- Perceptron-Konvergenz-Theorem
-
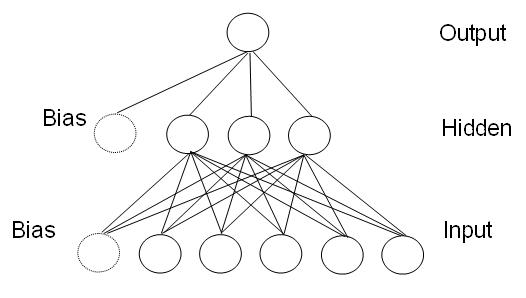
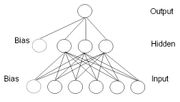 Einfaches dreilagiges feed-forward Perzeptron mit fünf Input-, drei Hidden- und einem Output-Neuron, sowie zwei Bias-Neuronen
Einfaches dreilagiges feed-forward Perzeptron mit fünf Input-, drei Hidden- und einem Output-Neuron, sowie zwei Bias-NeuronenDas Perzeptron (engl. perceptron, nach engl. perception, „Wahrnehmung“) ist ein vereinfachtes künstliches neuronales Netz, das zuerst von Frank Rosenblatt 1958 vorgestellt wurde. Es besteht in der Grundversion (einfaches Perzeptron) aus einem einzelnen künstlichen Neuron mit anpassbaren Gewichtungen und einem Schwellenwert. Unter diesem Begriff werden heute verschiedene Kombinationen des ursprünglichen Modells verstanden, dabei wird zwischen einlagigen und mehrlagigen Perzeptrons (engl. multi-layer perceptron, MLP) unterschieden. Die prinzipielle Arbeitsweise besteht darin, einen Eingabevektor in einen Ausgabevektor umzuwandeln und damit stellt es einen einfachen Assoziativspeicher dar.
Inhaltsverzeichnis
Geschichte
1943 führten die Mathematiker Warren McCulloch und Walter Pitts das "Neuron" als logisches Schwellwert-Element mit mehreren Eingängen und einem einzigen Ausgang in die Informatik ein (WS McCulloch, W Pitts: A logical calculus of the ideas immanent in nervous activity. Bull Math. Biophys., 5, 115-133, 1943). Es konnte als Bool'sche Variable die Zustände true und false annehmen und "feuerte" (= true), wenn die Summe der Eingangssignale einen Schwellenwert überschritt. Dies entsprach der neurobiologischen Analogie eines Aktionspotenzials, das eine Nervenzelle bei einer kritischen Änderung ihres Membranpotenzials aussendet. McCulloch und Pitts zeigten, dass durch geeignete Kombination mehrerer solcher Neuronen jede einfache aussagenlogische Funktion (UND, ODER, NICHT) beschreibbar ist.
1949 stellte der Psychologe Donald O. Hebb die Hypothese auf, Lernen beruhe darauf, dass sich die aktivierende oder hemmende Wirkung einer Synapse als Produkt der prä- und postsynaptischen Aktivität berechnen lasse (D Hebb: Organization of Behaviour. Wiley, New York, 1949). Es gibt gute Anhaltspunkte dass die Langzeit-Potenzierung und STDP die biologischen Korrelate des Hebbschen Postulates sind. Ein endgültiger Beweis für die Allgemeingültigkeit auch beim Menschen steht aber noch aus.
1958 schließlich publizierte Frank Rosenblatt das Perzeptron-Modell, das bis heute die Grundlage künstlicher neuronaler Netze darstellt (F Rosenblatt: The perceptron - a probablistic model for information storage and organization in the brain. Psychological Review 65, 1958).
Einlagiges Perzeptron
Beim einlagigen Perzeptron gibt es nur eine einzige Schicht aus künstlichen Neuronen, welche zugleich den Ausgabevektor repräsentiert. Jedes Neuron wird dabei durch eine Neuronenfunktion repräsentiert und erhält den gesamten Eingabevektor als Parameter. Die Verarbeitung erfolgt ganz ähnlich zur sogenannten Hebbschen Lernregel für natürliche Neuronen. Allerdings wird der Aktivierungsfaktor dieser Regel durch eine Differenz zwischen Soll- und Istwert ersetzt. Da die Hebbsche Lernregel sich auf die Gewichtung der einzelnen Eingangswerte bezieht, erfolgt also das Lernen eines Perzeptrons durch die Anpassung der Gewichtung eines jeden Neurons. Sind die Gewichtungen einmal gelernt, so ist ein Perzeptron auch in der Lage, Eingabevektoren zu klassifizieren, die vom ursprünglich gelernten Vektor leicht abweichen. Gerade darin besteht die gewünschte Klassifizierungsfähigkeit des Perzeptrons, der es seinen Namen verdankt.
Perzeptron-Lernregel
Es gibt verschiedene Versionen der Lernregel, um auf die unterschiedlichen Definitionen des Perzeptrons einzugehen. Für ein Perzeptron mit binären Ein- und Ausgabewerten wird hier die Lernregel angegeben.
Folgende Überlegungen liegen der Lernregel des Perzeptrons zu Grunde:
- Wenn die Ausgabe eines Neurons 1 (bzw. 0) ist und den Wert 1 (bzw. 0) annehmen soll, dann werden die Gewichtungen nicht geändert.
- Ist die Ausgabe 0, soll aber den Wert 1 annehmen, dann werden die Gewichte inkrementiert
- Ist die Ausgabe 1, soll aber den Wert 0 annehmen, dann werden die Gewichte dekrementiert
Mathematisch wird der Sachverhalt folgendermaßen ausgedrückt:
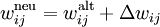 ,
,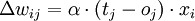 .
.
Dabei ist
- Δwij die Änderung des Gewichts wij für die Verbindung zwischen der Eingabezelle i und Ausgabezelle j,
- tj die gewünschte Ausgabe des Neurons j,
- oj die tatsächliche Ausgabe,
- xi die Eingabe des Neurons i und
- α > 0 der Lerngeschwindigkeits-Koeffizient.
Eine Gewichtsaktualisierung im Schritt k verläuft danach wie folgt:
- wij(k + 1) = wij(k) bei korrekter Ausgabe,
- wij(k + 1) = wij(k) + αxi bei Ausgabe 0 und gewünschter Ausgabe 1 und
- wij(k + 1) = wij(k) − αxi bei Ausgabe 1 und gewünschter Ausgabe 0.
Rosenblatt konnte im Konvergenztheorem nachweisen, dass mit dem angegebenen Lernverfahren alle Lösungen eingelernt werden können, die ein Perzeptron repräsentieren kann.
XOR-Problem
Frank Rosenblatt zeigte, dass ein einfaches Perzeptron mit zwei Eingabewerten und einem einzigen Ausgabeneuron zur Darstellung der einfachen logischen Operatoren AND, OR und NOT genutzt werden kann. Marvin Minsky und Seymour Papert wiesen jedoch 1969 nach, dass ein einlagiges Perzeptron den XOR-Operator nicht auflösen kann (Problem der linearen Separierbarkeit). Dies führte zu einem Stillstand in der Forschung der künstlichen neuronalen Netze (KNN).
Die in diesem Zusammenhang zum Teil äußerst polemisch geführte Diskussion war letztlich ein Richtungsstreit zwischen den Vertretern der "Künstlichen Intelligenz" und der "Konnektionisten" um Forschungsgelder. Frank Rosenblatt hatte zwar gezeigt, dass zusammengesetzte logische Operatoren wie XOR (= OR but NOT AND) durch Verwendung eines mehrlagigen Perzeptrons beschrieben werden können, er starb jedoch zu früh, um sich gegen die Angriffe seiner KI-Kollegen zu wehren.
Das Perzeptron als linearer Klassifikator
Jenseits aller (pseudo-)biologischen Analogien ist ein einlagiges Perzeptron letztlich nichts weiter als ein linearer Klassifikator der Form x = a1y1 + a2y2 + ... + anyn (lineare Diskriminanzfunktion, multiple Regression). In der Nomenklatur der künstlichen neuronalen Netze werden a1 bis an als Gewichte und y1 bis yn als Eingangssignale bezeichnet, wobei letztere nur Werte von 0 oder 1 (true oder false) annehmen können. Überschreitet die Summe x einen Schwellenwert, so wird die Zuordnung der gesuchten Klasse auf true bzw. 1 gesetzt, sonst auf false bzw. 0.
Mehrlagiges Perzeptron
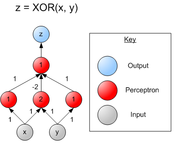 Zweilagiges Perzeptron zur Berechnung der XOR-Funktion
Zweilagiges Perzeptron zur Berechnung der XOR-FunktionDie Beschränkung des einlagigen Perzeptrons konnte später mit dem mehrlagigen Perzeptron gelöst werden, bei dem es neben der Ausgabeschicht auch noch mindestens eine weitere Schicht verdeckter Neuronen gibt (engl. hidden layer). Alle Neuronen einer Schicht sind vollständig mit den Neuronen der nächsten Schicht vorwärts verknüpft (Feedforward-Netze). Weitere Topologien haben sich ebenfalls bewährt:
- Full-Connection: Die Neuronen einer Schicht werden mit den Neuronen aller folgenden Schichten verbunden.
- Short-Cuts: Einige Neuronen sind nicht nur mit allen Neuronen der nächsten Schicht verbunden, sondern darüber hinaus mit weiteren Neuronen der übernächsten Schichten.
Ein mehrlagiges Perzeptron kann unter anderem mit dem Backpropagation-Algorithmus trainiert werden. Hierbei werden die Gewichte der Verbindungen so verändert, dass das Netz die gewünschten Muster nach einer kontrollierten Trainingsphase (engl. supervised learning) klassifizieren kann.
Siehe auch
- Künstliche Intelligenz
- Künstliche neuronale Netze
- Künstliches Neuron
- Maschinenlernen
- Mustererkennung
- Topologie (Künstliche neuronale Netze)
- Neuroinformatik
Literatur
- Rosenblatt, Frank (1958): The perceptron : a probabilistic model for information storage and organization in the brain. Psychological Reviews 65 (1958) 386-408
- M. L. Minsky und S. A. Papert, Perceptrons. 2nd Edition, MIT-Press 1988, ISBN 0-262-63111-3
Weblinks
- Ein kleiner Überblick über Neuronale Netze (D. Kriesel) - Größtes kostenloses Skriptum (knapp 200 Seiten, PDF, 4.6MB) in Deutsch zu Neuronalen Netzen. Sehr reich Illustriert und anschaulich. Enthält ein Kapitel über das Perceptron, Delta-Regel und Backpropagation etc.
- http://www-home.fh-konstanz.de/~bittel/nnfl/NeuroNetze_2.pdf
- Demo-Applet eines Perzeptrons

Wikimedia Foundation.