- Flynnsche Taxonomy
-
Flynnsche Klassifikation Single
InstructionMultiple
InstructionSingle
DataSISD MISD Multiple
DataSIMD MIMD Die Flynnsche Klassifikation [1][2] (auch Flynn'sche Taxonomie genannt) ist eine Unterteilung von Rechnerarchitekturen, welche 1972 von Michael J. Flynn publiziert wurde. Dabei werden die Architekturen nach der Anzahl der vorhandenen Befehls- (Instruction Streams) und Datenströme (Data Streams) unterteilt. Die verwendeten vierbuchstabigen Abkürzungen SISD, SIMD, MISD und MIMD wurden aus den Anfangsbuchstaben der englischen Beschreibungen abgeleitet, zum Beispiel steht SISD für „Single Instruction, Single Data“.
Inhaltsverzeichnis
SISD (Single Instruction, Single Data)
Unter SISD-Rechnern versteht man traditionelle Einprozessor-Rechner, die ihre Aufgaben sequentiell abarbeiten. SISD-Rechner sind z.B. Personal-Computer (PCs) oder Workstations, welche nach der Von-Neumann- oder der Harvard-Architektur aufgebaut sind. Bei erster wird für Operanden und Instruktionen der gleiche Speicher verwendet, bei letzterer sind sie getrennt.
SIMD (Single Instruction, Multiple Data)
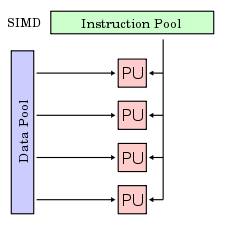
Eine Architektur von Großrechnern beziehungsweise Supercomputern. SIMD-Computer, auch bekannt als Array-Prozessoren oder Vektorprozessor, dienen der schnellen Ausführung gleichartiger Rechenoperationen auf mehrere gleichzeitig eintreffende oder zur Verfügung stehende Eingangsdatenströme und werden vorwiegend in der Verarbeitung von Bild-, Ton- und Videodaten eingesetzt.
Dies ist dort sinnvoll, weil in diesen Bereichen die zu verarbeitenden Daten meist hochgradig parallelisierbar sind. So sind z.B. bei einem Videoschnitt die Operationen für die vielen einzelnen Bildpunkte identisch. Theoretisch optimal wäre hier die Ausführung mittels einem einzigen auf alle Punkte anzuwendenden Befehl.
Des Weiteren sind im Multimedia- und Kommunikationsbereich erforderliche Operationen häufig keine einfachen, einzelnen Operationen sondern eher umfangreichere Befehlsketten. Das Einblenden eines Bildes vor einem Hintergrund ist beispielsweise ein komplexer Vorgang aus Maskenbildung mittels XOR, Vorbereitung des Hintergrundes mittels AND und NOT, sowie der Überlagerung der Teilbilder durch OR. Dieser Anforderung wird durch die Bereitstellung neuer komplexer Befehle entsprochen. So vereinigt z.B. der MMX-Befehl PANDN eine Invertierung und Und-Verknüpfung der Form x = y AND (NOT x).
Viele moderne Mikroprozessoren (wie PowerPC und x86) besitzen inzwischen SIMD-Erweiterungen, das heißt spezielle zusätzliche Befehlssätze, die mit einem Befehlsaufruf gleichzeitig mehrere gleichartige Datensätze verarbeiten.
Allerdings muss man unterscheiden zwischen Befehlen, die lediglich gleichartige Rechenoperationen ausführen und anderen, die bis in den Bereich der DSP-Funktionalität hineinreichen (Beispielsweise ist AltiVec in dieser Hinsicht wesentlich leistungsfähiger als 3DNow!).
Siehe auch: MMX, ISSE, 3DNow!, AltiVec, SSE2, SSE3, SSSE3, SSE4, SSE5
- Feldrechner - mehrere Recheneinheiten berechnen parallel auf verschiedenen Daten die gleiche Operation
- Vektorrechner - quasi-parallele Bearbeitung mehrerer Daten durch Pipelining
MISD (Multiple Instruction, Single Data)
Eine Architektur von Großrechnern bzw. Supercomputern. Die Zuordnung von Systemen zu dieser Klasse ist schwierig, sie ist deshalb umstritten. Viele sind der Meinung, dass es solche Systeme eigentlich nicht geben dürfte. Man kann aber fehlertolerante Systeme, die redundante Berechnungen ausführen, in diese Klasse einordnen. Ein Beispiel für dieses Prozessorsystem ist ein Schachcomputer.
Eine Umsetzung ist das Makropipelining, bei dem mehrere Recheneinheiten hintereinander geschaltet sind. Eine weitere sind redundante Datenströme zur Fehlererkennung bzw. -korrektur.
MIMD (Multiple Instruction, Multiple Data)
Eine Architektur von Großrechnern bzw. Supercomputern. MIMD-Computer führen gleichzeitig verschiedene Operationen auf verschieden gearteten Eingangsdatenströmen durch, wobei die Verteilung der Aufgaben an die zur Verfügung stehenden Ressourcen meistens durch einen oder mehrere Prozessoren des Prozessorverbandes selbst zur Laufzeit durchgeführt wird. Jeder Prozessor hat Zugriff auf die Daten anderer Prozessoren.
Man unterscheidet eng gekoppelte Systeme und lose gekoppelte Systeme. Eng gekoppelte Systeme sind Multiprozessorsysteme, während lose gekoppelte Systeme Multicomputersysteme sind.
Multiprozessorsysteme teilen sich den vorhandenen Speicher und sind somit also ein Shared-Memory-System. Diese Shared-Memory-Systeme lassen sich weiter in UMA (uniform memory access), NUMA (non-uniform memory access) und COMA (cache-only memory access) unterteilen.
Man versucht bei MIMD eine Problemstellung durch die Lösung von Teilproblemen in den Griff zu bekommen. Dabei entsteht wiederum das Problem, dass verschiedene Teilstränge des Problems miteinander synchronisiert werden müssen.
Ein Beispiel in diesem Falle wäre das UNIX-Kommando make. Hier können auch mit mehreren Prozessoren mehrere zusammengehörige Programmcodes gleichzeitig in Maschinensprache übersetzt werden.
- Transputer
- Verteilte Systeme - autonome Prozessoren die gleichzeitig verschiedene Befehle auf verschiedenen Daten bearbeiten
Einzelnachweise
- ↑ M. Flynn: Some Computer Organizations and Their Effectiveness, IEEE Trans. Comput., Band C-21, S. 948–960, 1972.
- ↑ Ralph Duncan: A Survey of Parallel Computer Architectures, IEEE Computer. Februar 1990, S. 5–16.
Siehe auch
- MSIMD Eine Architektur, die sich zwischen den Klassen SIMD und MIMD bewegt.

Wikimedia Foundation.