- Information-Retrieval
-
Information Retrieval [ˌɪnfɚˈmeɪʃən ɹɪˈtɹiːvəl] (IR) bzw. Informationswiedergewinnung, gelegentlich Informationsbeschaffung, ist ein Fachgebiet, das sich mit computergestütztem inhaltsorientiertem Suchen beschäftigt. Es ist ein Teilgebiet der Informationswissenschaft, der Computerlinguistik wie auch der Informatik. Wie der Begriff retrieval (deutsch Wiedergewinnung, Auffindung) sagt, sind Informationen in großen Datenbeständen zunächst verloren und müssen wieder gewonnen bzw. wieder gefunden werden.
Inhaltsverzeichnis
Definition
Zwei Konzepte prägen das IR und grenzen es von der Suche in herkömmlichen Datenbanken ab:
- Vagheit: Der Benutzer kann sein "diffuses" Informationsbedürfnis nicht präzise und formal (wie z. B. in SQL in relationalen Datenbanken) ausdrücken. Die Anfrage enthält daher vage Bedingungen.
- Unsicherheit: Dem System fehlen Kenntnisse über den Inhalt der Dokumente (die Texte, Bilder, Video etc. enthalten können). Dies führt zu fehlerhaften und fehlenden Antworten. Probleme bei Texten bereiten z. B. Homographe (Wörter, die gleich geschrieben werden; z. B. Bank - Geldinstitut, Sitzgelegenheit) und Synonyme (Bank und Geldinstitut).
Methoden des Information-Retrieval werden in Internetsuchmaschinen (z. B. Google), aber auch in Digitalen Bibliotheken (z. B. zur Literatursuche), in Bildsuchmaschinen usw. verwendet. Auch Antwortsysteme oder Spamfilter verwenden IR-Technologien.
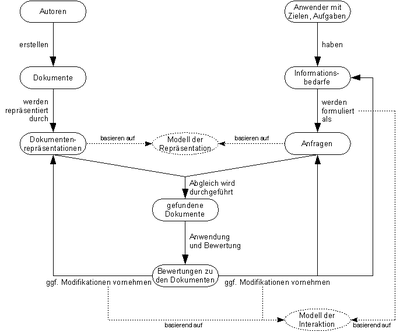 Schematisches Modell des Information-Retrieval (Quelle: Dominik Kuropka)
Schematisches Modell des Information-Retrieval (Quelle: Dominik Kuropka)Generell sind am IR zwei (sich unter Umständen überschneidende) Personenkreise beteiligt (vgl. Abbildung rechts).
Der erste Personenkreis sind die Autoren, die Dokumente in einem IR-System zur Verfügung stellen. Dieses kann sowohl aktiv geschehen, indem die Autoren die Dokumente selbst in das System einstellen, oder auch passiv geschehen, indem das System über Kommunikationsmittel die Dokumente aus anderen verfügbaren Informationssystemen ausliest (wie es z. B. die Internet-Suchmaschinen praktizieren). Die in das System eingestellten Dokumente werden vom IR-System gemäß dem System-internen Modell der Repräsentation von Dokumenten in eine für die Verarbeitung günstige Form (Dokumentenrepräsentation) umgewandelt.
Die zweite Benutzergruppe, die Anwender, haben bestimmte, zum Zeitpunkt der Arbeit am IR-System akute Ziele oder Aufgaben, für deren Lösung ihnen Informationen fehlen. Diese Informationsbedürfnisse möchten Anwender mit Hilfe des Systems decken. Dafür müssen sie ihre Informationsbedürfnisse in einer adäquaten Form als Anfragen formulieren.
Die Form, in der die Informationsbedürfnisse formuliert werden müssen, hängt dabei von dem verwendeten Modell der Repräsentation von Dokumenten ab. Wie der Vorgang der Modellierung der Informationsbedürfnisse als Interaktion mit dem System abläuft (z. B. als einfache Eingabe von Suchbegriffen), wird vom Modell der Interaktion festgelegt.
Sind die Anfragen formuliert, dann ist es die Aufgabe des IR-Systems, die Anfragen mit den im System eingestellten Dokumenten unter Verwendung der Dokumentenrepräsentationen zu vergleichen und eine Liste der zu den Anfragen passenden Dokumente an die Benutzer zurückzugeben. Der Benutzer steht nun vor der Aufgabe, die gefundenen Dokumente gemäß seiner Aufgabe auf die Lösungsrelevanz hin zu bewerten. Das Resultat ist die Bewertungen zu den Dokumenten.
Anschließend haben die Benutzer drei Möglichkeiten: Erstens, sie können (meist nur in einem engen Rahmen) Modifikationen an den Repräsentationen der Dokumente vornehmen (z. B. indem sie neue Schlüsselwörter für die Indexierung eines Dokuments definieren). Zweitens, die Benutzer verfeinern ihre formulierten Anfragen (zumeist um das Suchergebnis weiter einzuschränken) und drittens, die Benutzer ändern ihre Informationsbedürfnisse, weil sie nach dem Durchführen der Recherche feststellen, dass sie zur Lösung ihrer Aufgaben weitere, zuvor nicht als relevant eingestufte Informationen benötigen. Der genaue Ablauf der drei Modifikationsformen wird vom Modell der Interaktion bestimmt. Zum Beispiel gibt es Systeme, die den Benutzern bei der Reformulierung der Anfrage unterstützen, indem sie die Anfrage unter Verwendung von, vom Benutzer explizierter (d. h. dem System in irgendeiner Form mitgeteilter) Dokumentenbewertungen, automatisiert reformulieren.
Geschichte
Die Bezeichnung Information Retrieval wurde ebenso wie Descriptor wahrscheinlich zuerst 1950 von dem Mathematiker Calvin Northrup Mooers eingeführt. Weitere wichtige Vertreter der Frühphase des Information Retrieval waren Mortimer Taube, der das Uniterm-System entwickelte, Hans Peter Luhn, der das Modell der Textstatistik entwickelte und James Whitney Perry.
Retrievalmodelle
Im Bereich "Information Retrieval" sind in den letzten Jahrzehnten verschiedene Modelle entwickelt worden:
- Mengentheoretische Modelle
- Vektorraum-basierte Modelle
- Vektorraum-Retrieval
- Generalized Vector Space Model
- Topic-based Vector Space Model (Literatur: [1], [2])
- Enhanced Topic-based Vector Space Model (Literatur: [3], [4])
- Probabilistisches Retrieval
- Binary Independence Retrieval (BIR)
- Uncertain Inference
- Language Models
- Retrievalstrategien mit Clusteranalyse
Klassifikation von Retrievalmodellen
Eine zweidimensionale Klassifikation von IR-Modellen zeigt die nachstehende Abbildung. Folgende Eigenschaften lassen sich bei den verschiedenen Modellen in Abhängigkeit von Ihrer Einordnung in der Matrix beobachten:
 Klassifikation von IR-Modellen (Quelle: Dominik Kuropka)
Klassifikation von IR-Modellen (Quelle: Dominik Kuropka)- Dimension: mathematisches Fundament
- Mengentheoretische Modelle zeichnen sich dadurch aus, dass sie natürlichsprachliche Dokumente auf Mengen abbilden und die Ähnlichkeitsbestimmung von Dokumenten (in erster Linie) auf die Anwendung von Mengenoperationen zurückführen.
- Algebraische Modelle stellen Dokumente und Anfragen als Vektoren, Matrizen oder Tupel dar, die zur Berechnung von paarweisen Ähnlichkeiten über eine endliche Anzahl algebraischer Rechenoperationen in ein eindimensionales Ähnlichkeitsmaß überführt werden.
- Probabilistische Modelle sehen den Prozess der Dokumentensuche bzw. der Bestimmung von Dokumentenähnlichkeiten als ein mehrstufiges Zufallsexperiment an. Zur Abbildung von Dokumentenähnlichkeiten wird daher auf Wahrscheinlichkeiten und probabilistische Theoreme (insbesondere auf den Satz von Bayes) zurückgegriffen.
- Dimension: Eigenschaften des Modells
- Modelle ohne Terminterdependenzen zeichnen sich dadurch aus, dass jeweils zwei verschiedene Terme als vollkommen unterschiedlich und keinesfalls miteinander verbunden angesehen werden. Dieser Sachverhalt wird in der Literatur häufig auch als Orthogonalität von Termen bzw. als Unabhängigkeit von Termen bezeichnet.
- Modelle mit immanenten Terminterdependenzen zeichnen sich dadurch aus, dass sie vorhandene Interdependenzen zwischen Termen berücksichtigen und ihnen somit – im Unterschied zu den Modellen ohne Terminterdependenzen – nicht die implizite Annahme zu Grunde liegt, dass Terme orthogonal bzw. unabhängig voneinander sind. Die Modelle mit den immanenten Terminterdependenzen grenzen sich von den Modellen mit den transzendenten Terminterdependenzen dadurch ab, dass das Ausmaß einer Interdependenz zwischen zwei Termen aus dem Dokumentenbestand, in einer vom Modell bestimmten Weise, abgeleitet wird – also dem Modell innewohnend (immanent) ist. Die Interdependenz zwischen zwei Termen wird bei dieser Klasse von Modellen direkt oder indirekt aus der Kookkurrenz der beiden Terme abgeleitet. Unter Kookkurrenz versteht man dabei das gemeinsame Auftreten zweier Terme in einem Dokument. Dieser Modellklasse liegt somit die Annahme zu Grunde, dass zwei Terme zueinander interdependent sind, wenn sie häufig gemeinsam in Dokumenten vorkommen.
- Wie bei den Modellen mit immanenten Terminterdependenzen liegt auch den Modellen mit transzendenten Terminterdependenzen keine Annahme über die Orthogonalität oder Unabhängigkeit von Termen zu Grunde. Im Unterschied zu den Modellen mit immanenten Terminterdependenzen können die Interdependenzen zwischen den Termen bei den Modellen mit transzendenten Terminterdependenzen nicht ausschließlich aus dem Dokumentenbestand und dem Modell abgeleitet werden. Das heißt, dass die den Terminterdependenzen zu Grunde liegende Logik als über das Modell hinausgehend (transzendent) modelliert wird. Das bedeutet, dass in den Modellen mit transzendenten Terminterdependenzen das Vorhandensein von Terminterdependenzen explizit modelliert wird, aber dass die konkrete Ausprägung einer Terminterdependenz zwischen zwei Termen direkt oder indirekt von außerhalb (z. B. von einem Menschen) vorgegeben werden muss.
Information-Retrieval hat Querbezüge zu verschiedenen anderen Gebieten, z. B. Wahrscheinlichkeitstheorie der Computerlinguistik.
Siehe auch
- Recall und Precision, Informationsextraktion
- Text Extraction, Fact Extraction
- Datenanalyse, Künstliche Intelligenz, Statistik
- Data-Mining, Web Mining, Text-Mining
- Bibliometrie, Informetrie
- Informationsmanagement, Wissensmanagement
- Fachinformation, Fachdatenbank
- Information Retrieval Facility
- Top-N-Anfrage
- Informationsvisualisierung
- Common Command Language
- Text REtrieval Conference (TREC)
- Proximity
- Enterprise Search
Literatur
- James D. Anderson, J. Perez-Carballo: Information retrieval design: principles and options for information description, organization, display, and access in information retrieval databases, digital libraries, and indexes University Publishing Solutions, 2005.
- R. Baeza-Yates, B. Ribeiro-Neto: Modern Information Retrieval. ACM Press, Addison-Wesley, New York 1999.
- Reginald Ferber: Information Retrieval. dpunkt.verlag, 2003, ISBN 9-783898-642132
- Dominik Kuropka: Modelle zur Repräsentation natürlichsprachlicher Dokumente. Ontologie-basiertes Information-Filtering und -Retrieval mit relationalen Datenbanken, ISBN 3-8325-0514-8
- Dirk Lewandowski: Web Information Retrieval in Information: Wissenschaft und Praxis (nfd) 56 (2005) 1, S.5-12, ISSN 1434-4653
- Dirk Lewandowski: Web Information Retrieval, Technologien zur Informationssuche im Internet, DGI Schrift (Informationswissenschaft - 7), Frankfurt am Main 2005, 248 Seiten mit Sachregister, ISBN 3-925474-55-2
- Eleonore Poetzsch: Information Retrieval - Einführung in Grundlagen und Methoden, E. Poetzsch Verlag, Berlin 2006, ISBN 3-938945-01-X
- Gerard Salton, Michael J. McGill: Introduction to modern information retrieval, McGraw-Hill, New York 1983.
- Wolfgang G. Stock: Information Retrieval. Informationen suchen und finden. München, Wien: Oldenbourg, 2007, 599 Seiten, ISBN 3-486-58172-4.
Weblinks
- Gesellschaft für Informatik, Fachgruppe Information Retrieval
- Prof. Dr.-Ing. Norbert Fuhr: Vorlesung "Information Retrieval" an der Universität Duisburg-Essen, 2006, Materialien
- Karin Haenelt: Seminar "Information Retrieval" Universität Heidelberg, 2005
- Heinz-Dirk Luckhardt, Information Retrieval, Universität Saarland, im Virtuellen Handbuch Informationswirtschaft
- UPGRADE, The European Journal for the Informatics Professional, Information Retrieval and the Web, Vol. III, Issue no. 3, June 2002
- C. J. van Rijsbergen: Information Retrieval, 1979
- Information Retrieval Facility (IRF)


Wikimedia Foundation.