- Text Mining
-
Text Mining, seltener auch Textmining, Text Data Mining oder Textual Data Mining, ist ein Bündel von Analyseverfahren, die die algorithmusassistierte Entdeckung von Bedeutungsstrukturen aus un- oder schwachstrukturierten Textdaten ermöglichen soll. Mit statistischen und linguistischen Mitteln erschließt Text-Mining-Software aus Texten Strukturen, die die Benutzer in die Lage versetzen sollen, Kerninformationen aus den verarbeiteten Texten schnell zu erschließen. Text-Mining-Systeme liefern im Optimalfall Informationen, von denen Benutzer zuvor nicht wussten, dass sie existieren. Im Zusammenspiel mit ihren Anwendern sind Werkzeuge des Text Minings außerdem dazu in der Lage, Hypothesen zu generieren, diese zu überprüfen und schrittweise zu verfeinern.
Inhaltsverzeichnis
Konzept
Das 1995 von Ronen Feldman und Ido Dagan als „Knowledge Discovery from Text (KDT)“[1] in die Forschungsterminologie eingeführte Text Mining[2] ist kein klar definierter Begriff. In Analogie zu Data-Mining in der Knowledge Discovery in Databases (KDD) ist Text Mining ein weitgehend automatisierter Prozess der Wissensentdeckung in textuellen Daten, der eine effektive und effiziente Nutzung verfügbarer Textarchive ermöglichen soll.[3] Umfassender kann Text Mining als ein Prozess der Zusammenstellung, Organisation und Analyse großer Dokumentsammlungen zur bedarfsgerechten Extrahierung von Informationen und der Entdeckung versteckter Beziehungen zwischen Texten und Textfragmenten gesehen werden.
Typologien
Die unterschiedlichen Auffassungen von Text Mining können mittels verschiedener Typologien geordnet werden. Dabei werden Arten des Information Retrieval (IR),[4] des Dokumenten-Clustering, des Text Data-Mining und des KDD[5] immer wieder als Unterformen des Text Mining genannt.
Beim IR ist dabei bekannt, dass die Textdaten bestimmte Fakten enthalten, die mittels geeigneter Suchanfragen gefunden werden sollen. In der Data-Mining-Perspektive wird Text Mining als „Data-Mining auf textuellen Daten“ verstanden, zur Exploration von (interpretationsbedürftigen) Daten aus Texten. Die weitestgehende Art des Text Mining ist das eigentliche KDT, bei der neue, zuvor unbekannte Information aus den Texten extrahiert werden sollen.[6]
Verwandte Verfahren
Text Mining ist mit einer Reihe anderer Verfahren verwandt, von denen es wie folgt abgegrenzt werden kann.
Am stärksten ähnelt Text Mining dem Data-Mining. Mit diesem teilt es viele Verfahren, nicht jedoch den Gegenstand: Während Data-Mining zumeist auf stark strukturierte Daten angewandt wird, befasst sich Text Mining mit wesentlich schwächer strukturierten Textdaten. Beim Text Mining werden deshalb in einem ersten Schritt die Primärdaten stärker strukturiert, um ihre Erschließung mit Verfahren des Data-Mining zu ermöglichen.[7] Anders als bei den meisten Aufgaben des Data-Mining sind zudem Mehrfachklassifikationen beim Text Mining meist ausdrücklich erwünscht.[8]
Des Weiteren greift Text Mining auf Verfahren des Information Retrieval zurück, die für die Auffindung derjenigen Textdokumente, die für die Beantwortung einer Suchanfrage relevant sein sollen, konzipiert sind.[9] Im Gegensatz zum Text Mining werden also nicht möglicherweise unbekannte Bedeutungsstrukturen im Gesamttextmaterial erschlossen, sondern anhand von bekannten Schlüsselwörtern eine Menge relevant erhoffter Einzeldokumenten identifiziert.[10]
Verfahren der Informationsextraktion zielen darauf ab, aus Texten einzelne Fakten zu extrahieren. Informationsextraktion verwendet oft die gleichen oder ähnliche Verfahrensschritte wie dies im Text Mining getan wird;[11] bisweilen wird Informationsextraktion deshalb als Teilgebiet des Text Mining betrachtet.[12] Im Gegensatz zu (vielen anderen Arten des) Text Mining sind hier aber zumindest die Kategorien bekannt, zu denen Informationen gesucht werden - der Benutzer weiß, was er nicht weiß.
Verfahren des automatischen Zusammenfassens von Texten, der Text Extraction, erzeugen ein Kondensat eines Text oder einer Textsammlung;[13] dabei wird jedoch, anders als beim Text Mining, nicht über das in den Texten explizit Vorhandene hinausgegangen.
Anwendungsgebiete
Web Mining, insbesondere Web Content Mining, ist ein wichtiges Anwendungsgebiet für Text Mining.[14] Noch relativ neu sind Versuche, Text Mining als Methode der sozialwissenschaftlichen Inhaltsanalyse zu etablieren, beispielsweise Sentiment Detection zur automatischen Extraktion von Haltungen gegenüber einem Thema.
Methodik
Text Mining geht in mehreren Standardschritten vor: Zunächst wird ein geeignetes Datenmaterial ausgewählt. In einem zweiten Schritt werden diese Daten so aufbereitet, dass sie im Folgenden mittels verschiedener Verfahren analysiert werden können. Schließlich nimmt die Ergebnispräsentation einen ungewöhnlich wichtigen Teil des Verfahrens ein. Alle Verfahrensschritte werden dabei softwareunterstützt.
Datenmaterial
Text Mining wird auf eine (meist sehr große) Menge von Textdokumenten angewandt, die gewisse Ähnlichkeiten hinsichtlich ihrer Größe, Sprache und Thematik aufweisen.[15] In der Praxis stammen diese Daten meist aus umfangreichen Textdatenbanken wie PubMed oder LexisNexis.[15] Die analysierten Dokumente sind unstrukturiert in dem Sinn, dass sie keine einheitliche Datenstruktur aufweisen, man spricht deshalb auch von „freiem Format“.[16] Trotzdem weisen sie jedoch semantische, syntaktische, oft auch typographische und seltener auch markup-spezifische Strukturmerkmale auf, auf die Text-Mining-Techniken zurückgreifen; man spricht deshalb auch von schwachstrukturierten oder halbstrukturierten Textdaten.[17] Meist entstammen die zu analysierenden Dokumente aus einem gewissen Diskursuniversum (domain), das mehr (z. B. Genomanalyse) oder weniger (z. B. Soziologie) stark abgegrenzt sein kann.[18]
Datenaufbereitung
Das eigentliche Text Mining setzt eine computerlinguistische Aufbereitung der Dokumente voraus. Diese basiert typischerweise auf den folgenden, nur zum Teil automatisierbaren Schritten.
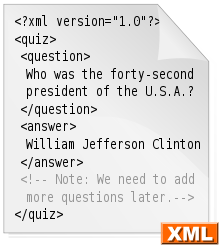 Beispiel einer XML-Syntax
Beispiel einer XML-Syntax
Zunächst werden die Dokumente in ein einheitliches Format – heutzutage zumeist XML – überführt.[19]
Zur Textrepräsentation werden die Dokumente dann zumeist anhand von Schriftzeichen, Wörtern, Begriffen (terms) und/oder so genannten concepts tokenisiert.[20] Dabei steigt bei vorstehenden Einheiten die Stärke der semantischen Bedeutung, aber gleichzeitig auch die Komplexität ihrer Operationalisierung, oft werden deshalb Hybridverfahren zur Tokenisierung angewandt.[21]
In der Folge müssen Worte in den meisten Sprachen lemmatisiert werden, das heißt, auf ihre morphologische Grundform reduziert werden, bei Verben also zum Beispiel der Infinitiv. Dies erfolgt durch Stemming.[22]
Wörterbücher
Zur Lösung einiger Probleme werden digitale Wörterbücher benötigt. Ein Stoppwörterbuch entfernt diejenigen Wörter aus den zu analysierenden Daten, bei denen keine oder kaum Vorhersagekraft erwartet wird, wie dies zum Beispiel oft bei Artikeln wie „der“ oder „eine“ der Fall ist.[23] Um Stoppwörter zu erkennen, werden oft Listen mit den am häufigsten im Textkorpus vorkommenden Wörter erstellt; diese enthalten zumeist neben Stoppwörtern auch die meisten domainspezifischen Ausdrücke, für die normalerweise ebenfalls Wörterbücher erstellt werden.[24] Auch die wichtigen Probleme der Polysemie – die Mehrdeutigkeit von Wörtern – und Synonymie – die Gleichbedeutung verschiedener Worte – werden mittels Wörterbüchern gelöst.[25] (Oft domainspezifische) Thesauri, die das Synonymproblem abschwächen, werden dabei zunehmend in großen Corpora automatisch generiert.[26]
Je nach Analyseart kann es möglich sein, dass Phrasen und Wörter auch durch Part-of-speech Tagging linguistisch klassifiziert werden, häufig ist dies jedoch für Text Mining nicht notwendig.[27]
- Pronomen (er, sie) müssen den vorausgehenden oder folgenden Nominalphrasen (Goethe, die Polizisten), auf die sie verweisen, zugeordnet werden (Anaphernresolution).
- Eigennamen für Personen, Orte, von Firmen, Staaten usw. müssen erkannt werden, da sie eine andere Rolle für die Konstitution der Textbedeutung haben als generische Substantive.
- Mehrdeutigkeit von Wörtern und Phrasen wird dadurch aufgelöst, dass jedem Wort und jeder Phrase genau eine Bedeutung zugeschrieben wird (Bestimmung der Wortbedeutung, Disambiguierung).
- Einige Wörter und Satz(teile) können einem Fachgebiet zugeordnet werden (Termextraktion).
Um die Semantik der analysierten Textdaten besser bestimmen zu können, wird meist auch auf themenspezifisches Wissen zurückgegriffen.[18]
Analyseverfahren
Auf der Grundlage dieser partiell strukturierten Daten können die eigentlichen Text-Mining-Verfahren aufbauen, die vor allem auf der Entdeckung von Kookkurrenzen, idealiter zwischen concepts, basieren.[28] Diese Verfahren sollen:
- In Texten implizit vorhandene Informationen explizit machen
- Beziehungen zwischen Informationen, die in verschiedenen Texten repräsentiert sind, sichtbar machen.
Kernoperationen der meisten Verfahren sind dabei die Identifizierung von (bedingten) Verteilungen, häufige Mengen und Abhängigkeiten.[29] Eine große Rolle bei der Entwicklung solcher Verfahren spielt maschinelles Lernen, sowohl in seiner überwachten als auch in seiner unüberwachten Variante.
Clusterverfahren
Neben den traditionell am weitesten verbreiteten Clusteranalyseverfahren – k-means und hierarchischen Clustern – werden bei Clusterverfahren auch selbstorganisierende Karten verwendet. Außerdem greifen mehr und mehr Verfahren auf Fuzzylogik zurück.
k-means Cluster
Sehr häufig werden beim Text Mining k-means Cluster gebildet.[30] Der zu diesen Clustern gehörende Algorithmus zielt darauf ab, die Summe der euklidischen Distanzen innerhalb und über alle Cluster zu minimieren.[31] Hauptproblem ist dabei, die Anzahl der zu findenden Cluster zu bestimmen, ein Parameter, der durch den Analysten mit Hilfe seines Vorwissens festgelegt werden muss.[32] Derartige Algorithmen sind sehr effizient,[32] allerdings kann es vorkommen, dass nur lokale Optima gefunden werden.[33]
Hierarchische Cluster
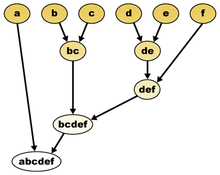 Schema des Aufbaus hierarchischer Cluster
Schema des Aufbaus hierarchischer ClusterBei der ebenfalls populären hierarchischen Clusteranalyse werden Dokumente in einem hierarchischen Clusterbaum (siehe Abbildung) ihrer Ähnlichkeit nach gruppiert.[34] Dieses Verfahren ist deutlich rechenaufwändiger als das für k-means Cluster.[34] Theoretisch kann man dabei so vorgehen, dass man die Dokumentenmenge in sukzessiven Schritten teilt oder indem man jedes Dokument zunächst als einen eigenen Cluster auffasst und die ähnlichsten Cluster in der Folge schrittweise aggregiert.[35] In der Praxis führt aber meist nur letzteres Vorgehen zu sinnvollen Ergebnissen.[35] Neben den Runtimeproblemen ist eine weitere Schwäche die Tatsache, dass man für gute Ergebnisse bereits Hintergrundwissen über die zu erwartende Clusterstruktur benötigt.[35] Wie auch bei allen anderen Methoden des Clustering muss letztendlich der menschliche Analyst entscheiden, ob die gefundenen Cluster Sinnstrukturen widerspiegeln.[36]
Selbstorganisierende Karten
Der 1982 von Teuvo Kohonen erstmal entwickelte Ansatz der selbstorganisierenden Karten ist ein weiteres weit verbreitetes Konzept zur Clusterbildung im Text Mining.[37] Dabei werden (in der Regel zweidimensionale) künstliche neuronale Netze angelegt. Diese verfügen über eine Eingabeebene, in der jedes zu klassifizierende Textdokument als multidimensionaler Vektor repräsentiert ist und dem ein Neuron als Zentrum zugeteilt wird, und über eine Ausgabeebene, in der die Neuronen gemäß der Reihenfolge des gewählten Distanzmaßes aktiviert werden.[37]
Fuzzy Clustering
Immer häufiger werden auch auf Fuzzylogik basierende Cluster verwendet, da viele – insbesondere deiktische – Sprachentitäten nur vom menschlichen Leser adäquat decodiert werden können und so eine inherente Unsicherheit bei der computeralgorhitmischen Verarbeitung entsteht.[38] Da sie dieser Tatsache Rechnung tragen, bieten Fuzzy Cluster so in der Regel überdurchschnittlich gute Ergebnisse.[39] Typischerweise wird dabei auf Fuzzy C-Means zurückgegriffen.[40] Andere Anwendungen dieser Art greifen auf Koreferenzcluster-Graphen zurück.[41]
Vektorenverfahren
Eine große Zahl von Text-Mining-Verfahren ist vektorenbasiert. Typischerweise werden dabei die in den untersuchten Dokumenten vorkommenden terms in einer zweidimensionalen Matrix Atd repräsentiert, wobei t durch die Anzahl der terms und d durch die Anzahl der Dokumente definiert ist. Der Wert des Elements aij wird dabei durch die Häufigkeit des terms i im Dokument j bestimmt, oft wird die Häufigkeitszahl dabei transformiert,[42] meist, indem die in den Matrizenspalten stehenden Vektoren normiert werden, in dem sie durch ihren Betrag dividiert werden.[43] Der so entstandene hochdimensionale Vektorraum wird in der Folge auf einen deutlich Niederdimensionaleren abgebildet. Dabei spielt seit 1990 zunehmend die Latent Semantic Analysis (LSA) eine bedeutende Rolle, die traditionell auf Singulärwertzerlegung zurückgreift.[44] Probablistic Latent Semantic Analysis (PLSA) ist dabei ein mehr statistisch formalisierter Ansatz, der auf der Latent Class Analysis basiert und zur Schätzung der Latenzklassenwahrscheinlichkeiten einen EM-Algorithmus verwendet.[45]
Algorithmen, die auf LSA aufbauen sind allerdings sehr rechenintensiv: Ein normaler Desktop-Computer des Jahrgangs 2004 kann so kaum mehr als einige hunderttausend Dokumente analysieren.[46] Geringfügig schlechtere, aber weniger rechenaufwändige Ergebnisse als LSA erzielen auf Kovarianzanalysen basierende Vektorraumverfahren.[46]
Die Auswertung von Beziehungen zwischen Dokumenten durch solcherartig reduzierte Matrizen ermöglicht es, Dokumente zu ermitteln, die sich auf denselben Sachverhalt beziehen, obwohl ihr Wortlaut verschieden ist. Auswertung von Beziehungen zwischen Termen in dieser Matrix ermöglicht es, assoziative Beziehungen zwischen Termen herzustellen, die oftmals semantischen Beziehungen entsprechen und in einer Ontologie repräsentiert werden können.
Ergebnispräsentation
Einen ungewöhnlich wichtigen und komplexen Teil des Text Mining nimmt die Präsentation der Ergebnisse ein.[47] Darunter fallen sowohl Werkzeuge zum Browsing als auch zur Visualisierung der Ergebnisse.[47] Oft werden die Ergebnisse dabei auf zweidimensionalen Karten präsentiert.
Software
Eine Reihe von Anwendungsprogrammen für Text Mining existieren; oft sind diese auf bestimmte Wissensgebiete spezialisiert. In technischer Hinsicht lassen sich reine Text Miner, Erweiterungen existierender Softwaresuiten – zum Beispiel zum Data-Mining oder zur Inhaltsanalyse – und Programme, nur Teilschritte oder -bereiche des Text Mining begleiten, unterscheiden.[48]
Reine Text Miner
Generische Anwendungen
- Megaputer TextAnalyst
Der von Megaputer entwickelte TextAnalyst ist einer der am meisten verwandten reinen Text Miner. Dieses Programm ist eines der ersten Text-Mining-Programme, das in der sozialwissenschaftlichen Forschung verwandt worden ist.[49]
- Megaputer PolyAnalyst
- Leximancer
Der ab 2000 zunächst an der University of Queensland entwickelte, vektorenbasierte Leximancer greift zur Modellierung seiner Konzeptkarten auf Bayesische Kookkurenz-Abbildungen zurück.[50] Der Algorithmus des Programms basiert auf einem springe force model für das Viele-Körper-Problem. Die Ausgabekarte des Programms visualisiert Worthäufigkeiten durch Helligkeiten, die Verbundenheit der Konzepte mit dem Gesamtkontext durch hierarchisches Erscheinen der Konzepte und die relative Verbundenheit der Konzepte untereinander durch verschieden starke Strahlen.[51] Damit liegt das Programm am oberen Ende der Automatisierungsskala.[52]
- ClearForest Text Analytics Suite
Ein heute nicht mehr weiterentwickelter Text Miner ist IBMs WebFountain.
Domänspezifische Anwendungen
- GeneWays
Das in der Columbia University entwickelte GeneWays deckt zwar auch alle Verfahrensschritte des Text Mining ab, greift aber anders als die ClearForest vertriebenen Programme wesentlich stärker auf domainspezifisches Wissen zurück.[53] Das Programm beschränkt sich dabei thematisch auf die Genforschung und widmet dabei den größten Teil seiner Werkzeuge der Datenaufbereitung und weniger dem eigentlichen Text Mining und der Ergebnispräsentation.[53]
- Patent Researcher
Erweiterungen existierender Softwaresuiten
- Text-Mining-Modul tm für R
- RapidMiner
- NClassifier
- WordStat
Das von Provalis Research angebotene Softwaremodul WordStat ist das einzige Programm für Text Mining, welches sowohl mit einer Statistikanwendung – Simstat – als auch mit einer Software zur Computer-Assistierten Qualitativen Datenanalyse – QDA Miner – verbunden ist. Damit eignet das Programm sich insbesondere zur Triangulation von qualitativen sozialwissenschaftlichen Methoden mit dem quantitative orientierten Text Mining. Das Programm bietet eine Reihe von Clusteralgorithmen – hierarchische Cluster und Multidimensionale Skalierung – sowie eine Visualisierung der Clusterergebnisse an.[54]
- Clementine
SPSS bietet das Modul SPSS Clementine an, das computerlinguistische Methoden zur Informationsextrahierung anbietet, zur Wörterbucherstellung geeignet ist, und Lemmatisierungen für verschiedene Sprachen vornimmt.[54]
- SAS Text Miner
Das SAS Institute bietet zum SAS Enterprise Miner das Zusatzprogramm SAS Text Miner an, welches eine Reihe von Textclusteralgorithmen anbietet.[55]
Teilanbieter
- LingPipe
- HotMiner[56]
Linkanalyse
- Pajek
- UCINET
- NetMiner
Literatur
- Gerhard Heyer, Uwe Quasthof, Thomas Wittig: Text Mining: Wissensrohstoff Text – Konzepte, Algorithmen, Ergebnisse, W3L Verlag, Herdecke / Bochum 2006, ISBN 3-937137-30-0.
- Alexander Mehler, Christian Wolff: Einleitung: Perspektiven und Positionen des Text Mining. In: Zeitschrift für Computerlinguistik und Sprachtechnologie, Band 20, Heft 1, Regensburg 2005, Seite 1–18.
- Alexander Mehler: Textmining. In: Lothar Lemnitzer, Henning Lobin (Hrsg.): Texttechnologie. Perspektiven und Anwendungen. Stauffenburg, Tübingen 2004, ISBN 3-86057-287-3, S. 329–352.
- Jürgen Franke, Gholamreza Nakhaeizadeh, Ingrid Renz (Hrsg.): Text Mining – Theoretical Aspects and Applications. Physica, Berlin 2003.
- Ronen Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data. Cambridge University Press, 2006, ISBN 0-521-83657-3.
- Bastian Buch: Text Mining zur automatischen Wissensextraktion aus unstrukturierten Textdokumenten, VDM, 2008, ISBN 3-8364-9550-3
Weblinks
- Untangling Text Data Mining von Marti A. Hearst, erschienen in den Proceedings of ACL'99: the 37th Annual Meeting of the Association for Computational Linguistics, University of Maryland, June 20-26, 1999
- GSCL-Symposium "Sprachtechnologie und eHumanities" 26.02.2009 - 27.02.2009, Tagungsband (PDF)
- National Centre for Text Mining (NaCTeM) an der University of Manchester
Einzelnachweise
- ↑ Ronen Feldman, Ido Dagan: Knowledge Discovery in Texts. , S. 112-117.
- ↑ Andreas Hotho, Andreas Nürnberger, Gerhard Paaß: A Brief Survey of Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 19-62, S. 22. Abgerufen am 11. November 2011.
- ↑ Alexander Mehler, Christian Wollf: Einleitung: Perspektiven und Positionen des Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 1-18, S 2. Abgerufen am 11. November 2011.
- ↑ Z. B. Alexander Mehler, Christian Wollf: Einleitung: Perspektiven und Positionen des Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 1-18, S. 3. Abgerufen am 11. November 2011.;
Sholom M. Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 85ff, New York, NY: Springer 2005, ISBN 0-387-95433-3 - ↑ z B. John Atkinson: Evolving Explanatory Novel Patterns for Semantically-Based Text Mining. In: Natural Language Processing and Text Mining, S. 145-169, S. 146, London, U.K.: Springer 2007, ISBN 978-1-84628-754-1;
Andreas Hotho, Andreas Nürnberger, Gerhard Paaß: A Brief Survey of Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 19-62, S. 23. Abgerufen am 11. November 2011. - ↑ z B. John Atkinson: Evolving Explanatory Novel Patterns for Semantically-Based Text Mining. In: Natural Language Processing and Text Mining, S. 145-169, S. 146, London, U.K.: Springer 2007, ISBN 978-1-84628-754-1;
Andreas Hotho, Andreas Nürnberger, Gerhard Paaß: A Brief Survey of Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, 23, Nr. 1, 2005, S. 19-62, S. 23. Abgerufen am 11. November 2009. - ↑ Andreas Hotho, Andreas Nürnberger, Gerhard Paaß: A Brief Survey of Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 19-62, S. 23. Abgerufen am 11. November 2009.
- ↑ Max Bramer: Principles of Data Mining, S. 239f, London, U.K.: Springer 2007, ISBN 978-1-84628-765-7
- ↑ Andreas Hotho, Andreas Nürnberger, Gerhard Paaß: A Brief Survey of Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 19-62, S. 23f. Abgerufen am 11. November 2009.
- ↑ Andreas Hotho, Andreas Nürnberger, Gerhard Paaß: A Brief Survey of Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 19-62, S. 24. Abgerufen am 11. November 2009.
- ↑ Andreas Hotho, Andreas Nürnberger, Gerhard Paaß: A Brief Survey of Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 19-62, S. 45ff. Abgerufen am 11. November 2009.
- ↑ z. B. Fabrizio Sebastiani: Machine learning in automated text categorization. (PDF) In: ACM Computing Surveys. 34, Nr. 1, 2002, S. 1–47, S. 2.
- ↑ Anne Kao, Steve Poteet, Jason Wu, William Ferng, Rod Tjoelker, Lesley Quach: Latent Semantic Analysis and Beyond. In: Min Song, Yi-Fang Brooke Wu (Hrsg.): Handbook of Research on Text and Web Mining Technologies, S. 546–570, S. 561, Hershey, PA: Information Science Reference 2009, ISBN 978-1-59904-990-8
- ↑ Alexander Mehler, Christian Wollf: Einleitung: Perspektiven und Positionen des Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 1-18, S 7-9. Abgerufen am 11. November 2009.
- ↑ a b Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 2, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 3, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 3f, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ a b Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 8, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ Sholom M Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 18f, New York, NY: Springer 2005, ISBN 0-387-95433-3
- ↑ Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 6f, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 7, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ Sholom M Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 21ff, New York, NY: Springer 2005, ISBN 0-387-95433-3
- ↑ Sholom M Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 27ff, New York, NY: Springer 2005, ISBN 0-387-95433-3
- ↑ Sholom M Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 27, New York, NY: Springer 2005, ISBN 0-387-95433-3
- ↑ Scott Deerwester, Susan T. Dumais, George W. Furnas, Thomas K. Landauer: Indexing by latent semantic analysis. In: Journal of the American Society for Information Science. 41, Nr. 6, 1990, S. 391-407, S. 391f. doi:10.1002/(SICI)1097-4571(199009)41:6<391::AID-ASI1>3.0.CO;2-9.
- ↑ Pierre Senellart, Vincent D. Blondel: Automatic Discovery of Similar Words. In: Michael W. Berry & Malu Castellanos (ed.) (Hrsg.): Survey of Text Mining II: Clustering, Classification and Retrieval, S. 25-44, London, U.K.: Springer 2008, ISBN 978-0-387-95563-6
- ↑ Sholom M Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 37ff, New York, NY: Springer 2005, ISBN 0-387-95433-3
- ↑ Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 8f, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 19, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ Sholom M. Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 109, New York, NY: Springer 2005, ISBN 0-387-95433-3
- ↑ Sholom M. Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 110, New York, NY: Springer 2005, ISBN 0-387-95433-3
- ↑ a b Sholom M. Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 111, New York, NY: Springer 2005, ISBN 0-387-95433-3
- ↑ Joydeep Ghosh, Alexander Liu: K-Means. In: The Top Ten Algorithms in Data Mining, S. 21-37, S 23f, New York, NY: CRC Press 2005, ISBN 0-387-95433-3
- ↑ a b Sholom M. Weiss, Nitin Indurkhya, Tong Zhang, Fred J. Damerau: Text Mining: Predictive Methods for Analyzing unstructured Information, S. 85ff, New York, NY: Springer 2005, ISBN 0-387-95433-3
- ↑ a b c Andreas Hotho, Andreas Nürnberger, Gerhard Paaß: A Brief Survey of Text Mining. (PDF) In: Zeitschrift für Computerlinguistik und Sprachtechnologie. 20, Nr. 1, 2005, S. 19-62, S. 40f. Abgerufen am 11. November 2009.
- ↑ Roger Bilisoly: Practical Text Mining with Perl, S. 235, Hoboken, NY: John Wiley & Sons 2008, ISBN 978-0-470-17643-6
- ↑ a b Abdelmalek Amine, Zakaria Elberrichi, Michel Simonet, Ladjel Bellatreche, Mimoun Malki: SOM-Based Clustering of Textual Documents Using WordNet. In: Handbook of Research on Text and Web Mining Technologies, S. 189–200, S. 195, Hershey, PA: Information Science Reference 2009, ISBN 978-1-59904-990-8
- ↑ René Witte, Sabine Bergler: Fuzzy Clustering for Topic Analysis and Summarization of Document Collections. In: Advances in Artificial Intelligence. 4509, 2007, S. 476-488, S. 478. doi:10.1007/978-3-540-72665-4_41.
- ↑ Hichem Frigui, Olfa Nasraoui: Simultaneous Clustering and Dynamic Keyword Weighting for Text Documents. In: Survey of Text Mining: Clustering, Classification and Retrieval, S. 45-72, S. 53, New York, NY: Springer 2004, ISBN 978-0-387-95563-6.
René Witte, Sabine Bergler: Fuzzy Clustering for Topic Analysis and Summarization of Document Collections. In: Advances in Artificial Intelligence. 4509, 2007, S. 476-488, S. 486. doi:10.1007/978-3-540-72665-4_41. - ↑ Hichem Frigui, Olfa Nasraoui: Simultaneous Clustering and Dynamic Keyword Weighting for Text Documents. In: Survey of Text Mining: Clustering, Classification and Retrieval, S. 45-72, S. 65, New York, NY: Springer 2004, ISBN 978-0-387-95563-6
- ↑ René Witte, Sabine Bergler: Fuzzy Clustering for Topic Analysis and Summarization of Document Collections. In: Advances in Artificial Intelligence. 4509, 2007, S. 476-488, S. 480. doi:10.1007/978-3-540-72665-4_41.
- ↑ Anne Kao, Steve Poteet, Jason Wu, William Ferng, Rod Tjoelker, Lesley Quach: Latent Semantic Analysis and Beyond. In: Min Song, Yi-Fang Brooke Wu (Hrsg.): Handbook of Research on Text and Web Mining Technologies, S. 546–570, S. 547, Hershey, PA: Information Science Reference 2009, ISBN 978-1-59904-990-8
- ↑ Max Bramer: Principles of Data Mining, S. 245, London, U.K.: Springer 2007, ISBN 978-1-84628-765-7
- ↑ Anne Kao, Steve Poteet, Jason Wu, William Ferng, Rod Tjoelker, Lesley Quach: Latent Semantic Analysis and Beyond. In: Min Song, Yi-Fang Brooke Wu (Hrsg.): Handbook of Research on Text and Web Mining Technologies, S. 546–570, S. 551, Hershey, PA: Information Science Reference 2009, ISBN 978-1-59904-990-8
- ↑ Anne Kao, Steve Poteet, Jason Wu, William Ferng, Rod Tjoelker, Lesley Quach: Latent Semantic Analysis and Beyond. In: Min Song, Yi-Fang Brooke Wu (Hrsg.): Handbook of Research on Text and Web Mining Technologies, S. 546-570, S. 555, Hershey, PA: Information Science Reference 2009, ISBN 978-1-59904-990-8
- ↑ a b Mei Kobayashi, Masaki Aono: Vector Space Models for Search and Cluster Mining. In: Michael W. Berry (Hrsg.): Survey of Text Mining: Clustering, Classification and Retrieval, S. 103-122, S. 108f, New York, NY: Springer 2004, ISBN 978-0-387-95563-6
- ↑ a b Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 10, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ Alessandro Zanasi: Text Mining Tools. In: Alessandro Zanasi (ed.) (Hrsg.): Text Mining and its Applications to Intelligence, CRM and Knowledge Management, S. 315-327, S. 315, Southampton & Billerica, MA: WIT Press 2005, ISBN 978-1-84564-131-3
- ↑ Josh Adams, Vincent J. Roscigno: White Supremacists, Oppositional Culture and the World Wide Web. In: Social Forces. 84, Nr. 2, 2005, S. 759-778, S 765.
- ↑ Nigel J Martin, John L Rice: Profiling Enterprise Risks in Large Computer Companies Using the Leximancer Software Tool. In: Risk Management. 9, Nr. 3, 2007, S. 188–206, S. 191. doi:10.1057/palgrave.rm.8250030.
- ↑ Andrew E. Smith, Michael S. Humphreys: Evaluation of unsupervised semantic mapping of natural language with Leximancer concept mapping. In: Behavior Research Methods. 38, Nr. 2, 2006, S. 262-279, S. 264.
- ↑ Boris Kabanoff, Shane Brown: Knowledge structures of prospectors, analyzers, and defenders: content, structure, stability, and performance. In: Strategic Management Journal. 29, Nr. 2, 2008, S. 149-171, S. 154. doi:10.1002/smj.644.
- ↑ a b Ronan Feldman, James Sanger: The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data, S. 307f, New York, NY: Cambridge University Press 2007, ISBN 978-0-511-33507-5
- ↑ a b Richard Segall, Qingyu Zhang: A Survey of Selected Software Technologies for Text Mining. In: Min Song, Yi-fang Brooke Wu (Hrsg.) (Hrsg.): Handbook of Research on Text and Web Mining Technologies, S. 766–784, S. 778, Hershey, PA: Information Science Reference 2009, ISBN 978-1-59904-990-8
- ↑ Richard Segall, Qingyu Zhang: A Survey of Selected Software Technologies for Text Mining. In: Min Song, Yi-fang Brooke Wu (Hrsg.) (Hrsg.): Handbook of Research on Text and Web Mining Technologies, S. 766–784, S. 771, Hershey, PA: Information Science Reference 2009, ISBN 978-1-59904-990-8
- ↑ wrg.upf.edu (PDF)

Wikimedia Foundation.