- Entity Relationship Model
-
Das Entity-Relationship-Modell, kurz ER-Modell oder ERM, deutsch Gegenstands-Beziehungs-Modell, dient dazu, im Rahmen der semantischen Datenmodellierung einen Ausschnitt der realen Welt zu beschreiben. Das ER-Modell besteht aus einer Grafik (siehe unten) und einer Beschreibung der darin verwendeten Elemente, wobei Dateninhalte (d.h. die Bedeutung bzw. Semantik der Daten) und Datenstrukturen dargestellt werden.
Ein ER-Modell dient sowohl in der konzeptionellen Phase der Anwendungsentwicklung der Verständigung zwischen Anwendern und Entwicklern (dabei wird nur das Was, also die Sachlogik, und nicht das Wie, also die Technik, behandelt), als auch in der Implementierungsphase als Grundlage für das Design der - überwiegend relationalen - Datenbank.
Das ER-Modell ist der Standard für die Datenmodellierung, auch wenn es unterschiedliche grafische Darstellungsformen gibt.
Das ER-Modell wurde 1976 von Peter Chen in seiner Veröffentlichung The Entity-Relationship Model vorgestellt. Die Beschreibungsmittel für Generalisierung und Aggregation wurden 1977 von Smith and Smith eingeführt. Danach gab es mehrere Weiterentwicklungen, so Ende der 1980er Jahre durch Wong und Katz.
Inhaltsverzeichnis
Begriffe
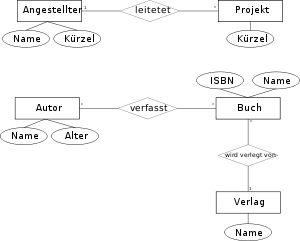 Beispiele für ERDs in Chen-Notation
Beispiele für ERDs in Chen-NotationGrundlage der Entity-Relationship-Modelle ist die Typisierung von Objekten und deren Beziehungen untereinander:
- Entität (Entity): Objekt der Wirklichkeit, materiell oder abstrakt (zum Beispiel Angestellter „Müller“, Projekt „3232“)
- Entitätstyp: Typisierung gleichartiger Entitäten (zum Beispiel Angestellter, Projekt, Buch, Autor, Verlag)
- Beziehung (Relationship): Verknüpfung zwischen zwei oder mehreren Entitäten (zum Beispiel „Angestellter Müller leitet Projekt 3232“)
- Beziehungstyp: Typisierung gleichartiger Beziehungen (zum Beispiel Projektleitungsbeziehung zwischen Angestelltem und Projekt)
- Grad oder Komplexität eines Beziehungstyps: Anzahl der Entitätstypen, die an einem Beziehungstyp beteiligt sind. Die Regel ist der Grad 2 (binärer Beziehungstyp); selten tritt der Grad 3 (ternärer Beziehungstyp) oder ein höherer Grad auf. Ternäre und höhergradige Beziehungstypen lassen sich immer auf binäre Beziehungstypen durch Einführung eines neuen Entitätstyps, der den ursprünglichen Beziehungstyp beschreibt, zurückführen. Insofern kann ohne inhaltliche Einschränkung gelten: Es gibt nur binäre Beziehungstypen.
- Kardinalität: mögliche Anzahl der an einer Beziehung beteiligten Entitäten (zum Beispiel kann ein Angestellter mehrere Projekte leiten, während ein Projekt von genau einem Angestellten geleitet wird).
- Attribut: Eigenschaft eines Entitätstyps (zum Beispiel Nachname und Geburtsdatum von Entitätstyp Angestellter). Das Attribut oder die Attributkombination eines Entitätstyps, deren Wert(e) die Entität eindeutig beschreiben, d.h. diese identifizieren, heißen identifiziererende(s) Attribut(e) (zum Beispiel ist das Attribut Projektnummer identifizierend für den Entitätstyp Projekt). Üblicherweise haben 1:n-Beziehungstypen keine Attribute, da diese immer einem der beteiligten Entitätstypen zugeordnet werden können. Im Falle eines n:m-Beziehungstyps kann aus dem Beziehungstyp ein eigenständiger Entitätstyp mit Beziehungstypen zu den ursprünglich beteiligten Entitätstypen geschaffen werden. Dem neuen Entitätstyp kann dann das Attribut zugeordnet werden (zum Beispiel Attribut Projektbeteiligungsgrad beim n:m-Beziehungstyp „Angestellter arbeitet am Projekt“ zwischen den Entitätstypen Angestellter und Projekt).
- Starker Entitätstyp: Die Identifikation einer Entität ist durch ein oder mehrere Werte von Attributen des gleichen Entitätstyps möglich; so ist z.B. die Auftragsnummer für den Entitätstyp Auftrag identifizierend.
- Schwacher Entitätstyp: Zur Identifikation einer solchen Entität ist ein Attributwert einer anderen mit der schwachen Entität in Beziehung stehenden Entität starken Typs erforderlich; so ist z.B. für die Identifikation des schwachen Entitätstyps Auftragsposition neben der Positionsnummer die Auftragsnummer des anderen starken Entitätstyps Auftrag erforderlich. In Erweiterungen des ER-Modells wie bspw. dem SERM werden Schwacher Entitätstyp und dazugehöriger Beziehungstyp zu einem sogenannten ER-Typen zusammengezogen, wodurch Diagramme kompakter werden.
Bei der Datenmodellierung wird in den Diskussionen und Beispielen oft mit den konkreten Objekten gearbeitet (Entitäten und Beziehungen). Das Modell selbst besteht aber immer ausschließlich aus Entitätstypen und Beziehungstypen. Vielleicht wird aus diesem Grund oftmals nicht sauber zwischen den Begriffen unterschieden.Beziehungen mit spezieller Semantik
Die inhaltliche Bedeutung der Beziehungstypen zwischen Entitätstypen kommt im ER-Diagramm lediglich durch einen kurzen Text in der Raute (meistens ein Verb) bzw. als Beschriftung der Kante zum Ausdruck, wobei es dem Modellierer freigestellt ist, welche Bezeichnung er vergibt. Nun gibt es Beziehungen mit spezieller Semantik, die relativ häufig bei der Modellierung vorkommen. Daher hat man für diese Beziehungstypen spezielle Bezeichner und grafische Symbole definiert. Spezialisierung/Generalisierung und Zerlegung/Aggregation sind zwei ergänzende Beschreibungsmittel mit einer speziellen Semantik. Mit diesen beiden speziellen Beziehungen kann die Realwelt verfeinert bzw. vergröbert modelliert werden. Mit fest definierten Namen und speziellen grafischen Symbolen wird gezeigt, dass es sich um semantisch vorbesetzte Beziehungen handelt.
Spezialisierung und Generalisierung mittels „is-a“-Beziehung
Bei der Spezialisierung wird ein Entitätstyp als Teilmenge eines anderen Entitätstyps deklariert, wobei sich die Teilmenge (spezialisierte Menge) durch besondere Eigenschaften (spezielle Attribute und/oder Beziehungen) gegenüber der übergeordneten (generalisierten Menge) auszeichnet. Da es sich bei einem Einzelobjekt einer spezialisierten Menge um dasselbe Einzelobjekt der generalisierten Menge handelt, gelten alle Eigenschaften – insbesondere die Identifikation – und alle Beziehungen des generalisierten Einzelobjektes auch für das spezialisierte Einzelobjekt.
Die Beziehung Spezialisierung/Generalisierung wird durch „is-a“/„can-be“ („ist ein“/„kann ein … sein“) beschrieben. Für „is-a“ wird gelegentlich auch „a-kind-of“ („eine Art …“) benutzt. Es handelt sich hierbei um eine 1:c-Beziehung.Beispiel zur „is-a“-Beziehung: Dackel is-a Hund
und in anderer Leserichtung: Hund can-be DackelDie Spezialisierung erhält man durch Aufteilung, während die Generalisierung durch Zusammenführen von gleichen Einzelobjekten mit gemeinsamen Eigenschaften und Beziehungen, die in verschiedenen Entitäten vorkommen, in einer neuen Entität begründet ist. So können z. B. Kunden und Lieferanten zusätzlich zu Geschäftspartnern zusammengeführt werden, da Name, Anschrift, Bankverbindung etc. sowohl bei den Kunden als auch bei den Lieferanten vorkommen.
Die Visualisierung von Spezialisierung und Generalisierung ist im ursprünglichen ERM Diagramm nicht vorgesehen, aber in Erweiterungen wie z.B. dem SERM.
Aggregation und Zerlegung mittels „is-part-of“-Beziehung
Werden mehrere Einzelobjekte (z. B. Person und Hotel) zu einem eigenständigen Einzelobjekt (z. B. Reservierung) zusammengefasst, dann spricht man von Aggregation. Dabei wird das übergeordnet eigenständige Ganze Aggregat genannt; die Teile, aus denen es sich zusammensetzt, heißen Komponenten. Aggregat und Komponenten werden als Entitätstyp deklariert.
Bei Aggregation/Zerlegung wird zwischen Rollen- und Mengenaggregation unterschieden:
Eine Rollenaggregation liegt vor, wenn es mehrere rollenspezifische Komponenten gibt, diese zu einem Aggregat zusammengefasst werden und es sich um eine 1:c-Beziehung handelt.Beispiel zur „is-part-of“-Beziehung: Fußballmannschaft is-part-of Fußballspiel und Spielort is-part-of Fußballspiel und in anderer Leserichtung: Fußballspiel besteht-aus Fußballmannschaft und Spielort.
Eine Mengenaggregation liegt vor, wenn das Aggregat durch Zusammenfassung von Einzelobjekten aus genau einer Komponente entsteht. Hier liegt ein 1:cN-Beziehung vor.
Beispiel zur Mengenaggregation: Fußballspieler is-part-of Fußballmannschaft
und in anderer Leserichtung: Fußballmannschaft besteht aus (mehreren, N) Fußballspielern.ER-Diagramme
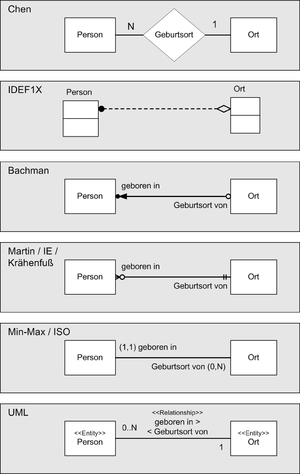
Die grafische Darstellung von Entitätstypen und Beziehungstypen wird Entity-Relationship-Diagramm (ERD) oder ER-Diagramm genannt. Es sind unterschiedliche Darstellungsformen in Gebrauch. Für den Entitätstyp wird meistens ein Rechteck verwendet, der Beziehungstyp meistens in Form einer Verbindungslinie mit besonderen Linienenden oder Beschriftungen, die die Kardinalitäten des Beziehungstyps darstellen.
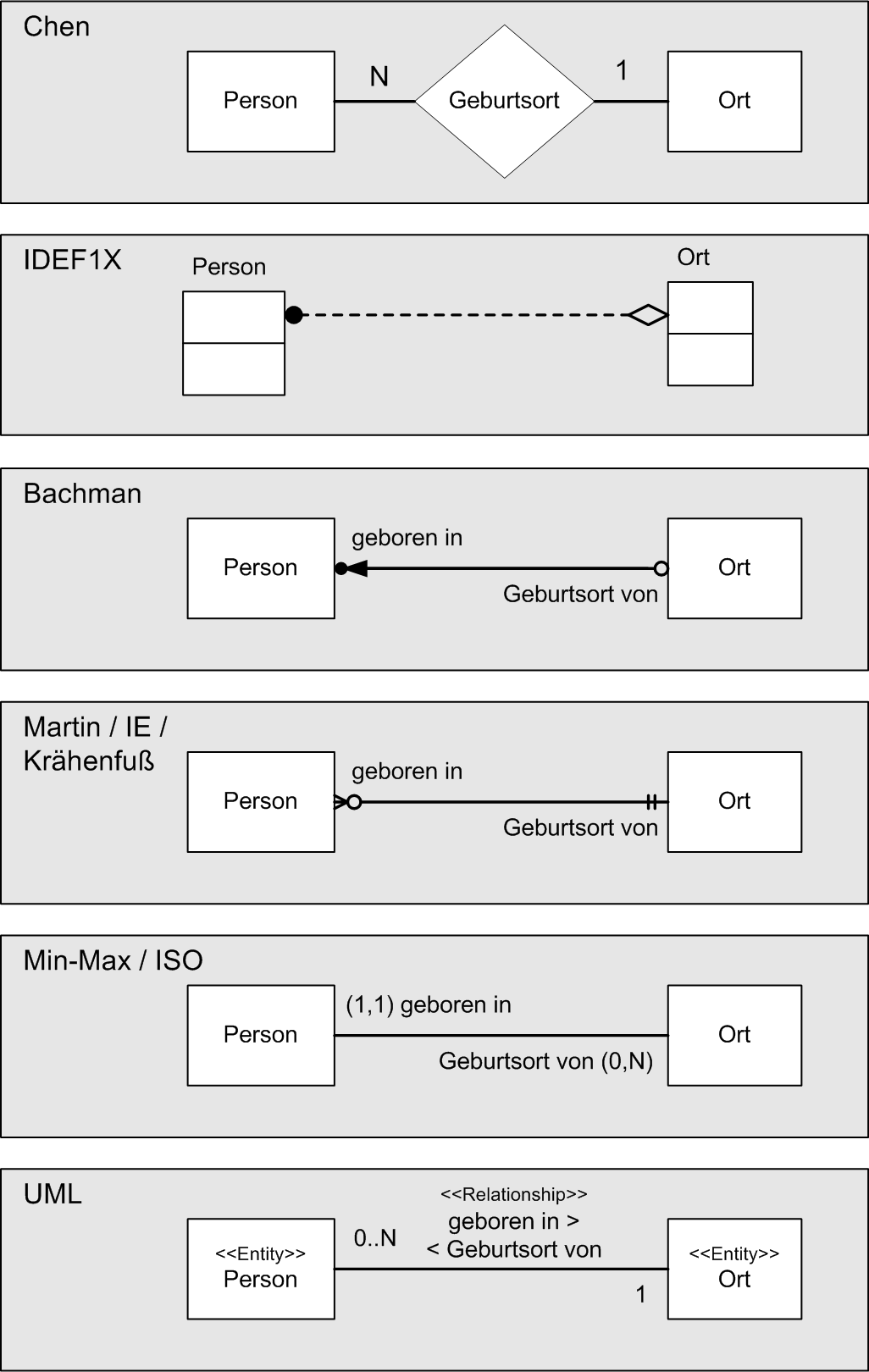
Es gibt heute eine Vielzahl unterschiedlicher Notationen, die sich unter anderem in Klarheit, Umfang der grafischen Sprache, Unterstützung durch Standards und Werkzeuge unterscheiden. Im Folgenden finden sich einige wichtige Beispiele, die vor allem deutlich machen, dass bei allen grafischen Unterschieden die Kernaussage der ER-Diagramme nahezu identisch ist.
Von besonderer − zum Teil historischer − Bedeutung sind unter anderem:
- die Chen-Notation von Peter Chen, dem Entwickler der ER-Diagramme, 1976;
- die IDEF1X als langjähriger De-facto-Standard bei U.S. amerikanischen Behörden;
- die Bachman-Notation von Charles Bachman als weit verbreitete Werkzeug-Diagramm-Sprache;
- die Martin-Notation (Krähenfuß-Notation) als weit verbreitete Werkzeug-Diagramm-Sprache (Information Engineering);
- die (min, max)-Notation von Jean-Raymond Abrial, 1974.
- UML als Standard, den selbst ISO in eigenen Normen als Ersatz für ER-Diagramme verwendet. Attribute (im Schaubild nicht zu sehen) können als Klassenattribute dargestellt werden; Relationship-Attribute hingegen werden mit Hilfe von Assoziationsklassen modelliert.
Alle nebenstehenden Notationen drücken auf ihre Art den folgenden Sachverhalt aus:
- Eine Person ist in maximal einem Ort geboren. Ein Ort ist Geburtsort von beliebig vielen Personen.
- Ein Ort kann ein Geburtsort sein, muss es aber nicht sein.
Bis auf das Chen-Diagramm wird diese Aussage ergänzt um:
- Eine Person muss in einem Ort geboren sein, oder ist in genau einem Ort geboren.
Die (min, max)-Notation unterscheidet sich grundlegend von den anderen Notationsformen im Hinblick auf die Bestimmung der Kardinalität und den Ort, an dem die Häufigkeitsangabe im ER-Diagramm vorgenommen wird. Bei allen anderen Notationen wird die Kardinalität eines Beziehungstyps dadurch bestimmt, dass für eine Entität des einen Entitätstyps nach der Anzahl der möglichen beteiligten Entitäten des anderen Entitätstyps gefragt wird. Bei der Min-Max-Notation hingegen ist die Kardinalität anders definiert. Hierbei wird für jeden der an einem Beziehungstyp beteiligten Entitätstyp nach der kleinst- und größtmöglichen Anzahl der Beziehungen gefragt, an denen eine Entität des jeweiligen Entitätstyps beteiligt ist. Das jeweilige Min-Max-Ergebnis wird bei dem Entitätstyp notiert, für den die Frage gestellt worden ist.
Der zahlenmäßige Unterschied zwischen Min-Max-Notation und allen anderen Notationen tritt erst bei ternären und höhergradige Beziehungstypen hervor. Bei binären Beziehungstypen ist der Unterschied lediglich in einer Vertauschung der Kardinalitätsangaben ersichtlich.
Einsatz in der Praxis
Das ER-Modell kann bei der Erstellung von Datenbanken genutzt werden. Hierbei wird mit Hilfe von ER-Modellen zunächst die Konzeption der Datenbank vorgenommen, auf deren Grundlage dann die Implementierung der Datenbank erfolgt. Die Umsetzung der in der Realwelt erkannten Objekte und Beziehungen in ein Datenbankschema erfolgt dabei in mehreren Schritten:
- erkennen und zusammenfassen von Objekten zu Entitätstypen durch Abstraktion (z. B.: Die Kollegen Fritz Maier und Paul Lehmann und viele weitere zum Entitätstyp „Angestellter“);
- erkennen und zusammenfassen von Beziehungen zwischen je zwei Objekten zu einem Beziehungstyp (z. B.: Der Angestellte Paul Lehmann leitet das Projekt Verbesserung des Betriebsklimas, und der Angestellte Fritz Maier leitet das Projekt Effizienzsteigerung in der Verwaltung - Dieses führt zum Beziehungstyp „Angestellter leitet Projekt“).
- Bestimmung der Kardinalitäten, d. h. der Häufigkeit des Auftretens (z. B.: Ein Projekt wird immer von genau einem Angestellten geleitet, und ein Angestellter darf mehrere Projekte leiten).
All dieses lässt sich in einem ER-Modell darstellen.
Weiter sind folgende Schritte notwendig, deren Ergebnis meistens jedoch nicht grafisch dargestellt wird (so z. B. in der obigen Grafik):
- Bestimmung der relevanten Attribute der einzelnen Entitätstypen.
- Markierung bestimmter Attribute eines Entitätstyps als identifizierende Attribute, so genannte Schlüsselattribute.
- Durchführung des Prozesses der Normalisierung, um die Redundanz innerhalb der zu erstellenden Datenbank zu verringern und um die Datenintegrität zu erhöhen. Da das Ergebnis der Normalisierung meistens zu neuen Entitätstypen und geänderten Beziehungstypen führt, beginnt man in diesen Fällen wieder mit dem ersten Schritt. Im SERM entfällt dies, da direkt in 3NF modelliert wird.
- Generierung des Schemas einer relationalen Datenbank mit all seinen Tabellen- und zugehörigen Felddefinitionen mit ihren jeweiligen Datentypen.
Überführung in ein relationales Modell
Die Überführung eines Entity-Relationship-Modells in das Relationen-Modell basiert i.w. auf den folgenden Abbildungen:
- Entitätstyp --> Relation
- Beziehungstyp --> Fremdschlüssel; im Falle eines n:m-Beziehungstyps --> Relation
- Attribut --> Attribut.
Die genaue Überführung, die automatisiert werden kann, erfolgt in 7 Schritten:
- 1. Starke Entitätstypen
Für jeden starken Entitätstyp wird eine Relation R mit den Attributen
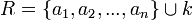 mit k als Primärschlüssel und a1,a2,...,an als Attribute der Entität erstellt.
mit k als Primärschlüssel und a1,a2,...,an als Attribute der Entität erstellt.- 2. Schwache Entitätstypen
Für jeden schwachen Entitätstyp wird eine Relation R erstellt mit den Attributen
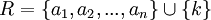 mit dem Fremdschlüssel k sowie dem Primärschlüssel
mit dem Fremdschlüssel k sowie dem Primärschlüssel 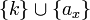 , wobei {ax} den schwachen Entitätstyp und x den starken Entitätstyp identifizieren.
, wobei {ax} den schwachen Entitätstyp und x den starken Entitätstyp identifizieren.- 3. 1:1-Beziehungstypen
Für einen 1:1-Beziehungstyp der Entitätstypen T, S wird eine der beiden Relationen um den Fremdschlüssel für die jeweils andere Relation erweitert.
- 4. 1:N-Beziehungstypen
Für den 1:N-Beziehungstyp der Entitätstypen T, S wird die mit der Kardinalität N (bzw. 1 in min-max-Notation) eingehende Relation T um den Fremdschlüssel der Relation S erweitert.
- 5. N:M-Beziehungstypen
Für jeden N:M-Beziehungstyp wird eine neue Relation R mit den Attributen
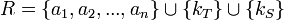 mit {a1,a2,...,an} für die Attribute der Beziehung sowie kT bzw. kS für die Primärschlüssel der beteiligten Relationen erstellt.
mit {a1,a2,...,an} für die Attribute der Beziehung sowie kT bzw. kS für die Primärschlüssel der beteiligten Relationen erstellt.- 6. Mehrwertige Attribute
Für jedes mehrwertige Attribut in T wird eine Relation R mit den Attributen
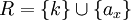 mit {ax} als mehrwertiges Attribut und k als Fremdschlüssel auf T erstellt.
mit {ax} als mehrwertiges Attribut und k als Fremdschlüssel auf T erstellt.- 7. n-äre Beziehungstypen
Für jeden Beziehungstyp mit einem Grad > 2 wird eine Relation R erstellt mit den Attributen
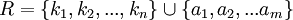 mit {k1,k2,...,kn} als Fremdschlüssel auf die eingehenden Entitätstypen sowie {a1,a2,...am} als Attribute des Beziehungstyps. Der Primärschlüssel ist hierbei die Menge der mit Kardinalität > 1 eingehenden Fremdschlüssel.
mit {k1,k2,...,kn} als Fremdschlüssel auf die eingehenden Entitätstypen sowie {a1,a2,...am} als Attribute des Beziehungstyps. Der Primärschlüssel ist hierbei die Menge der mit Kardinalität > 1 eingehenden Fremdschlüssel.Siehe auch
- Liste von Datenmodellierungswerkzeugen
- Structured Entity Relationship Model, auf ER aufbauend, Methodik führt zu Modell in 3NF, incl. Generalisierung/Spezialisierung, kompaktere Darstellung nach Existenzabhängikeiten sortiert, daher direktes Ablesen von Einstiegspunkten, Zyklen und Schlüsselvererbung möglich.
Literatur
- Peter Pin-Shan Chen: The Entity-Relationship Model--Toward a Unified View of Data. In: ACM Transactions on Database Systems 1/1/1976 ACM-Press ISSN 0362-5915, S. 9–36
- Peter Pin-Shan Chen: Entity-Relationship Modeling--Historical Events, Future Trends, and Lessons Learned. In: Software Pioneers: Contributions to Software Engineering, Broy M. and Denert, E. (eds.), Springer-Verlag, Berlin, Lecturing Notes in Computer Sciences, June 2002, pp. 100-114, ISBN 3-540-43081-4
- J.M. Smith, D.C.P. Smith: Database Abstractions: Aggregation and Generalization, ACM Transactions on Database Systems, Vol. 2, No. 2 (1977), S. 105–133
- J. M. Smith and D. C. P. Smith: Database Abstraction: Aggregation, Communications of the ACM, Vol. 20, Nr. 6, pp. 405–413, June 1977
- Ramez Elmasri, Shamkant B. Navathe: Fundamentals of database systems. Addison Wesley, ISBN 0-8053-1755-4

Wikimedia Foundation.