitney
Wilcoxon
Mann-Whitney
Wilcoxon
F-Test
(Varianzquotiententest)
entscheidet über:
t-Test
für verbundene
StichprobenVarianz-
homogenität
t-TestVarianz-
heterogenität
Welch-Testnichtparametrische Testverfahren parametrische Testverfahren Wichtige Verteilungen
Weblinks
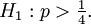
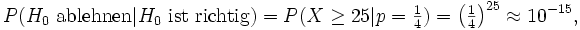
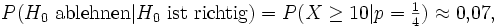
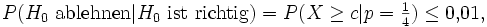
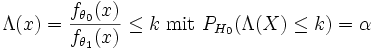
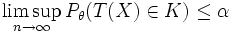
Wikimedia Foundation.