- Dichtestes Punktpaar
-
Das Problem des dichtesten bzw. engsten Punktpaares (auch closest pair problem) ist die Suche nach den zwei am dichtesten beieinander liegenden Punkten in einer Ebene.
Inhaltsverzeichnis
Formale Beschreibung
Gegeben ist eine Menge von Punkten
 und gesucht sind zwei Punkte (Pi,Pj) so, dass der euklidische Abstand d(Pi,Pj) minimal ist.
und gesucht sind zwei Punkte (Pi,Pj) so, dass der euklidische Abstand d(Pi,Pj) minimal ist.Brute-force-Algorithmus
Die naive Herangehensweise ist, einfach sämtliche Distanzen zwischen allen möglichen Punktpaaren zu berechnen und daraus die kleinste zu wählen:
minDist = unendlich für alle p in P: für alle q in P: wenn p ≠ q und dist(p,q) < minDist: minDist = dist(p,q) dichtestesPaar = (p,q) return dichtestesPaar
Da sowohl die innere als auch die äußere Schleife n-mal abgearbeitet werden muss, ist die Laufzeit des Algorithmus O(n2).
Divide-&-Conquer-Algorithmus
Zunächst ist die gegebene Punktmenge einmal nach x- und einmal nach y-Koordinaten zu sortieren; man erhält zwei sortierte Listen Lx und Ly.
Der Divide-Schritt teilt Lx in zwei Hälften PL und PR links und rechts des Medians auf.
Der rekursive Aufruf geschieht nun jeweils auf die beiden Hälften; man erhält das jeweils dichteste Punktpaar in beiden Hälften, ohne dass eventuelle Punktpaare zwischen beiden Hälften berücksichtigt werden.
Der Conquer-Schritt kombiniert nun diese beiden Hälften, es wird das Minimum der gefundenen Distanzen ausgewählt. Hierbei sind zwei Fälle zu beachten:
- Einerseits könnte der kleinste Abstand direkt aus dem linken oder rechten Teilfeld abgelesen werden. In diesem Fall gibt es keine weiteren Probleme.
- Es könnte aber auch sein, dass zwei Punkte in unterschiedlichen Hälften existieren, deren Abstand δ kleiner ist, als der bisher in den Hälften gefundene - dieser Fall ist nun gesondert zu berücksichtigen:
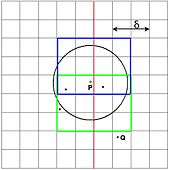 Prüfung der Nachbarn von P
Prüfung der Nachbarn von P
Im Prinzip wäre es nötig, sämtliche solcher Punktpaare einzeln durchzuprüfen. Da dies allerdings immer noch quadratisch viele sind, würde sich so kein Vorteil in der Laufzeit ergeben (man erhielte als Rekursionsgleichung T(n) = 2·T(n/2) + n²/4, was immer noch in O(n2) ist). Sinnvoller ist es, zu verwenden, dass bereits eine gewisse „Vorgabe“ δ für den kleinsten Abstand bekannt ist. Einerseits müssen jetzt nur noch Punkte betrachtet werden, deren Abstand in x-Richtung zur Teilungsgrenze höchstens δ beträgt; außerdem müssen für diese Punkte auch nur noch Partner betrachtet werden, deren Abstand in y-Richtung kleiner als δ ist.
So ergibt sich für jeden zu prüfenden Punkt P, dass lediglich konstant viele potentielle Partner zu prüfen sind: Denkt man sich ein Gitter der Weite δ / 2 in der Umgebung der Teilungsgrenze, so kann in jedem Gitterfeld nur ein Pi liegen, da sonst bereits ein Abstand kleiner δ gefunden worden wäre. Da nur diejenigen Zellen zu prüfen sind, die von P aus höchstens Abstand δ haben (maximal 12 Stück jeweils oben und unten), sind nun auch maximal 24 weitere Abstände für jeden Punkt zu berechnen, womit statt quadratischer Laufzeit nur noch lineare Laufzeit notwendig ist. Insgesamt ist die Rekursionsgleichung nun T(n) = 2·T(n/2) + 24·n, was in O(n log n) ist.Randomisierter Algorithmus
Funktionsweise
Der randomisierte Algorithmus beruht darauf, dass die Punkte in zufälliger Reihenfolge in eine Hashtabelle eingefügt werden, wobei das Einfügen eines Punktes ebenso wie das Testen, ob er die vorher bekannte Minimaldistanz unterbietet, in erwartet O(1) funktioniert. Die Hashtabelle bildet alle Gitterzellen der Größe (δ/2)² auf den eventuell darin liegenden Punkt ab. Es muss zwar bei jedem solchen Update von δ die Hashtabelle neu aufgebaut werden, die Gesamtzahl der Einfügeoperationen in sämtliche dieser Hashtabellen liegt aber trotzdem in O(n).
Ohne Beachtung, wie die Hashtabelle konkret genutzt wird, ergibt zunächst folgender Algorithmus:Bilde eine zufällige Reihenfolge der Punkte P1..Pn δ = d(P1,P2) Füge P1 und P2 in die Hashtabelle ein (Gittergröße δ/2) Für i = 3..n Falls Pi eine Distanz δ' < δ zu einem der P1..Pi − 1 hat: δ := δ' Baue die Hashtabelle neu auf (Gittergröße δ'/2) Füge Pi in die Hashtabelle ein
Gitterstruktur und Hashfunktion
Man kann vereinfachend annehmen, dass alle Punkte Koordinaten zwischen (0,0) und (1,1) haben, ggf. kann hierfür eine Koordinatentransformation vorgenommen werden. Die Ebene, in der die Punkte liegen, wird sodann durch ein Gitter der Weite δ/2 überdeckt. Es wird nun eine universelle Hashfunktion benötigt; sie ermöglicht es einerseits, von einer gegebenen Gitterzelle in O(1) festzustellen, ob sich in dieser Gitterzelle einer der Punkte befindet, und andererseits neue Punkte in O(1) in die bestehende Hashtabelle einzufügen.
Einfügen neuer Punkte
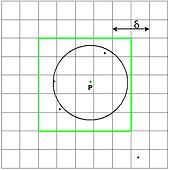 Einfügen von P
Einfügen von PBei jedem Einfügen eines neuen Punktes P ist zu prüfen, ob dadurch die bereits bekannte Minimaldistanz δ unterschritten wird. Anhand der Koordinaten von P lässt sich sofort ablesen, in welche der Gitterzellen P fallen wird. Aufgrund der Aufteilung in Gitterzellen der Größe (δ/2)² muss nur festgestellt werden, ob in einer der umliegenden Gitterzellen schon ein Punkt liegt. Umliegend sind dabei alle Gitterzellen, die eine solche Distanz begründen könnten, also nur der umliegende 5x5-Bereich - alle Punkte die außerhalb dieses Bereichs liegen können keine Distanz <δ zu P haben, da sie aufgrund der Gittergröße mindestens 2·(δ/2) weit weg von P sind. Da in jeder Gitterzelle nur ein einziger Punkt liegen kann (sonst wäre vorher bereits eine Distanz <δ gefunden worden), müssen also auch nur höchstens 25 Punkte geprüft werden. Sofern in diesem Bereich keine Punkte liegen, kann P bedenkenlos in die bestehende Hashtabelle eingefügt werden.
Sind jedoch in diesem Bereich bereits weitere Punkte vorhanden, so wird die Distanz δ aktualisiert auf die neue gefundene Minimaldistanz gesetzt. Dies hat zur Folge, dass die bisherige Hashtabelle nutzlos geworden ist, weil ihre Gitterweite nicht mehr mit δ/2 übereinstimmt. Wir benötigen also eine neue Hashtabelle mit korrektem δ - wir erstellen einfach eine solche Tabelle für alle Punkte bis zu P von Grund auf neu, der Effizienz halber kann man sich beim Neuerstellen die Distanzprüfung sparen, da ja die Minimaldistanz δ aller Punkte bis hin zu P bereits bekannt ist.
Im Endeffekt hat man nach dem Einfügen eines neuen Punktes immer eine korrekte Hashtabelle mit Gitterweite δ/2 und in jedem Gitterquadrat liegt höchstens ein Punkt.Laufzeitanalyse
Relevant für die Laufzeit ist lediglich die Anzahl der Einfüge-Operationen neuer Punkte. Trivialerweise muss jeder Punkt mindestens einmal eingefügt werden, sie liegt also bei Ω(n).
Fraglich ist jedoch, wie sich der gelegentlich vorkommende Neuaufbau der Hashtabelle auswirkt, da hierfür alle bereits bekannten Punkte erneut eingefügt werden müssen. Hierfür ist es notwendig, die Wahrscheinlichkeit anzugeben, mit der beim Einfügen des i-ten Punkts ein Neuaufbau erforderlich wird, und die dafür notwendigen Kosten einzuberechnen. Intuitiv sieht man, dass mit steigender Punktzahl der Aufwand für die Reorganisation immer größer wird, die Wahrscheinlichkeit dafür aber immer kleiner. Mathematisch betrachtet:
Die Wahrscheinlichkeit dafür, dass der i-te eingefügte Punkt Pi einen Abstand δ' < δ begründet, ist < 2/i, denn dafür müsste Pi genau einer der beiden Punkte sein, die jenes δ' begründen. Da wir insgesamt i Punkte haben, von denen zwei unserer Anforderung entsprechen, ist die Wahrscheinlichkeit höchstens 2/i.
Definieren wir nun die Zufallsvariable
 . Sie sei 1, falls beim Einfügen des i-ten Punkts δ' < δ gilt, und 0 sonst.
. Sie sei 1, falls beim Einfügen des i-ten Punkts δ' < δ gilt, und 0 sonst.Dann gilt: Die Gesamtanzahl der Einfügeoperationen ist
 ; also die n sowieso einzufügenden Punkte plus die Anzahl der Einfügeoperationen durch die Neuorganisationen.
; also die n sowieso einzufügenden Punkte plus die Anzahl der Einfügeoperationen durch die Neuorganisationen.Für den Erwartungswert lässt sich aufgrund dessen Linearität sagen:
 .
.Das heißt, die Gesamtanzahl der erwarteten Einfügeoperationen bei allen Neuorganisationen der Hashtabelle ist lediglich 2n. Insgesamt ist die erwartete Laufzeit somit O(n + 2n), also linear.
Quellen
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, und Clifford Stein. Algorithmen - Eine Einführung. Oldenbourg-Verlag, 2004. ISBN 3-486-27515-1. Seiten 959–963 (Kapitel 33.4: Berechnung des dichtesten Punktepaares).
- Jon Kleinberg, Éva Tardos. Algorithm Design. Pearson International Edition, 2006. ISBN 0-321-37291-3. Seiten 225ff (Divide & Conquer); Seiten 741ff (Randomisierter Algorithmus).
Wikimedia Foundation.