- Rainbow-Tabelle
-
Die rainbow table (zu Deutsch: Regenbogentabelle) ist eine von Philippe Oechslin entwickelte Datenstruktur, die eine schnelle, probabilistische Suche nach Hash-Werten ermöglicht. Der sogenannte Time-Memory-Tradeoff gestattet die Suche nach fast allen Hashes in akzeptabler Zeit, ohne wirklich alle Hashes physikalisch zu speichern. Dieses funktioniert bei Hash-Funktionen ohne Salt, wie es z. B. bei den Passwörtern für Windows NT, einigen PHP-Installationen oder vielen Routern der Fall ist.
Inhaltsverzeichnis
Überblick
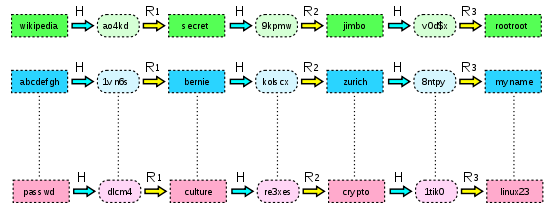 Vereinfachte rainbow table mit 3 Iterationen
Vereinfachte rainbow table mit 3 IterationenEin rainbow table ist eine kompakte Repräsentation von zusammenhängenden Passwortsequenzen, sogenannten Ketten (Chains). Jede dieser Ketten startet mit einem initialen Kennwort, welches durch eine Hash-Funktion geleitet wird. Der resultierende Hash wird wiederum durch eine Reduktionsfunktion geleitet, mit dem Ergebnis, ein weiteres potentielles Klartextkennwort zu haben. Dieser Prozess wird für eine vorgegebene Anzahl wiederholt, und schließlich das erste Kennwort der Kette zusammen mit dem letzten Hashwert gespeichert.
Beim Erstellen der Tabelle ist darauf zu achten, dass einerseits kein Kennwort, welches in einer Kette vorkommt, als Startkennwort verwendet wird (Kollision), dass andererseits alle möglichen Kennwörter in der Tabelle vorkommen. Die Tabellen werden nur einmalig erstellt und dienen dann als Nachschlagetabelle.
Um ein Kennwort herauszufinden, wird ein zweistufiger Prozess benötigt. Zunächst wird der Hash des herauszufindenden Kennworts durch die oben beschriebene Hash-Reduktion-Sequenz geführt, bis der Hash als "rechte Seite" der Tabelle vorkommt. Damit erhält man das Startkennwort der Kette, und kann im zweiten Schritt von diesem ausgehend die Hash-Reduktion-Sequenz anwenden, um das gesuchte Kennwort zu erhalten.
Die Länge der Kette, also die Anzahl der Iterationen zur Erstellung der Tabellen, wirken sich auf die Größe der Tabelle aus: Je länger die Iterationen gewählt werden, desto kleiner ist die entstehende Tabelle. Im einfachsten Fall ist die Anzahl der Iterationen gleich 1, sodass die Tabelle alle Kennwort-Hash-Paare enthält.
Funktionsweise
Eine zufällige Zeichenkette wird durch eine Hash-Funktion H in einen Ciphertext transformiert. Das Ergebnis der Hash-Funktion wird durch eine Reduktions-Funktion R in eine neue Zeichenkette umgewandelt, die die gleiche Länge der Eingangs-Zeichenkette besitzt. Dieser Schritt wird n-mal wiederholt und bildet am Ende eine Kette (Chain). Gespeichert werden Anfangs- und Endwert dieser Kette. Diese Schrittfolge wird ebenfalls x-mal wiederholt und bildet eine universelle Rainbow-Tabelle.
Reduktionsfunktion
Diese Funktion reduziert als Beispiel den 32 Zeichen langen MD5-Hash auf n Zeichen. Jede dieser Reduktionen liefert dank MD5 eine neue, "eindeutige" Zeichenkette oder eine Kollision. Um Kollisionen zu vermeiden, verwendet man verschiedene Reduktionsfunktionen die, periodisch angewendet, eine eindeutige Zuordnung der Eingangs-Zeichenkette und des Ausgangshashes ermöglichen. Dieses Verfahren stellt eine effizientere Methode für n-stellige Zeichenketten dar als beispielsweise ein Brute-Force-Angriff mit Schlüsselsuche von [a-//////], da bei letzterem viele Zeichenketten in Hashes umgewandelt werden, die mit hoher Wahrscheinlichkeit niemals fallen, bzw. gewählt, werden.
Anwendung
Gesucht wird die Zeichenfolge, aus der mittels MD5 der Hash-Wert 97fae39bfd56c35b6c860aa468c258e0 erzeugt wurde (Domino). Der herkömmliche Weg, alle MD5-Hashes für alle möglichen Variationen zu berechnen und diese zu vergleichen, ist sehr rechenintensiv und muss bei neuen Suchläufen wiederholt werden.
Sinnvoll wäre es nun, die bereits berechneten Hashes in einer Datenbank zu speichern und bei erneuten Suchläufen nur noch vergleichen zu müssen, ob der gesuchte Hash schon bekannt ist. Bei einer Suche über 64 mögliche Zeichen [A-Za-z0-9./], die jede Stelle des Eingangstextes haben könnte, ergeben sich bei 6 Stellen 646 Variationen. Werden nun Hash und Wert (KEY-VALUE Pairs) in einer Datenbank gespeichert, so werden pro Datenbankreihe mindestens 32 Bytes für den Hash und 6 Bytes für den Plaintext benötigt und somit für die kompletten Daten etwa 2,4 Terabyte.
Diese Datenmengen lassen sich meistens nicht verarbeiten und müssen reduziert werden.
Sinnvoller Mittelweg ist nun die Rainbow-Tabelle
Anstatt alle Werte samt Schlüsseln zu speichern, werden nur die anfängliche Zeichenkette und der Ausgangswert (Hash) einer n-elementigen Kette gespeichert. Auf diese Weise lassen sich n-Hashes durch einen Start- und Endwert repräsentieren und in vergleichsweise kurzer Zeit neu berechnen, wiederfinden. Bildet sich aus einem reduzierten Hash(=Plaintext) durch erneutes Hashen ein Final-Hash, so wird diese Kette neu berechnet: Bei einer Ketten-Länge von 10.000 bestehen nun 10.000 Chancen, genau den Hash zu finden, der gesucht wird.
Bei schlecht programmierten oder trivialen Reduktionsfunktionen treten nach wenigen Läufen Kollisionen auf, die zu Wiederholungen der reduzierten Texte und somit auch der Hashes führen. Solche internen Schleifen tragen dann dazu bei, dass der Algorithmus versagt: Man berechnet mühsam Tausende von Elementen und nur 5 im Worst-Case sind eindeutig unterscheidbar.
Die Wahrscheinlichkeit, aus den reduzierten Hashes genau den gesuchten Eingangstext zu erhalten, ist abhängig von der Güte der Reduktionsfunktion(en) und den Parametern bei der Erstellung der Rainbow-Tabelle, da nur die reduzierten Hashes(=Plaintexts) später gefunden werden können. Wenn die Reduktionsfunktion(en) beispielsweise nur auf Zahlen reduzieren, kann der Plaintext "Domino" nicht gefunden werden. Wenn die Reduktionsfunktion(en) auf 7 Stellen reduzieren(von 32), dann werden 6-stellige Plaintexts nicht berechnet und auch hier kann "Domino" nicht gefunden werden.
Gegenmaßnahmen
Eine wirkungsvolle Möglichkeit, den Einsatz von Rainbow Tables zum Entschlüsseln zu erschweren, ist es, Hash-Funktionen mit Salt einzusetzen. Durch den Salt wird erreicht, dass vorberechnete Tabellen ohne diesen Salt unwirksam sind.
Siehe auch
Weblinks

Wikimedia Foundation.