- Selbstorganisierende Karten
-
Als Selbstorganisierende Karten, Kohonenkarten oder Kohonennetze (nach Teuvo Kohonen) bezeichnet man eine Art von künstlichen neuronalen Netzen. Sie sind als unüberwachtes Lernverfahren ein leistungsfähiges Werkzeug des Data-Mining. Ihr Funktionsprinzip beruht auf der biologischen Erkenntnis, dass viele Strukturen im Gehirn eine lineare oder planare Topologie aufweisen. Die Signale des Eingangsraums, z. B. visuelle Reize, sind jedoch multidimensional.
Es stellt sich also die Frage, wie diese multidimensionalen Eindrücke durch planare Strukturen verarbeitet werden. Biologische Untersuchungen zeigen, dass die Eingangssignale so abgebildet werden, dass ähnliche Reize nahe beieinander liegen. Der Phasenraum der angelegten Reize wird also kartiert.
Wird nun ein Signal an diese Karte herangeführt, so werden nur diejenigen Gebiete der Karte erregt, die dem Signal ähnlich sind. Die Neuronenschicht wirkt als topologische Merkmalskarte, wenn die Lage der am stärksten erregten Neuronen in gesetzmäßiger und stetiger Weise mit wichtigen Signalmerkmalen korreliert ist.
Inhaltsverzeichnis
Laterale Umfeldhemmung
Ein allgemeines Arbeitsprinzip des Nervensystems ist, dass aktive lokale Gruppen von Nervenzellen andere Gruppen ihrer Umgebung hemmen, und somit deren Aktivität unterdrücken (siehe laterale Hemmung). Die Aktivität einer Nervenzelle wird daher aus der Überlagerung des erregenden Eingangssignals und den hemmenden Beiträgen aller Schichtneuronen bestimmt. Da diese laterale Hemmung überall gilt, kommt es zu einem ständigen Wettbewerb um die Vorherrschaft. Der Verlauf der lateralen Hemmung ist für kurze Distanzen erregend/verstärkend und für lange Distanzen hemmend/schwächend. Es lässt sich zeigen, dass dieser Effekt ausreichend ist, eine Lokalisierung der Erregungsantwort in der Nähe der maximalen äußeren Erregung zu bewirken.
Struktur und Lernen
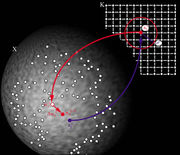 Ein Adaptionsschritt: Der Reiz v zieht an dem Gewichtsvektor w des am besten angepassten Neurons. Dieser Zug wird mit zunehmenden Abstand, gemessen im Competitive Layer vom besten Neuron zunehmend schwächer. Einfach ausgedrückt, beult sich die Karte in Richtung des Reizes v aus.
Ein Adaptionsschritt: Der Reiz v zieht an dem Gewichtsvektor w des am besten angepassten Neurons. Dieser Zug wird mit zunehmenden Abstand, gemessen im Competitive Layer vom besten Neuron zunehmend schwächer. Einfach ausgedrückt, beult sich die Karte in Richtung des Reizes v aus.Die Struktur einer Self-Organizing Map: Ein Inputlayer mit n Neuronen ist vollständig mit allen Neuronen innerhalb der Kohonenkarte, im Folgenden mit Competitive Layer bezeichnet, verbunden. Jeder zu kartierende Eingangsreiz v wird über die Verbindungen an jedes Neuron dieses Competitive Layers weitergegeben.
Die Verbindungsgewichte w zwischen den Neuronen der Eingabeschicht und den Neuronen im Competitive Layer definieren je einen Punkt im Eingangsraum der angelegten Reize v. Alle Neuronen innerhalb des Competitive Layers sind untereinander inhibitorisch (hemmend) vernetzt.
- Die Abbildung zeigt einen Adaptionschritt im Modell von Kohonen. Ein Reiz v wird an das Netz angelegt.
- Das Netz sucht das Erregungszentrum s im Competitive Layer, dessen Gewichtsvektor w am nächsten zu v liegt (kleinster Abstand).
- Der Unterschied zwischen w und v wird in einem Adaptionsschritt verringert.
- Die Neuronen nahe am Erregungszentrum s werden auch adaptiert, aber umso weniger, je weiter sie vom Erregungszentrum entfernt sind.
Es ist gebräuchlich, aber nicht zwingend, sowohl für die Lernvektoren als auch für das Competitive Layer den euklidischen Abstand als Abstandsmaß zu verwenden.
Steht ein Satz verschiedener Trainingsdaten zur Verfügung, so ist eine Epoche im Training vollständig, wenn alle Reize genau einmal in zufälliger Reihenfolge an das Inputlayer angelegt worden sind. Das Training endet, wenn das Netz seinen stabilen Endzustand erreicht hat.
Das Lernen in einer Self-Organizing Map kann formal als iterativer Prozess beschrieben werden. Im Anfangszustand sind die Gewichtsvektoren der Neuronen zufällig im Netz verteilt. In jedem Lernschritt wird an das Netz ein Reiz angelegt. Die neuronale Self-Organizing Map verändert die Gewichtsvektoren der Neuronen entsprechend der Hebbschen Lernregel, sodass sich im Laufe der Zeit eine topografische Abbildung ergibt.
Training einer SOM im Beispiel
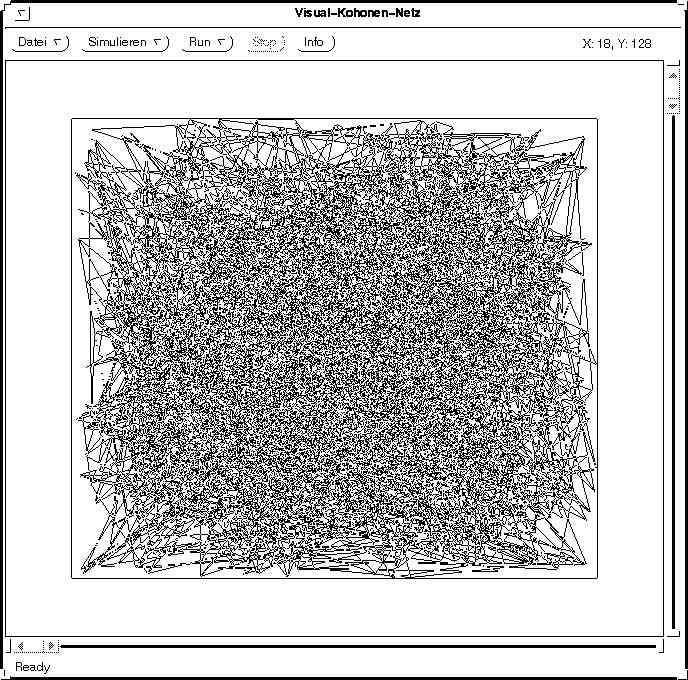
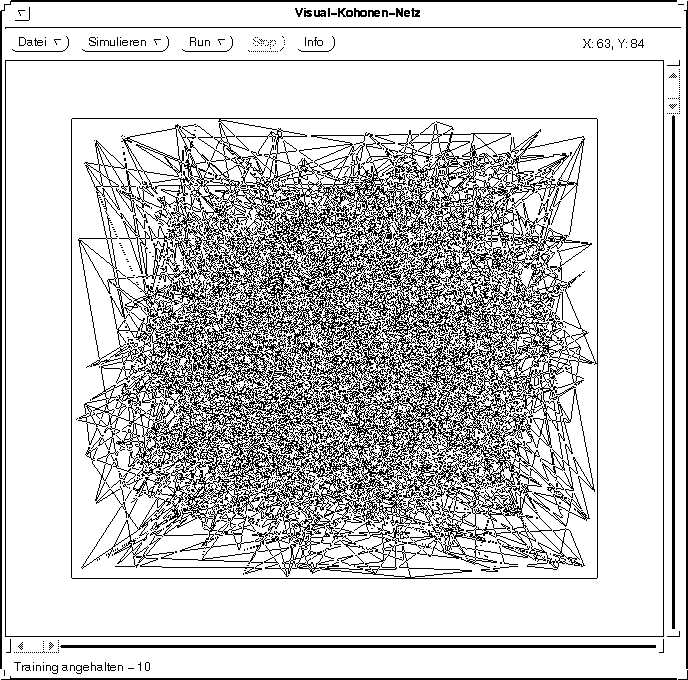
Die folgende Tabelle zeigt ein Netz, dessen Neuronen in einem Gitter angeordnet sind und zu Beginn zufällig im Raum verteilt sind. Es wird mit Eingabereizen aus dem Quadrat trainiert, die gleichverteilt sind.
 Zufällig initialisiertes Netz
Zufällig initialisiertes Netz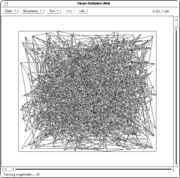 10 Trainingschritte
10 Trainingschritte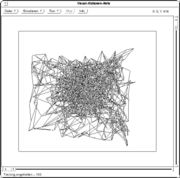 100 Trainingsschritte
100 Trainingsschritte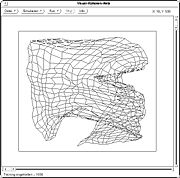 1.000 Trainingsschritte
1.000 Trainingsschritte 10.000 Trainingsschritte
10.000 Trainingsschritte 100.000 Trainingsschritte
100.000 TrainingsschritteFormale Beschreibung des Trainings
Gegeben ist eine endliche Menge M von Trainingsstimuli mi, die durch einen n-dimensionalen Vektor xi spezifiziert sind:
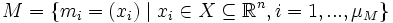
Weiterhin sei eine Menge von μN Neuronen gegeben, denen jeweils ein Gewichtsvektor wi in X und eine Position ki auf einer Kohonen-Karte zugeordnet wird, die im weiteren als zweidimensional angenommen wird. Die Kartendimension kann beliebig-dimensional gewählt werden, wobei Kartendimensionen kleiner-gleich drei zur Visualisierung von hochdimensionalen Zusammenhängen verwendet werden. Die Positionen auf der Karte sollen diskreten, quadratischen Gitterpunkten entsprechen (alternative Nachbarschaftstopologien wie z. B. hexagonale Topologien sind ebenfalls möglich), und jeder Gitterpunkt soll durch genau ein Neuron besetzt sein:
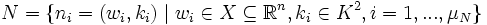
In der Lernphase wird aus der Menge der Stimuli zum Präsentationszeitpunkt t ein Element mjt gleichverteilt zufällig ausgewählt. Dieser Stimulus legt auf der Karte ein Gewinnerneuron nst fest, das als Erregungszentrum bezeichnet wird. Es handelt sich dabei um genau das Neuron, dessen Gewichtsvektor wst den geringsten Abstand im Raum X zu dem Stimulusvektor xjt besitzt, wobei eine Metrik dX(.,.) des Inputraumes gegeben sei:
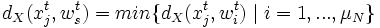
Nachdem nst ermittelt wurde, werden alle Neuronen nit bestimmt, die neben dem Erregungszentrum ihre Gewichtsvektoren anpassen dürfen. Es handelt sich dabei um die Neuronen, deren Entfernung dA(ks, ki) auf der Karte nicht größer ist als ein zeitabhängiger Schwellenwert, der als Entfernungsreichweite δt bezeichnet wird, wobei eine Metrik dA(.,.) der Karte gegeben sei. Diese Neuronen werden in einer Teilmenge N+t ⊂ Nt zusammengefasst:
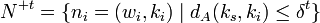
Im folgenden Adaptionsschritt wird auf alle Neuronen aus N+t ein Lernschritt angewendet, der die Gewichtsvektoren verändert. Der Lernschritt ist interpretierbar als eine Verschiebung der Gewichtsvektoren in Richtung des Stimulusvektors xjt, wobei in der nachstehenden Abbildung die Verschiebung des Gewichtsvektors des Gewinnerneurons dargestellt ist.
Es wird entsprechend dem Modell von Ritter et al. (1991) dabei die folgende Adaptionsregel verwendet:
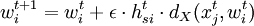
mit den zeitabhängigen Parametergleichungen εt und hsit, die festgelegt werden als: 1) Die zeitabhängige Lernrate εt:
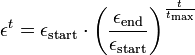
mit der Startlernrate εstart und εend als der Lernrate zum Ende des Verfahrens, d.h. nach tmax Stimuluspräsentationen.
2) Die zeitabhängige Entfernungsgewichtungsfunktion hsit:
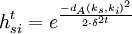
mit δt als dem Nachbarschafts- oder Adaptionsradius um das Gewinner-Neuron auf der Karte:
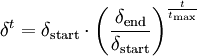
mit dem Adaptionsradius δstart zum Anfang des Verfahrens, und δend als dem Adaptionsradius zum Ende des Verfahrens.
Damit eine topologie-erhaltende Abbildung entsteht, d.h. dass benachbarte Punkte im Inputraum X auf benachbarte Punkte auf der Karte abgebildet werden, müssen zwei Faktoren berücksichtigt werden:
- Die topologische Nachbarschaft hsit um das Erregungszentrum muss anfangs groß gewählt und im Laufe des Verfahrens verkleinert werden.
- Die Adaptionsstärke εt muss ausgehend von einem großen Wert im Laufe des Verfahrens auf einen kleinen Restwert sinken.
In dem dargestellten Lernprozess werden tmax Präsentationen durchgeführt, wonach die SOM in die Anwendungsphase überführt werden kann, in der Stimuli präsentiert werden, die in der Lernmenge nicht vorkamen. Ein solcher Stimulus wird dem Gewinnerneuron zugeordnet, dessen Gewichtsvektor die geringste Distanz von dem Stimulusvektor besitzt, sodass dem Stimulus über den Umweg des Gewichtsvektors ein Neuron und eine Position auf der Neuronenkarte zugeordnet werden kann. Auf diese Weise wird der neue Stimulus automatisch klassifiziert und visualisiert.
Varianten der SOM
Es wurden eine Vielzahl von Varianten und Erweiterungen zu dem ursprünglichen Modell von Kohonen entwickelt, u.a.:
- Kontext-SOM (K-SOM)
- Temporäre SOM (T-SOM)
- Motorische SOM (M-SOM)
- Neuronen-Gas (NG-SOM)
- Wachsende Zellstrukturen (GCS-SOM)
- Wachsende Gitterstruktur (GG-SOM)
- Wachsende hierarchische SOM (GH-SOM)
- Wachsendes Neuronen-Gas (GNG-SOM)
- Parametrische SOM (P-SOM)
- Hyperbolische SOM (H-SOM)
- Interpolierende SOM (I-SOM)
- Local-Weighted-Regression-SOM (LWR-SOM)
- Selektive-Aufmerksamkeits-SOM (SA-SOM)
- Gelernte Erwartungen in GNG-SOMs (LE-GNG-SOM)
- Fuzzy-SOM (F-SOM)
- Adaptive-Subraum-SOM (AS-SOM)
- Generative Topographische Karte (GTM)
Literatur
- Günter Bachelier: Einführung in selbstorganisierende Karten. Tectum-Verlag, Marburg 1998, ISBN 3-8288-5017-0
- Teuvo Kohonen: Self-Organizing Maps. Springer-Verlag, Berlin 1995, ISBN 3-540-58600-8
- Helge Ritter, Thomas Martinetz, Klaus Schulten: Neuronale Netze. Eine Einführung in die Neuroinformatik selbstorganisierender Netzwerke. Addison-Wesley, Bonn 1991, ISBN 3-89319-131-3
Weblinks
- SOM-Research an der Helsinki University of Technology (Teuvo Kohonen)
- Anwendungen dort u. a. websom
- Prof. Fritzke, Dresden: Growing SOM
- DemoGNG Anwendung zur Demonstration verschiedener Lernalgorithmen
- Über SOM in der comp.ai.neural-nets FAQ
- Datenbionik: Datenvisualisierung und Data Mining mit Emergenten SOM: Prof. Ultsch Marburg
- MusicMiner: Visualisierung von Musiksammlungen ESOM
- SOM-Kapitel (mit weiteren Links und Applets) einer KI-Vorlesung von David Grimshaw, Toronto
- GNOD, The Global Network of Dreams, ein Kohonen-Netz zur Bestimmung von Ähnlichkeiten von Musik, Film und Buchautoren [1].
- Demonstrationsbeispiel: HTW Dresden - ein SOM fängt einen Ball
- Viscovery SOMine: SOM Technologie Tool von Viscovery
- Kohonen Map Java Applet
- Neural Networks with Java




Wikimedia Foundation.