- Rechenaufwand
-
Komplexität bezeichnet in der Informatik die „Kompliziertheit“ von Problemen, Algorithmen oder Daten. Die Komplexitätstheorie befasst sich dabei mit dem Ressourcenverbrauch von Algorithmen, die Informationstheorie dagegen verwendet den Begriff für den Informationsgehalt von Daten (siehe unten).
Inhaltsverzeichnis
Komplexität von Algorithmen
Unter der Komplexität (auch Aufwand oder Kosten) eines Algorithmus (nicht zu verwechseln mit der Algorithmischen Komplexität, siehe unten) versteht man in der Komplexitätstheorie seinen maximalen Ressourcenbedarf. Dieser wird oft in Abhängigkeit von der Länge n der Eingabe angegeben und für große n asymptotisch unter Verwendung eines Landau-Symbols abgeschätzt. Analog wird die Komplexität eines Problems definiert durch den Ressourcenverbrauch eines optimalen Algorithmus zur Lösung dieses Problems. Die Schwierigkeit liegt darin, dass man somit alle Algorithmen für ein Problem betrachten müsste, um die Komplexität desselben zu bestimmen.
Die betrachteten Ressourcen sind fast immer die Anzahl der benötigten Rechenschritte (Zeitkomplexität) oder der Speicherbedarf (Platzkomplexität) - die Komplexität kann aber auch bezüglich einer anderen Ressource bestimmt werden. Dabei interessiert nicht der Aufwand eines konkreten Programms auf einem bestimmten Computer, sondern viel mehr, wie der Ressourcenbedarf wächst, wenn mehr Daten zu verarbeiten sind, also z. B. ob sich der Aufwand für die doppelte Datenmenge verdoppelt oder quadriert (Skalierbarkeit).
Oft ist es sehr aufwändig oder ganz unmöglich, eine Funktion anzugeben, die allgemein zu jeder beliebigen Eingabe für ein Problem den zugehörigen Aufwand an Ressourcen angibt. Daher begnügt man sich in der Regel damit, statt jede Eingabe einzeln zu erfassen, sich lediglich mit der Eingabelänge n = | w | zu befassen. Es ist aber meist sogar zu schwierig, eine Funktion
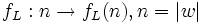 anzugeben. Daher beschränkt man sich häufig darauf, eine obere und untere Schranke für das asymptotische Verhalten anzugeben. Hierfür wurden die Landau-Symbole entwickelt.
anzugeben. Daher beschränkt man sich häufig darauf, eine obere und untere Schranke für das asymptotische Verhalten anzugeben. Hierfür wurden die Landau-Symbole entwickelt.Algorithmen und Probleme werden in der Komplexitätstheorie gemäß ihrer so bestimmten Komplexität in so genannte Komplexitätsklassen eingeteilt. Diese sind ein wichtiges Werkzeug, um bestimmen zu können, welche Probleme „gleich schwierig“, beziehungsweise welche Algorithmen „gleich mächtig“ sind. Dabei ist die Frage, ob zwei Komplexitätsklassen gleichwertig sind, oft nicht einfach zu entscheiden (siehe zum Beispiel P-NP-Problem).
Die Komplexität eines Problems ist zum Beispiel entscheidend für die Kryptographie und insbesondere für die asymmetrische Verschlüsselung: So verlässt sich zum Beispiel das RSA-Verfahren auf die Vermutung, dass die Primfaktorzerlegung von großen Zahlen nur mit sehr viel Aufwand zu berechnen ist - anderenfalls ließe sich aus dem öffentlichen Schlüssel leicht der private Schlüssel errechnen.
Komplexität von Daten
In der Informationstheorie versteht man unter der Komplexität von Daten bzw. einer Nachricht ihren Informationsgehalt. Neben der klassischen Definition dieser Größe nach Claude Shannon gibt es verschiedene andere Ansätze, zu bestimmen, wie viel Information in einer Datenmenge enthalten ist:
Zum einen gibt es die so genannte Kolmogorow-Komplexität (auch Algorithmische Komplexität oder Beschreibungskomplexität), die den Informationsgehalt als die Größe des kleinsten Programms definiert, dass in der Lage ist, die betrachteten Daten zu erzeugen. Sie beschreibt eine absolut optimale Komprimierung der Daten. Eine Präzisierung des Ansatzes Andrei Kolmogorows bezüglich des Maschinenmodells bietet die Algorithmische Informationstheorie von Gregory Chaitin.
Dagegen betrachtet Algorithmische Tiefe (auch Logische Tiefe) die Zeitkomplexität eines optimalen Algorithmus zur Erzeugung der Daten als Maß für den Informationsgehalt.
Siehe auch
Weblinks
- Aufzeichnungen der Vorlesungsreihe "Komplexitätstheorie" (SS 2008, 27 Vorlesungen) von Prof. Dr. Christoph Meinel, Hasso-Plattner-Institut
- Videovorlesung „Komplexität und Verifikation – O-Notation, Analyse von Schleifen, Analyse eines rekursiven Programms“ im WS 2007/08 – Prof. Dr. Oliver Vornberger, Universität Osnabrück, Fachbereich Mathematik/Informatik (Spieldauer 85 Min)
Wikimedia Foundation.