- Latent Semantic Indexing
-
Latent Semantic Indexing (kurz LSI, englisch für schwache Bedeutungseinordnung) ist ein (patentgeschütztes) Verfahren des Information Retrieval, das 1990 zuerst von Deerwester et al.[1] erwähnt wurde. Verfahren wie das LSI sind insbesondere für die Suche auf großen Datenmengen wie dem Internet von Interesse. Das Ziel von LSI ist es, Hauptkomponenten von Dokumenten zu finden. Diese Hauptkomponenten (Konzepte) kann man sich als generelle Begriffe vorstellen. So ist Pferd zum Beispiel ein Konzept, das Begriffe wie Mähre, Klepper oder Gaul umfasst. Somit ist dieses Verfahren zum Beispiel dazu geeignet, aus sehr vielen Dokumenten (wie sie beispielsweise im Internet stehen), diejenigen herauszufinden, in denen es um Autos geht, auch wenn in ihnen das Wort Auto nicht explizit vorkommt. Des Weiteren kann LSI dabei helfen, Artikel, in denen es wirklich um Autos geht, von denen zu unterscheiden, in denen nur das Wort Auto erwähnt wird (wie zum Beispiel bei Seiten, auf denen ein Auto als Gewinn angepriesen wird).
Inhaltsverzeichnis
Mathematischer Hintergrund
Der Name LSI meint, dass die Term-Dokument-Matrix (im Folgenden TD-Matrix) durch die Singulärwertzerlegung angenähert und so approximiert wird. Dabei wird eine Dimensionreduktion auf die Bedeutungseinheiten (Konzepte) eines Dokumentes durchgeführt, die die weitere Berechnung erleichtert.
LSI ist nur ein zusätzliches Verfahren, das auf dem Vektorraum-Retrieval aufsetzt. Die von dorther bekannte TD-Matrix wird durch das LSI zusätzlich bearbeitet, um sie zu verkleinern. Dies ist gerade für größere Dokumentenkollektionen sinnvoll, da hier die TD-Matrizen im Allgemeinen sehr groß werden. Dazu wird die TD-Matrix über die Singulärwertzerlegung zerlegt. Danach werden „unwichtige“ Teile der TD-Matrix abgeschnitten. Diese Verkleinerung hilft Komplexität und damit Rechenzeit beim Retrievalprozess (Vergleich der Dokumente oder Anfragen) zu sparen.
Am Ende des Algorithmus steht eine neue, kleinere TD-Matrix, in der die Terme der originalen TD-Matrix zu Konzepten generalisiert sind.
Der Semantische Raum
 LSI - Die Abbildung zeigt eine typische Term-Dokument-Matrix (1) in der für jeden Term (Wort), angegeben wird, in welchen Dokumenten er vorkommt. Die ursprünglichen 5x7 Dimensionen können hier auf 2x7 reduziert werden (2). So werden brain und lung in einem Konzept zusammengefasst, data, information und retrieval in einem anderen.
LSI - Die Abbildung zeigt eine typische Term-Dokument-Matrix (1) in der für jeden Term (Wort), angegeben wird, in welchen Dokumenten er vorkommt. Die ursprünglichen 5x7 Dimensionen können hier auf 2x7 reduziert werden (2). So werden brain und lung in einem Konzept zusammengefasst, data, information und retrieval in einem anderen.Die TD-Matrix wird über die Singulärwertzerlegung in Matrizen aus ihren Eigenvektoren und Eigenwerten aufgespalten. Die Idee ist die, dass die TD-Matrix (Repräsentant des Dokumentes) aus Hauptdimensionen (für die Bedeutung des Dokuments wichtige Wörter) und weniger wichtigen Dimensionen (für die Bedeutung des Dokuments relativ unwichtige Wörter) besteht. Erstere sollen dabei erhalten bleiben, während letztere vernachlässigt werden können. Auch können hier Konzepte, das heißt von der Bedeutung her ähnliche Wörter (im Idealfalle Synonyme), zusammengefasst werden. LSI generalisiert also die Bedeutung von Wörtern. So kann die übliche Dimensionsanzahl deutlich verringert werden, indem nur die Konzepte verglichen werden. Bestünden die untersuchten Dokumente (Texte) aus den vier Wörtern Gaul, Pferd, Tür und Tor, so würden Gaul und Pferd zu einem Konzept zusammengefasst, genauso wie Tür und Tor zu einem anderen. Die Anzahl der Dimensionen wird hierbei von 4 (in der originalen TD-Matrix) auf 2 (in der generalisierten TD-Matrix) verringert. Man kann sich gut vorstellen, dass bei großen TD-Matrizen die Einsparung in günstigen Fällen enorm ist. Diese dimensionsreduzierte, approximierende TD-Matrix wird als Semantischer Raum bezeichnet.
Algorithmus
- Die Term-Dokument-Matrix wird berechnet und gegebenenfalls gewichtet, z.B. mittels tf-idf
- Die Term-Dokument-Matrix A wird nun in drei Komponenten zerlegt (Singulärwertzerlegung):
 .
.- Die beiden orthogonalen Matrizen U und V enthalten dabei Eigenvektoren von ATA bzw. AAT, S ist eine Diagonalmatrix mit den Wurzeln der Eigenwerte von ATA, auch Singulärwerte genannt.
- Über die Eigenwerte in der erzeugten Matrix S kann man nun die Dimensionsreduktion steuern. Das geschieht durch sukzessives Weglassen des jeweils kleinsten Eigenwertes bis zu einer unbestimmten Grenze k.
- Um eine Suchanfrage q (für Query) zu bearbeiten, wird sie in den Semantischen Raum abgebildet. q wird dabei als Spezialfall eines Dokumentes der Größe
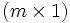 angesehen. Mit folgender Formel wird der (eventuell gewichtete) Queryvektor q abgebildet:
angesehen. Mit folgender Formel wird der (eventuell gewichtete) Queryvektor q abgebildet:
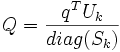
- Sk sind die ersten k Diagonalelemente von S.
- Jedes Dokument wird wie q in den Semantischen Raum abgebildet. Danach kann q zum Beispiel über die Kosinus-Ähnlichkeit oder das Skalarprodukt mit dem Dokument verglichen werden.
Vor- und Nachteile des Verfahrens
Der Semantische Raum (das heißt die auf die Bedeutungen reduzierte TD-Matrix) spiegelt die den Dokumenten unterliegende Struktur wider, deren Semantik. Die ungefähre Position im Vektorraum des Vektorraum-Retrieval wird dabei beibehalten. Die Projektion auf die Eigenwerte gibt dann die Zugehörigkeit zu einem Konzept an (Schritte 4 und 5 des Algorithmus). Das Latent Semantic Indexing löst elegant das Synonymproblem, aber nur teilweise die Polysemie, das heißt, dass dasselbe Wort verschiedene Bedeutungen haben kann. Der Algorithmus ist sehr rechenaufwändig. Die Komplexität beträgt für die Singulärwertzerlegung
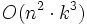 , wobei n die Anzahl der Dokumente + Anzahl der Terme und k die Anzahl der Dimensionen ist. Dieses Problem lässt sich umgehen, indem zur ökonomischen Berechnung einer von vorneherein reduzierten TD-Matrix das Lanczos-Verfahren verwendet wird. Die Singulärwertzerlegung muss zudem stets wiederholt werden, wenn neue Terme oder Dokumente hinzukommen. Ein weiteres Problem ist das Dimensionsproblem: auf wieviele Dimensionen soll die Term-Dokument-Matrix verkleinert werden, also wie groß ist k.
, wobei n die Anzahl der Dokumente + Anzahl der Terme und k die Anzahl der Dimensionen ist. Dieses Problem lässt sich umgehen, indem zur ökonomischen Berechnung einer von vorneherein reduzierten TD-Matrix das Lanczos-Verfahren verwendet wird. Die Singulärwertzerlegung muss zudem stets wiederholt werden, wenn neue Terme oder Dokumente hinzukommen. Ein weiteres Problem ist das Dimensionsproblem: auf wieviele Dimensionen soll die Term-Dokument-Matrix verkleinert werden, also wie groß ist k.Siehe auch
Weblinks
- Semager deutsches Projekt zur Berechnung von Wortverwandschaften
- Webbuch zum Information Retrieval
- Erklärung der Singulärwertzerlegung (englisch)
- SVDLIBC: Programmbibliothek zur Singulärwertzerlegung mittels des Lanczos-Algorithmus
- Latent Semantic Indexing Deutsche Erklärung zur LSI allgemein und der Technologie
Quellen
- ↑ Indexing by Latent Semantic Analysis, Scott Deerwester, Susan Dumais, George Furnas, Thomas Landauer und Richard Harshman (pdf)
Wikimedia Foundation.