- Precision und Recall
-
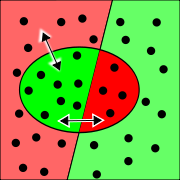 Trefferquote und Genauigkeit lassen in einer einfachen Wahrheitsmatrix aus den richtig ermittelten Treffern und falsch eingeordneten Objekten (rot) bestimmen
Trefferquote und Genauigkeit lassen in einer einfachen Wahrheitsmatrix aus den richtig ermittelten Treffern und falsch eingeordneten Objekten (rot) bestimmenTrefferquote (engl. Recall), Genauigkeit (engl. Precision) und Ausfallquote (engl. Fallout) sind Maße zur Beurteilung der Güte von Treffermengen einer Recherche beim Information Retrieval. Beim allgemeineren Fall der Beurteilung eines Klassifikators werden Trefferquote, Genauigkeit und Ausfallquote auch als Positiver Vorhersagewert, Sensitivität und umgekehrte Spezifität bezeichnet. Alle drei Maße können Werte zwischen Null und Eins (beziehungsweise 0% bis 100%) annehmen und hängen voneinander ab. Für die Bewertung eines Rechercheverfahrens sollten sie deshalb gemeinsam betrachtet werden, zum Beispiel in einem Genauigkeit-Ausfall-Diagramm oder durch abgeleitete Maße. Dies ist allerdings oft nicht problemlos möglich, da nicht alle Werte bekannt sind: Während die Genauigkeit sich nach der Auswertung einer überschaubaren Treffermenge leicht errechnen lässt, bleiben Trefferquote und Ausfall gewöhnlich theoretische Konstrukte, da sich die für ihre Berechnung erforderlichen Werte in der Praxis nicht ermitteln lassen.
Inhaltsverzeichnis
Definition
Die Trefferquote gibt mit dem Anteil der bei einer Suche gefundenen relevanten Dokumente die Vollständigkeit eines Suchergebnisses an. Die Genauigkeit beschreibt mit dem Anteil relevanter Dokumente an der Ergebnismenge die Genauigkeit eines Suchergebnisses. Der (seltener gebräuchliche) Ausfall bezeichnet den Anteil gefundener irrelevanter Dokumente an der Gesamtmenge aller irrelevanten Dokumente, er gibt also in negativer Weise an, wie gut irrelevante Dokumente im Suchergebnis vermieden werden.
Als Wahrscheinlichkeiten
Statt als Maß können Trefferquote, Genauigkeit und Ausfall auch als Wahrscheinlichkeit interpretiert werden:
- Trefferquote ist die Wahrscheinlichkeit, mit der ein relevantes Dokument gefunden wird.
- Genauigkeit ist die Wahrscheinlichkeit, mit der ein gefundenes Dokument relevant ist.
- Ausfall die Wahrscheinlichkeit, mit der ein irrelevantes Dokument gefunden wird.
Als Mengenverhältnisse
Sei R die Menge relevanter Dokumente, I die Menge irrelevanter Dokumente, sowie P (für positiv) die Menge gefundener und N (für negativ) die Menge nicht gefundener Dokumente, so ergeben sich die Maße als:
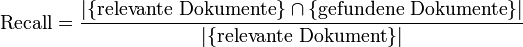

Es sei zu beachten, dass R und I sowie P und N als disjunkte Teilmengen zusammengenommen jeweils die Gesamtheit aller Dokumente ergeben.
Als Eigenschaften eines Klassifikators
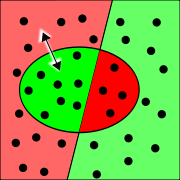 Recall
Recall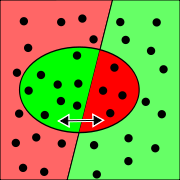 Precision
PrecisionEine Recherche kann auch als Klassierung von Dokumenten in mutmaßlich relevante Dokumente (gefunden) und mutmaßlich nicht relevante Dokumente (nicht gefunden) aufgefasst werden. Somit kann folgendes Verfahren zur Beurteilung als Klassifikator angewandt werden, das auch bei statistischen Tests Verwendung findet:
Die Grundgesamtheit aller Dokumente wird in einer Konfusionsmatrix in relevante, nicht relevante, gefundene und nicht gefundene Dokumente aufgeteilt. Es ergeben sich die vier disjunkten Teilmengen richtig gefundener, relevanter Dokumente (richtig positiv, TP), fälschlicherweise gefundener, nicht relevanter Dokumente (falsch positiv, FP), nicht gefundener, relevanter Dokumente (falsch negativ, FN) und richtigerweise nicht gefundener, nicht relevanter Dokumente (richtig negativ, TN).
Im Folgenden geben TP, FP, FN und TN die Anteile entsprechender Dokumente zwischen Null und Eins an. Im Vergleich zur Angabe durch Mengenverhältnisse gilt | R | = TP + FN, | I | = FP + TN, | P | = TP + FP und | N | = FN + TN.
Relevant (TP+FN) Nicht relevant (FP+TN) Gefunden (TP+FP) richtig positiv (TP) falsch positiv (FP) Nicht gefunden (FN+TN) falsch negativ (FN) richtig negativ (TN) Eine gute Recherche sollte möglichst alle relevanten Dokumente finden (richtig positiv) und die nicht relevanten Dokumente nicht finden (richtig negativ). Wird ein irrelevantes Dokument gefunden (falsch positiv), so spricht man bei Statistischen Tests auch von einem Fehler 1. Art oder α-Fehler und beim Nicht-Finden eines relevanten Dokumentes (falsch negativ) von einem Fehler 2. Art oder β-Fehler.
- Die Trefferquote eines Verfahrens ergibt sich aus dem Verhältnis richtig positiver zu allen relevanten Dokumente TP / (TP + FN). Er entspricht der statistischen Sensitivität (auch true positive rate, TPR).
- Die Genauigkeit ergibt sich aus dem Verhältnis richtig positiver zu allen gefundenen Dokumenten TP / (TP + FP). Sie entspricht der statistischen Relevanz (auch Positiver Vorhersagewert).
- Die Ausfallrate ergibt sich aus dem Verhältnis falsch positiver, irrelevanter Dokumente, zu allen nicht relevanten Dokumenten FP / (FP + TN). Er entspricht der statistischen false positive rate (FPR) und ist das Gegenteil der Spezifität (1 − FPR).
Veranschaulichung
Zur Veranschaulichung der Zusammenhänge zwischen Treffern, Genauigkeit und Ausfällen ist es hilfreich, die Extremfälle eines Rechercheverfahrens zu betrachten:
- Wenn eine Recherche alle Dokumente zurückliefert, ist die Trefferrate maximal. Allerdings gilt dies auch für den Ausfall. Die Genauigkeit hängt vom Anteil relevanter und nicht-relevanter Dokumente in der Grundgesamtheit ab.
- Wird nur ein einziges relevantes Dokument zurückgeliefert, ist die Genauigkeit maximal und der Ausfall minimal. Allerdings dürfte die Trefferrate sehr gering sein, da sie von der Anzahl relevanter Dokumente abhängt.
Im Allgemeinen sinkt mit steigender Trefferrate die Genauigkeit (mehr irrelevante Ergebnisse). Umgekehrt sinkt mit steigender Genauigkeit (weniger irrelevante Ergebnisse) die Trefferrate (mehr relevante Dokumente die nicht gefunden werden). Es besteht also eine negative Korrelation zwischen Treffern und Genauigkeit.
Genauigkeit-Trefferquote-Diagramm
Zur Einschätzung eines Retrievalverfahrens werden meist Trefferquote und Genauigkeit gemeinsam betrachtet. Dazu werden im so genannten Precision-Trefferquote-Diagramm (PR-Diagram) für verschieden große Treffermengen zwischen den beiden Extremen Genauigkeit auf der Ordinate und Trefferquote auf der Abszisse eingetragen. Dies ist vor allem leicht bei Verfahren möglich, deren Treffermenge durch einen Parameter gesteuert werden kann.
Der (höchste) Wert im Diagramm, an dem der Precision-Wert gleich dem Treffer-Wert ist – also der Schnittpunkt des Genauigkeit-Trefferquote-Diagramms mit der Identitätsfunktion – wird der Genauigkeit-Trefferquote-Breakeven-Punkt genannt. Da beide Werte voneinander abhängen wird auch oft der eine bei fixiertem anderen Wert genannt. Ein Irrtum ist jedoch die Interpolation zwischen den Punkten, es handelt sich um diskrete Punkte, deren Zwischenräume nicht definiert sind.
Eine Alternative zum PR-Diagramm ist eine ROC-Kurve, die auch als Trefferquote-Fallout-Diagramm bezeichnet werden könnte.
Abgeleitete Maße
Einfache Maße
Aus der Konfusionsmatrix lassen sich zur Beurteilung einer Recherche neben Precision, Trefferquote und Fallout weitere Maße ableiten:
- Die Irrtumswahrscheinlichkeit oder Falschklassifikationsrate (FP + FN) / (TP + FP + FN + TN) gibt an, mit welcher Wahrscheinlichkeit ein Dokument durch Nicht-Finden bzw. Finden falsch eingeordnet wurde, da es tatsächlich relevant bzw. nicht relevant war.
- Die Irrtumsunwahrscheinlichkeit oder Korrektklassifikationsrate (TP + TN) / (TP + FP + FP + TN) ist das Gegenteil der Irrtumswahrscheinlichkeit, also der Anteil richtig eingeschätzter Dokumente.
- Der Negative Vorhersagewert TN / (FN + TN) gibt die Wahrscheinlichkeit dafür an, dass ein nicht gefundenes Dokument auch tatsächlich irrelevant ist.
- Die Falscherkennungsrate (auch false discovery rate, FDR) FP / (TP + FP) ist der Anteil irrelevanter Dokumente, die gefunden wurden.
Je nach Anwendungsfall sind die unterschiedlichen Maße zur Beurteilung mehr oder weniger relevant. Bei einer Patentrecherche ist es beispielsweise wichtig, dass keine relevanten Patente unentdeckt bleiben (Fehler 2. Art), also sollte der Negative Vorhersagewert möglichst hoch sein. Bei anderen Recherchen ist es wichtiger, dass die Treffermenge wenig irrelevante Dokumente enthält, d.h. der Positive Vorhersagewert sollte möglichst hoch sein.
Kombinierte Maße
Zur Beurteilung der Güte mit einer einzigen Kennzahl wurden verschiedene Maße vorgeschlagen.
Das F-Maß kombiniert Genauigkeit und Trefferquote mittels des gewichteten harmonischen Mittels:
Neben diesem auch als F1 bezeichneten Maß, bei dem Precision und Trefferquote gleich gewichtet sind, gibt es auch andere Gewichtungen. Der Allgemeinfall ist das Maß Fα (für positive Werte von α):
Beispielsweise gewichtet F2 die Trefferquote doppelt so groß wie die Genauigkeit und F0.5 die Genauigkeit doppelt so hoch wie den Trefferquote.
Das Effektivitätsmaß (E) entspricht ebenfalls dem gewichteten harmonischen Mittel. Es wurde 1979 von van Rijsbergen eingeführt. Die Effektivität liegt zwischen 0 (beste Effektivität) und 1 (schlechte Effektivität). Für einen Parameterwert von α = 0 ist E äquivalent zur Trefferquote, für einen Parameterwert von α = 1 äquivalent zur Genauigkeit.
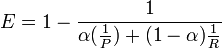
Beispiel
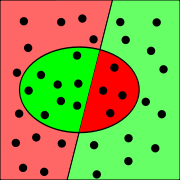 Beispiel (siehe Text)
Beispiel (siehe Text)In einer Datenbank mit 36 Dokumenten sind zu einer Suchanfrage Dokumente 20 relevant und 16 nicht relevant. Eine Suche liefert 12 Dokumente, von denen tatsächlich 8 relevant sind. In nebenstehender Grafik sind die relevanten Dokumente links, die nicht relevanten rechts, und die gefundenen Dokumente innerhalb des Ovals eingezeichnet. Die übereinstimmenden Fälle sind grün und die Fehler rot.
Relevant Nicht relevant Gefunden 8 4 Nicht gefunden 12 12 Trefferquote und Precision für die konkrete Suche ergeben sich aus den Werten der Konfusionsmatrix.
- Genauigkeit:
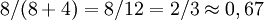
- Trefferquote: 8 / (8 + 12) = 8 / 20 = 2 / 5 = 0,4
- Fallout: 4 / (4 + 12) = 4 / 16 = 1 / 4 = 0,25
Praxis und Probleme
Ein Problem bei der Berechnung der Trefferquote ist die Tatsache, dass man nur selten weiß, wie viele relevante Dokumente insgesamt existieren und nicht gefunden wurden (c, Fehler 2. Art). Bei größeren Datenbanken, bei denen die Berechnung der absoluten Trefferquote besonders schwierig ist, wird deswegen mit der relativen Trefferquote gearbeitet. Dabei wird die gleiche Suche mit mehreren Suchmaschinen durchgeführt und die jeweils neuen relevanten Treffer zu den nicht gefundenen relevanten Dokumenten hinzu addiert. Mit der Rückfangmethode kann abgeschätzt werden, wie viele relevante Dokumente insgesamt existieren.
Problematisch ist auch, dass zur Bestimmung von Trefferquote und Genauigkeit die Relevanz eines Dokumentes als Wahrheitswert (ja/nein) bekannt sein muss. In der Praxis ist jedoch oft die Subjektive Relevanz von Bedeutung. Auch für gerankte Treffermengen ist die Angabe von Trefferquote und Precision oft nicht ausreichend, da es nicht nur darauf ankommt, ob ein relevantes Dokument gefunden wird, sondern auch ob es im Vergleich zu nicht relevanten Dokumenten genügend hoch gerankt wird. Bei sehr unterschiedlich großen Treffermengen kann die Angabe durchschnittlicher Werte für Trefferquote und Genauigkeit irreführend sein.
Literatur
- Makhoul, John; Francis Kubala; Richard Schwartz; Ralph Weischedel: Performance measures for information extraction. In: Proceedings of DARPA Broadcast News Workshop, Herndon, VA, February 1999.
- Baeza-Yates, R.; Ribeiro-Neto, B. (1999). Modern Information Retrieval. New York: ACM Press, Addison-Wesley. Seiten 75 ff. ISBN 0-201-39829-X
- Womser-Hacker, Christa: Theorie des Information Retrieval III: Evaluierung. In R. Kuhlen: Grundlagen der praktischen Information und Dokumentation. München. Saur, 5. Auflage 2004. Seiten 227-235. ISBN 3-598-11675-6, ISBN 3-598-11674-8
- van Rijsbergen, C.V.: Information Retrieval. London; Boston. Butterworth, 2nd Edition 1979. ISBN 0-408-70929-4
- Jesse Davis und Mark Goadrich: The Relationship Between Precision-Recall and ROC Curves. In: 23rd International Conference on Machine Learning (ICML), 2006.
Weblinks

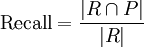
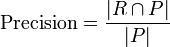
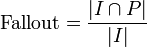


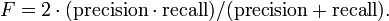
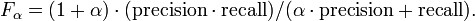

Wikimedia Foundation.