- Textfile
-
 Die 95 druckbaren Zeichen des ursprünglichen ASCII
Die 95 druckbaren Zeichen des ursprünglichen ASCIIAls Textdatei bezeichnet man in der Informationstechnik eine Datei, deren Inhalt eine sequentielle Folge von Zeichen darstellt, die durch Zeilen- und Seitenwechsel untergliedert sein können. Das Gegenstück zur Textdatei stellt eine Binärdatei dar. Genaugenommen werden auch Textdateien binär gespeichert, oft werden die Begriffe jedoch komplementär verwendet. Eine Textdatei ist im Gegensatz zu einer Binärdatei ohne die Verwendung spezieller Software lesbar und kann mit einem einfachen Texteditor – wie beispielsweise mit Notepad unter Microsoft Windows – angesehen und bearbeitet werden. Die zweiwertige Klassifizierung von Dateien als Text- und Binärdateien ist nicht in allen Fällen eindeutig, insbesondere bei Verwendung der Begriffe auf unterschiedlichen Abstraktionsebenen. Ungeachtet dieser Unschärfe werden die Begriffe in der Informationstechnik häufig gebraucht.[1]
Die Menge der verfügbaren Zeichen wird durch die zugrunde liegende Kodierung bestimmt, am gebräuchlichsten sind hierbei ASCII oder Unicode. Häufig wird die Zeichenmenge durch eine natürliche oder formale Sprache eingeschränkt, in der der Textinhalt verfasst ist. Sind zur Auswertung des Inhalts einer Textdatei weder besondere Verarbeitungsschritte noch die Kenntnis einer speziellen Notation erforderlich, bezeichnet man den Inhalt als Plain text (engl. für einfachen Text oder Klartext).[2] Textdateien, die eine bestimmte Notation erfordern – wie beispielsweise HTML-Dateien – können zwar mit einem einfachen Texteditor bearbeitet werden, jedoch gibt es hierfür oft spezielle Software, die die Bearbeitung erleichtert – beispielsweise durch besondere Hervorhebungen oder automatische Formatierungen.
Umgangssprachlich werden gelegentlich alle Dateien als „Textdatei“ bezeichnet, die mit dem Ziel erstellt wurden, dem Benutzer einen lesbaren Text zu präsentieren. Bei den von üblicher Textverarbeitungs- oder Publishingsoftware bei Speicherung erzeugten Dateien handelt es sich jedoch häufig um komplexe Dateiformate, die neben dem Text Metainformation zur Beschreibung des Textlayouts, der Struktur und der verwendeten Schriften enthalten, zudem können Bilder oder Grafiken eingebettet sein. Dabei handelt es sich um keine Textdateien im obigen Sinne, da die Dateiformate häufig binär sind und zur Anzeige eine spezielle Software erforderlich ist.
Inhaltsverzeichnis
Geschichte
In der Anfangszeit der elektronischen Datenverarbeitung war die Unterscheidung zwischen Text- und Binärdateien einfacher und von größerer Bedeutung als heute. Die Zeichen einer Textdatei wurden dabei direkt – das heißt Zeichen für Zeichen, ohne jegliche Umsetzung durch ein spezielles Programm – zu einem Terminal oder vor allem auf einen Drucker übertragen. Letzteres ist auch der Grund, warum sich in Textdateien auch Steuerzeichen wie „Zeilenvorschub“ oder „Wagenrücklauf“ finden können.
Zur Umsetzung der physisch gespeicherten Bitfolgen in einem Text wurde und wird auch heute noch eine Zeichenkodierung verwendet. Früher wurde dabei praktisch ausschließlich ein Zeichen immer direkt in ein Byte umgesetzt, also eine Gruppe von 8 Bit, die so 256 (entspricht 28) verschiedene Zeichen ermöglichte. Spätestens seit Einführung von Unicode stellt sich diese Umsetzung allerdings etwas komplizierter dar.
Da bei der Codierung mittels ASCII in der ursprünglichen Definition sogar nur 7 Bits verwendet werden, können auf Systemen, die diese Codierung einsetzen, Binärdateien daran erkannt werden, dass ihre Codierung das vom ASCII unbenutzte 8. Bit verwendet. Allerdings ist ASCII in dieser ursprünglichen Form heute kaum noch gebräuchlich.
Abgrenzung von Binär- und Textdateien
Bei vielen Betriebssystemen existieren Konventionen in Bezug auf die Endung von Dateinamen zur Kennzeichnung von Textdateien. Unter Windows wird dem Namen einer Textdatei in der Regel die Endung .txt angehängt. Die zur Standardisierung des technischen Formats von E-Mails entworfenen Multipurpose Internet Mail Extensions (MIME) definieren sogenannte Medientypen, die mittlerweile neben dem E-Mail-Verkehr auch in vielen anderen Bereichen zur Kennzeichnung des Dateityps verwendet werden. Der Medientyp text kennzeichnet dabei Textdateien. Die vollständige Typangabe wird noch um einen Subtyp ergänzt, der den Verwendungszweck der Textdatei spezifiziert. Für Textdateien, die direkt den „eigentlichen“ Text enthalten, der nicht für eine bestimmte maschinelle Weiterverarbeitung bestimmt ist, lautet die vollständige Typangabe text/plain.
Für den in einer Textdatei enthaltenen Text können keine besonderen Formatierungen wie beispielsweise Hervorhebungen durch Fettdarstellung festgelegt werden. Manche Codierungen erlauben das Stapeln diakritischer Zeichen oder die Darstellung von bidirektionalem Text.[2]
Eine mit einer Textverarbeitung (wie beispielsweise Microsoft Word) erstellte Datei ist im Normalfall keine Textdatei, selbst wenn ausschließlich Text erfasst wurde, da der Text nur unter Verwendung eines geeigneten Textverarbeitungssystems wieder angezeigt und bearbeitet werden kann. Auch eine im Portable Document Format (PDF) vorliegender Text ist keine Textdatei, weil diese binär codierte Formatinformationen enthält. Ebenso handelt es sich bei Texten, die mittels eines Scanners eingelesen werden, nicht um Textdateien. Diese sind Bilddateien, sofern sie nicht nach dem Scan-Vorgang mittels einer Texterkennungs-Software (OCR) in eine Textdatei umgewandelt werden.
Bei einer Datenkomprimierung kann bei Textdateien im Regelfall eine erheblich größere Einsparung bei der Speichergröße erzielt werden als bei Binärdateien. Dies liegt daran, dass bei Textdateien die Informationsdichte geringer ist als bei den meisten Binärdateien, was die gängigen Komprimierungsalgorithmen ausnutzen – beispielsweise durch Verwendung der Huffman-Codierung.[3]
Kennzeichnung des Zeilenendes
Grundsätzlich gibt es zwei Möglichkeiten festzulegen, an welcher Stelle eine neue Zeile im Text beginnen soll: die Festlegung einer konstanten Anzahl Zeichen pro Zeile oder die Verwendung eines definierten speziellen Zeichens zur Markierung des Zeilenendes.
Festlegung einer konstanten Zeilenlänge
Die Verwendung einer festen Zeilenlänge hat den Vorteil, dass die Position einer bestimmten Zeile innerhalb der Zeichenfolge (Bytefolge) der Datei ermittelt werden kann, ohne die Datei Zeile für Zeile lesen zu müssen. Allerdings hat sie den Nachteil, dass Zeilen mit kürzerem Inhalt „aufgefüllt“ werden müssen (siehe Padding); dies erfolgt in der Regel mit Leerzeichen. Dadurch beansprucht die Datei mehr Speicherplatz als nötig, wenn die Zeilenlänge nicht ausgeschöpft wird. Eine solche feste Zeilenlänge ist nur auf Großrechner-Systemen gebräuchlich.
Kennzeichnung mittels Steuerzeichen
Die übliche Definition des Zeichens zur Kennzeichnung des Zeilenendes erinnert an die ursprüngliche direkte Datenausgabe von Textdateien auf Fernschreibern oder Druckern, die in ihrer Bauart einer Schreibmaschine entsprachen. Dort waren die „Befehle“ Wagenrücklauf (Carriage Return, CR) und Zeilenvorschub (Line Feed, LF) notwendig, um die Fortsetzung der Druckausgabe am Beginn der nächsten Zeile zu veranlassen – bei einem Fernschreiber waren das zwei separate Tasten. Diese beiden Steuerzeichen waren folglich die aussichtsreichsten Kandidaten, um als Markierung des Zeilenendes bei elektronischer Speicherung von Dateien verwendet zu werden. Im Prinzip ist dabei aber ein Zeichen von beiden ausreichend, und diese Wahlmöglichkeit führte dazu, dass die Festlegung uneinheitlich erfolgte, was bis heute ein immer wiederkehrender Fallstrick bei der Nutzung von Textdateien ist:
- Hauptsächlich unter Microsoft Windows und dem Vorläufersystem MS-DOS wird die Folge von CR und LF zur Markierung des Zeilenendes verwendet.
- Unter Unix, Linux und verwandten Systemen wird das Zeilenende alleine mittels LF gekennzeichnet.
- Bei den älteren Betriebssystemen von Apple war mit der ausschließlichen Verwendung von CR auch die dritte Möglichkeit gebräuchlich.
- In der IBM-Großrechnerwelt wird im EBCDIC neben diesen beiden Zeichen noch ein weiteres spezielles Zeichen (New Line, NL) verwendet.[4]
Die diesbezüglich meisten Probleme entstehen beim Austausch von Dateien zwischen Windows- und Unix-Plattformen, da diese über weite Bereiche denselben Zeichencode verwenden und mit Ausnahme des Zeilenende-Zeichens im Regelfall keine Konvertierung der Dateien erforderlich ist.
„Harter“ und „weicher“ Zeilenumbruch
Bei Anzeige oder Bearbeitung von Textdateien werden durch das dabei verwendete Hilfsmittel – beispielsweise einen Editor – häufig automatisch Zeilenumbrüche eingefügt, wenn die Breite des verwendeten Bildschirmfensters zur Anzeige der gesamten Zeile nicht ausreicht. In ähnlicher Weise kann es auch bei Druckausgabe zum Einfügen solcher „weichen“ Zeilenumbrüche kommen. Diese Zeilenumbrüche sind nicht in der Datei selbst enthalten und erfolgen bei Ausgabe auf einem anderen Medium meist an anderer Stelle. Oft sind diese vom Anwender nur schwer von den „harten“ Zeilenumbrüchen zu unterscheiden – also den Zeilenumbrüchen, die der Anwender beispielsweise selbst unter Verwendung der entsprechenden Taste in der Datei eingefügt hat und die auch in der Datei gespeichert werden.
In diesem Zusammenhang ist zu beachten, dass es bei Erfassung von Texten mit Hilfe einer Textverarbeitung ungünstig ist, innerhalb eines Absatzes explizite Zeilenumbrüche einzufügen, da hiermit der Textverarbeitung der Spielraum genommen wird, den Text für jedes Ausgabemedium passend aufzubereiten. Bei der Übernahme von Bestandteilen einer Textdatei in eine Textverarbeitung – beispielsweise über die Zwischenablage – können unbeabsichtigt die „harten“ Zeilenumbrüche übernommen werden, die anschließend entfernt werden sollten und gegebenenfalls durch Leerzeichen zu ersetzen sind.
Andere Steuerzeichen
Neben der Kennzeichnung des Zeilenendes können insbesondere bei Verwendung des ASCII in Textdateien weitere Steuerzeichen auftreten. Diese waren vor allem üblich, als der Inhalt der Textdateien noch direkt zum Terminal oder Drucker übertragen wurde. Die wichtigsten dabei sind das Zeichen
Form Feed(FF), das die Position eines Seitenwechsels im Text markiert, undHorizontal Tabulation(HT), das Tabulatorzeichen, das eine Einrückung des Textes kennzeichnet.Um die Darstellung des Textes noch differenzierter beeinflussen zu können, wurden in Verbindung mit Textdateien teilweise auch sogenannte Escape-Sequenzen verwendet. Sie bestehen aus dem einleitenden Steuerzeichen
Escape(ESC) und einer Folge weiterer Zeichen, die eine Darstellungsanweisung codieren. Hier hatten sich Standards etabliert, zur Ansteuerung von Terminals setzte die Digital Equipment Corporation (DEC) mit ihren VT-Modellen den Standard (ANSI X3.41-1974 und X3.64-1977)[5]. Beim Drucken war zur Zeit der Nadeldrucker der von Epson eingeführte Standard ESC/P weit verbreitet, so dass derartige Escape-Sequenzen auch in Textdateien zu finden waren.Zeichencodierung
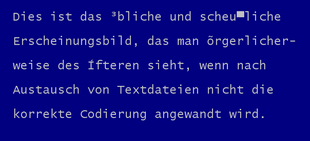 Fehlerhafte Darstellung bei Verwendung der falschen Codierung
Fehlerhafte Darstellung bei Verwendung der falschen CodierungDer auch bei Textdateien physisch binär vorliegende Inhalt wird nach einer für die jeweilige Datei fest vorgegebenen Regel in Text umgewandelt. Dabei sind folgende Zeichencodierungen gebräuchlich:
- ASCII stellt das am weitesten verbreitete Format dar – insbesondere, wenn die diversen Erweiterungen des Standards einbezogen werden.
- ISO 8859-1 und ISO 8859-15 sind standardisierte Erweiterungen des ASCII, die die Grundlage des bei Microsoft Windows im englischen und westeuropäischen Sprachraum verwendeten Codes Windows-1252 bilden.
- EBCDIC ist eine auf Großrechnern von IBM gebräuchliche Codierung.
- Unicode ist ein internationaler Standard, der weltweit alle sinntragenden Zeichen abbildet. Im Gegensatz zu obigen Codierungen kommt Unicode dabei nicht mit 8 Bit (das heißt einem Byte) aus. Es gibt unterschiedliche Verfahren, Unicode in eine Bytefolge umzusetzen, beispielsweise UTF-8 oder UTF-16.[6]
Wird eine Textdatei unter Verwendung einer falschen Zeichencodierung interpretiert, kann sie gänzlich unlesbar sein, wenn vollständig inkompatible Codierungen verwendet werden – wie beispielsweise ASCII und EBCDIC. Wird hingegen eine abweichende, aus dem ursprünglichen ASCII abgeleitete Codierung verwendet, werden lediglich die Sonderzeichen und vor allem die deutschen Umlaute falsch dargestellt, da diese nicht Bestandteil der ersten 128 standardisierten Zeichen des ASCII sind.
Bei der Verwendung von Unicode ist die generelle Umsetzung eines Zeichens in ein Byte nicht anwendbar, da Unicode weit mehr als 256 verschiedene Zeichen definiert. Am meisten verwendet werden hierbei Codierungen mit dem Ziel, die Dateigröße bei Auftreten der gebräuchlichsten Zeichen zu minimieren, dies trifft beispielsweise für UTF-8 zu. Hierfür wird allerdings die Regel „geopfert“, dass jedes Zeichen immer mit derselben Anzahl Bits codiert wird. Zudem existiert die Konvention, am Beginn einer Datei mittels spezieller Bytefolgen (sogenannte Byte Order Marks) kenntlich zu machen, welche Unicode-Codierung verwendet wird. Dies ist auch deshalb nötig, da auf vielen Systemen – auch unter Windows – die bisherige auf ASCII basierende Codierung und Unicode parallel verwendet wird. Bei einer solchen Codierung beginnt die Grenze zur Binärdatei zu verschwimmen.
Austausch zwischen unterschiedlichen Systemen
Wenn Textdateien von einem System auf ein System anderen Typs übertragen werden, muss berücksichtigt werden, ob die durch die Systeme verwendeten Zeichencodierungen übereinstimmen. Weiterhin ist das zur Kennzeichnung des Zeilenendes verwendete Verfahren zu berücksichtigen (siehe oben). Der Austausch von Dateien, die nur die ersten 128 Zeichen des ASCII verwenden, ist auf Systemen, die diese oder eine daraus abgeleitete Codierung verwenden, meist recht problemlos. Auch die Unicode-Codierung UTF-8 stimmt bei ausschließlicher Verwendung dieser Zeichen exakt mit ASCII überein. Werden hingegen weitere Zeichen verwendet, ist oft eine Konvertierung erforderlich. Zu beachten ist allerdings, dass eine Konvertierung nur dann durchzuführen ist, wenn die Datei auf dem Zielsystem selbst auch angezeigt wird. Wird die Datei auf diesem System nur gespeichert und zur Anzeige wieder auf ein System übertragen, das die ursprüngliche Codierung verwendet, wäre eine Konvertierung unnötig und möglicherweise sogar schädlich, da durch diese doppelte Konvertierung Information verloren gehen kann.
Beim Austausch von Textdateien als Anhang einer E-Mail können Unstimmigkeiten auftreten. Das Problem liegt dabei meist beim Absender, da dessen Mail-Client häufig die Codierung der Textdatei nicht korrekt ermitteln kann, vom Benutzer aber diese Angabe aus Gründen der Benutzerfreundlichkeit nicht fordert und so keine entsprechende oder eine falsche Information in die Mail einträgt. Im Prinzip sind die meisten heute gebräuchlichen Mail-Clients in der Lage, die Codierung im Bedarfsfall zu konvertieren.
Bei einer direkten Dateiübertragung (File Transfer) zwischen Systemen wird meist ein spezielles Programm zur Übertragung verwendet. Dieses übernimmt auch die notwendigen Konvertierungen, auch wenn die Codierungen beider Systeme gänzlich unterschiedlich sind – wie beispielsweise beim Austausch zwischen Windows und IBM-Großrechnern. Bei einer Übertragung muss im Regelfall angegeben werden, ob es sich bei der zu übertragenden Datei um eine Text- oder Binärdatei handelt, um festzulegen, ob eine Konvertierung der Datei erfolgen soll oder zu unterlassen ist – der Inhalt einer Binärdatei würde durch eine solche Konvertierung zerstört.
Weitergehende Verwendung von Textdateien
Der ursprüngliche und einfachste Verwendungsfall von Textdateien ist die Übermittlung des enthaltenen Textes als eigentliche Information, in diesem Fall spricht man von Plain text. Textdateien können aber unter Anwendung eines im Vorhinein festzulegenden formalen Aufbaus dazu genutzt werden, komplexere Daten zu übermitteln. Die Datei ist dann meist nicht mehr primär für die direkte Nutzung durch den Endbenutzer gedacht, sondern wird durch ein bestimmtes Programm weiterverarbeitet oder durch einen Systemadministrator gepflegt.
In vielen Fällen werden auf diese Weise heute Textdateien genutzt, in denen eigentlich Binärdateien prädestiniert erscheinen, weil nur eine maschinelle Weiterverarbeitung erfolgt. Der ausschlaggebende Nachteil der Binärdateien hier ist, dass deren Struktur über Systemgrenzen hinweg noch weit inhomogener als die von Textdateien ist (siehe beispielsweise Byte-Reihenfolge). Dafür haben Textdateien den Nachteil, dass zur Speicherung derselben Information mehr Speicherplatz erforderlich ist und dass die Daten vielfach bei einer Weiterverarbeitung erst wieder ins binäre Format konvertiert werden müssen. Da aber – vor allem durch das Internet – der systemübergreifende Austausch von Daten immer bedeutender geworden ist, ist eine Datenspeicherung in Textdateien heute vielfach üblich.
Auch für durch Administratoren oder privilegierte Benutzer zu pflegende Konfigurationsdateien wird häufig das Textformat verwendet. Bei einem binären Format wäre jeweils ein spezielles Konfigurationsprogramm erforderlich, bei Verwendung des Textformats kann die Konfigurationsdatei direkt mittels eines Texteditors bearbeitet werden. Dies ist in der UNIX- und Linux-Welt seit jeher der verbreitete Ansatz; mit der zunehmenden Verbreitung von XML werden Konfigurationsinformationen aber auf allen Systemen überwiegend in Textdateien gespeichert.
Tabellarische Daten
Textdateien werden aus verschiedenen Gründen zur Speicherung von Daten mit tabellarischer Struktur verwendet. So strukturierte Dateien können mit einem Tabellenkalkulationsprogramm (beispielsweise Microsoft Excel) weiterverarbeitet werden. Datenbankdaten werden häufig auf diese Weise exportiert, um diese zwischen Anwendungsprogrammen auszutauschen – auch wenn heute das XML-Format für einen solchen Fall prädestiniert ist.
Es gibt verschiedene Verfahren zur tabellarischen Anordnung der Daten in Textdateien, von denen die folgenden die gebräuchlichsten sind:
- Trennung der Spalten durch Tabulator: Das Tabulatorzeichen, ebenfalls ein spezielles Steuerzeichen, wird innerhalb einer Zeile zur Kennzeichnung der Spaltengrenzen verwendet.
- CSV-Format: Dieses Format, das ursprünglich Comma Separated Values bedeutete, ist ähnlich der Trennung durch Tabulator, nur wird in der Regel im englischen Sprachraum eben das Komma, im deutschen aber der Strichpunkt als Trennzeichen verwendet.
- Festlegung einer konstanten Anzahl Zeichen pro Spalte: Um eine solche Datei verwenden zu können, muss bekannt sein, welche Breite jede einzelne Spalte hat. Diese Definition wird selbst nicht in der Datei gespeichert.
XML
XML (Extensible Markup Language) ist ein Meta-Dateiformat. Es definiert also, in welchem Format definiert wird, wie die Struktur einer Datei aussieht.[7] XML ist dabei bewusst ein Textformat und soll für Mensch und Maschine gleichermaßen lesbar sein, auch soll ein systemübergreifender Austausch von XML-Daten problemlos ermöglicht werden.[8]
XML-Dateien sind also grundsätzlich Textdateien, deren grobe Strukturierung standardisiert ist und die vor allem zum Datenaustausch oder zur Datenspeicherung verwendet werden – der genaue Verwendungszweck wird ja von XML selbst nicht vorgegeben. Ein Beispiel für ein auf XML basierendes Format ist SVG (Scalable Vector Graphics), ein Grafikformat, das somit im Prinzip für Menschen lesbar in einer Textdatei codiert ist.
OpenDocument und Office Open XML
Die Dateiformate der Textverarbeitungen OpenOffice.org (OpenDocument) und der neueren Versionen von Microsoft Word (Office Open XML, erkennbar an der Dateierweiterung
.docxstatt.doc) basieren auf XML, und die gespeicherten Dateien sind demzufolge genaugenommen Textdateien. Dabei ist aber zu beachten, dass der „Text“, der bei direkter Bearbeitung einer solchen Datei sichtbar wird, nicht der „eigentliche“ Textinhalt des Dokuments ist, sondern die Beschreibung des Textdokuments auf einer Metaebene. Ein solches Format erleichtert gegenüber einem binären Format die Verwendung dieser Datei durch andere Anwendungen und auch einen systemübergreifenden Austausch der Datei. [9]Weitere Dateiformate
Neben XML-Formaten existieren noch einige – ältere – recht weit verbreitete Auszeichnungssprachen, die häufig verwendet und in Form einer Textdatei gespeichert werden.
- HTML, die Sprache zur Gestaltung von Inhalten im World Wide Web, ist von der Struktur her verwandt mit XML.
- Rich Text Format (RTF) ist eine Sprache zum Austausch von formatiertem Text zwischen Textverarbeitungsprogrammen, auch auf unterschiedlichen Plattformen.
- TeX und LaTeX stellen ein Textsatzsystem dar, das zur Textgestaltung eine spezielle Sprache verwendet, die in Textdateien codiert wird.
- PostScript ist ein Dateiformat, das professionelle Druckformatierungen ermöglicht und trotzdem in Form einer Textdatei gespeichert wird. Die Binärdaten enthaltener Grafiken werden als hexadezimale Ziffern in Text umgesetzt. Da viele Drucker dieses Format direkt interpretieren können, geben viele Textverarbeitungs- oder Desktop-Publishing-Programme ihre Ergebnisse im PostScript-Format aus. PostScript wird allerdings in einigen Bereichen von seinem Nachfolger PDF verdrängt.
Daneben existieren natürlich noch viele weitere und auch proprietäre Formate, deren Aufbau sich nur bei Verfügbarkeit einer entsprechenden Spezifikation erschließt.
Ansehen, Bearbeiten und Drucken von Textdateien
Texteditoren dienen der direkten Bearbeitung und Anzeige von Textdateien. Dabei bieten praktisch alle Texteditoren eine Möglichkeit, in einer Datei direkt nach speziellen Textinhalten zu suchen. Viele Texteditoren bieten auch eine Unterstützung bei der Darstellung spezieller Dateiformate, so werden verschiedene Syntaxelemente entsprechend ihrer Bedeutung hervorgehoben (beispielsweise durch Einfärbungen). Mithilfe eines Texteditors kann eine Datei im Regelfall auch gedruckt werden.
Sowohl bei der Anzeige in einem Texteditor als auch beim Ausdruck kann das Problem auftreten, dass die Einrückung von Zeilen nicht korrekt dargestellt wird. Dies liegt meist daran, dass in der Datei das Tabulator-Steuerzeichen enthalten ist, für das nicht einheitlich definiert ist, wie weit die Einrückung erfolgen soll. Um wie viele Zeichen eingerückt wird, ist deshalb eine Konfigurationsinformation des Editors oder Druckers. Erschwerend kommt hinzu, dass bei der Anzeige im Texteditor der Unterschied zwischen Leerzeichen und einem Tabulator-Zeichen meist nicht oder nur schwer ersichtlich ist.
Einzelnachweise
- ↑ Dale, Lewis: Computer science illuminated, siehe Literatur
- ↑ a b RFC 4288: Media Type Specifications and Registration Procedures. Abschnitt 4.2.1
- ↑ Hans Werner Lang (FH Flensburg): Codierungstheorie – Huffmann-Code
- ↑ WebSphere Message Broker: Converting EBCDIC NL to ASCII CR LF
- ↑ Manual für VT100-Terminal (englisch)
- ↑ Michael Schönitzer: Encodings
- ↑ Sarah Coppin, Brent Hendricks: XML Basics
- ↑ Mario Jeckle: Extensible Markup Language (XML)
- ↑ wbsskills4u.com: OpenDocument v. Open XML – in search of the perfect document file format
Literatur
- Nell B. Dale, John Lewis: Computer science illuminated. Jones and Bartlett Publishers, Sudbury 2007, ISBN 0-7637-4149-3.


Wikimedia Foundation.