- Sortierte Nachbarschaft
-
Sortierte Nachbarschaft (engl. sorted neighborhood) ist ein Verfahren zur Duplikaterkennung. Kernidee ist eine Sortierung der Datensätze, in denen Duplikate gefunden werden sollen, so dass potentielle Duplikate möglichst nahe beieinander liegen und deshalb nur nahe beieinander liegende Datensätze in einer Nachbarschaft miteinander verglichen werden müssen. Als Ergebnis des Verfahrens erhält man Gruppen (cluster) vermutlicher Duplikate.
Inhaltsverzeichnis
Verfahren
Die zu überprüfenden Datensätze seien in einer Tabelle mit mehreren Attributen gegeben. Sortierte Nachbarschaft arbeitet dreiphasig:
Schlüsselerzeugung
Ein Schlüssel ist eine Zeichenkette, die aus (Teilen von) relevanten Attributen gebildet wird. Die Effektivität des Algorithmus ist maßgeblich von einer geschickten Wahl des Schlüssels abhängig. Der Schlüssel ist lediglich ein virtueller und im Gegensatz zu einem Hash-Wert nicht eindeutig. Er wird ausschließlich zur Sortierung der Tupel benutzt.
Sortierung- die Sortierung der Tupel erfolgt lexikografisch nach dem erzeugten Schlüssel
- Ziel der Sortierung ist es, dass sich Tupel, die voneinander Duplikate darstellen, möglichst nah aneinander gruppieren
- der Sortieralgorithmus kann nach Belieben gewählt werden (z. B. Merge- oder Alpha-Sort für Sekundärspeicher)
Verschmelzung
- ein Fenster von festgelegter Größe
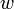 wird zeilenweise über die sortierten Tupel geschoben (sliding window)
wird zeilenweise über die sortierten Tupel geschoben (sliding window) - sei die Anzahl der Tupel
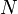 , dann gilt für die Größe des Fensters
, dann gilt für die Größe des Fensters 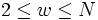
- der Schlüssel diente nur zur Sortierung der Tupel, um Duplikate zu finden, werden die Attribute der Tupel innerhalb des Fensters paarweise verglichen
- für den Vergleich der einzelnen Attribute der Tupelpaare werden komplexe Regeln eingesetzt, die festlegen, wann zwei Tupel Duplikate sind (hierzu erfolgen neben der Levenshtein-Distanz auch andere Vergleiche wie z. B. die der Länge von Zeichenketten oder die von numerischen Werten)
Aufwand
Sei
die Anzahl der Tupel und die Zeilengröße des Fensters, dann beträgt der Aufwand 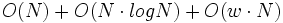 entsprechend den 3 Phasen Schlüsselgenerierung, Sortieren und Verschmelzen. Ist
entsprechend den 3 Phasen Schlüsselgenerierung, Sortieren und Verschmelzen. Ist 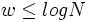 dann ist die Gesamtkomplexität
dann ist die Gesamtkomplexität 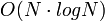 , wenn nicht, ist sie
, wenn nicht, ist sie 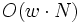 , was bei einer Fenstergröße von N (d. h. damit maximale Duplikate gefunden werden) zu
, was bei einer Fenstergröße von N (d. h. damit maximale Duplikate gefunden werden) zu 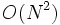 wird.
wird.Verbesserung
Eine Verbesserung ist es, über die gefundenen Duplikate eine transitive Hülle zu bilden. Dies erlaubt, die Fenstergröße
und damit die Zahl der notwendigen Vergleiche zu reduzieren. Sei mit 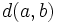 bezeichnet, dass
bezeichnet, dass 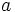 und
und 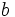 Duplikate sind, dann lässt sich aus , mit
Duplikate sind, dann lässt sich aus , mit 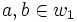 , und
, und 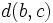 , mit
, mit 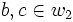 , ableiten dass
, ableiten dass 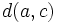 , auch wenn es kein Fenster gibt, in dem und
, auch wenn es kein Fenster gibt, in dem und 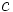 gemeinsam sind.
gemeinsam sind.Multipass-Technik
Abhängig von der Schlüsselwahl kann es sein, dass Duplikate sehr weit auseinander liegen. Die triviale Möglichkeit wäre, das Fenster zu vergrößern. Dadurch steigt allerdings der Vergleichsaufwand enorm an.
Eine bessere Möglichkeit ist das Multipass-Verfahren. Hierbei wird mehrmals ein Sortierte Nachbarschaft ausgeführt, mit verschiedenen Schlüsseln und relativ kleinem
. Anschließend wird die transitive Hülle über alle Ergebnisse gebildet.Elaborierte Sortierte Nachbarschaft nach Monge und Elkan
Das Verfahren in Stichpunkten:
- um Domänenunabhängigkeit zu erreichen, werden Tupel als Zeichenketten interpretiert; das Verfahren wird dann zweimal ausgeführt, einmal wird das Tupel vorwärts als Zeichenkette interpretiert und einmal rückwärts
- es werden Gruppen von Duplikaten gebildet, die jeweils durch einen Repräsentanten vertreten werden und mit ausschließlich diesen finden fürderhin Vergleiche statt
- es wird mit einer Graphenstruktur gearbeitet, die folgendes umfasst:
- einen Knoten pro Tupel
- eine Kante von Tupel x nach Tupel y, wenn die Tupel x und y Duplikate sind
- vernetzte Duplikate bilden einen Graphen, hier Zusammenhangskomponenten genannt
- es gibt zwei Operationen auf dem Graphen:
Union(x,y)verbindet die beiden Tupel x und y und damit auch die beiden Zusammenhangskomponenten, die x und y enthalten, zu einer neueren, größeren Zusammenhangskomponente (die alten einzelnen werden nicht gespeichert) und es wird ein Repräsentant für diese Zusammenhangskomponente gewähltFind(x)gibt den Repräsentanten für die Zusammenhangskomponente zurück, die das Tupel x enthält
- der Algorithmus benutzt eine Vorrangwarteschlange (priority queue); diese enthält mehrere Mengen, die jeweils aus einem oder mehreren Tupeln aus einer einzigen Gruppe von (Duplikat-)Tupeln stammen; jede dieser Mengen enthält also die Tupel, die eine Gruppe von (Duplikat-)Tupeln repräsentieren
- die Tupel werden sequentiell eingelesen und für jedes wird überprüft, ob es bereits Mitglied einer der Gruppen ist, die in der Vorrangwarteschlange repräsentiert werden (mittels
Find(Tupel)); wenn ja, wird das nächste Tupel eingelesen, wenn nein, dann wird es mit den Repräsentanten der Gruppen in der Vorrangwarteschlange verglichen; wird es als Duplikat erkannt, dann wird einUnion(Tupel,Repräsentant)ausgeführt und damit die Zusammenhangskomponenten verbunden, wenn nicht, dann wird das Tupel als eine Einermenge in der Vorrangwarteschlange abgespeichert - die Menge in der Vorrangwarteschlange, die diejenige Gruppe repräsentiert, die das zuletzt gefundene Gruppenmitglied enthält, hat die höchste Priorität, im Weiteren absteigend
- da die Tupel vorher sortiert wurden, werden Tupel, die zur gleichen Gruppe gehören, i. A. nacheinander gefunden, weshalb eine geringe Zahl (z. B. 4) von Mengen in der Vorrangwarteschlange ausreichen
Literatur
- Alvaro Monge, Charles Elkan: An Efficient Domain-Independent Algorithm for Detecting Approximately Duplicate Database Records. In: Proceedings of the Workshop on Research Issues on Data Mining and Knowledge Discovery. 1997
Wikimedia Foundation.