- Binärer Suchbaum
-
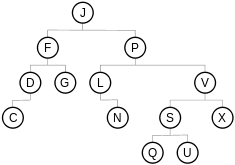 Binärer Suchbaum der Höhe 5 mit 13 Knoten: Wurzel J und Blättern C, G, N, Q, U und X
Binärer Suchbaum der Höhe 5 mit 13 Knoten: Wurzel J und Blättern C, G, N, Q, U und X
In der Informatik ist ein binärer Suchbaum eine spezielle Implementierung der abstrakten Datenstruktur Suchbaum. Ein binärer Suchbaum, häufig abgekürzt als BST (von englisch Binary Search Tree), ist ein binärer Baum, bei dem die Knoten des linken Teilbaums eines Knotens nur kleinere (oder gleiche) Schlüssel und die Knoten des rechten Teilbaums eines Knotens nur größere (oder gleiche) Schlüssel als der Knoten selbst besitzen.
Die Bedeutung der Begriffe „kleiner gleich“ und „größer gleich“ ist völlig dem Anwender überlassen. Sie müssen nur eine Totalordnung (genauer: eine totale Quasiordnung s. u.) darstellen – zumeist realisiert durch eine vom Anwender zur Verfügung zu stellende 3-Wege-Vergleichsfunktion. Auch ob es sich um einziges Schlüsselfeld oder eine Kombination von Feldern handelt, ist Sache des Anwenders; ferner ob Duplikate (unterschiedliche Elemente, die beim Vergleich aber nicht als „ungleich“ herauskommen) akzeptabel sein sollen oder nicht. Über die Erweiterung der Suchfunktion in diesem Fall siehe unten.
Ein in-order-Durchlauf durch einen binären Suchbaum ist äquivalent zum Wandern durch eine sortierte Liste (bei im Wesentlichen gleichem Laufzeitverhalten). Mit anderen Worten: ein binärer Suchbaum bietet unter Umständen wesentlich mehr Funktionalität (z. B. Durchlauf in der Gegenrichtung und/oder einen „direkten Zugriff“ mit ggf. logarithmischem Laufzeitverhalten) bei nur unwesentlich höherem Speicherbedarf.
Inhaltsverzeichnis
Begriffsklärung
Zur Beachtung:
- Der Begriff „Nachbar“ (und „Nachbarschaft“ etc.) wird in diesem Artikel (und bei den Suchbäumen generell) anders als sonst in der Graphentheorie verwendet, nämlich ausschließlich im Sinn der eingeprägten Ordnungsrelation: „rechter“ Nachbar meint den nächsten Knoten in aufsteigender Richtung, „linker“ in absteigender.
- Muss in diesem Artikel auf die Hierarchiestruktur des Baumes eingegangen werden, so werden Begriffe wie „Vater“ oder „Vorfahr“ und „Vorgänger“ bzw. „Kind“ oder „Nachfahr“ und „Nachfolger“ verwendet.
- Die hierarchische Anordnung der Knoten in der Baumstruktur des binären Suchbaums wird als sekundär und mehr oder minder zufällig angesehen – ganz im Vordergrund steht die korrekte Darstellung der Reihenfolge.
- Ähnlich sekundär ist die Frage, welcher Knoten gerade die Rolle der Wurzel spielt, insbesondere wenn es sich um einen selbst-balancierenden Baum handelt. Insofern eignet die Adresse der Wurzel sich nicht zur Identifizierung des Baumes.
- Dagegen kann die feste Adresse eines Zeigers zur Wurzel als Identifikation genommen werden, der dann aber auch von den Operationen des Baums zu pflegen ist.
Ordnungsrelation
Damit binäres Suchen, Sortieren etc. funktionieren, muss die Ordnungsrelation eine totale Quasiordnung, im Englischen „total preorder“, sein. Die Bezeichnungen für die induzierte Duplikatrelation ∼ und die induzierte strenge Halbordnung
 seien wie dort.
seien wie dort.Die Trichotomie der zugehörigen 3-Wege-Vergleichsfunktion
 – von ihrem Ergebnis ist nur das Vorzeichen
– von ihrem Ergebnis ist nur das Vorzeichen  relevant – ergibt sich folgendermaßen:
relevant – ergibt sich folgendermaßen:Nach Vertauschung von x und y und einer Umordnung erkennt man, dass
 .
.
Die induzierte Ordnungsrelation
ist eine strenge schwache Ordnung, im Englischen „strict weak ordering“. Sie induziert auf den Äquivalenzklassen dieser Relation, genauer: den Äquivalenzklassen der Duplikatrelation, eine strenge Totalordnung.Offensichtlich lässt sich jede solche Ordnung spiegeln, d. h. + 1 mit − 1 vertauschen, das Ergebnis ist wieder eine strenge schwache Ordnung. Nachbarschaftsbeziehungen bleiben bestehen, es wird nur „größer“ mit „kleiner“ bzw. „rechts“ mit „links“ vertauscht.
Anmerkungen:
- Zum reinen Aufsuchen genügt im Grunde eine 2-Wege-Vergleichsfunktion, die angibt, ob zwei „Schlüssel“ gleich sind oder nicht. Mit einer solchen Vergleichsfunktion sind aber effiziente, z. B. im Mittel logarithmische, Suchzeiten nicht erreichbar.
- Für das Funktionieren des Sortierens und binären Suchens ist es unerheblich, ob das Aufspalten des Ungleich-Weges einer 2-Wege-Vergleichsfunktion in einen Kleiner- und einen Größer-Weg ein Artefakt ist, wie z. B. die Anordnung der Buchstaben in einem Alphabet, oder ob eine Näher-/Ferner- oder logische Beziehung (mit) im Spiel ist.
- Spiegelt die Ordnungsrelation auch Nachbarschaft wider, kann diese für ein effizientes „unscharfes Suchen“ ausgenutzt werden.
- Die Binarität der Binärbäume passt exakt zur Suche mit der 3-Wege-Vergleichsfunktion.
- Wie im folgenden Abschnitt „Suchen“ näher ausgeführt, ist die Behandlung von Duplikaten unabhängig davon, ob die Ordnungsrelation Duplikate zulässt (totale Quasiordnung bzw. strenge schwache Ordnung) oder nicht (Totalordnung bzw. strenge Totalordnung). Einerseits kann es unerwünscht sein, auch wenn sie Duplikate zulässt, diese im Baum zu haben. Andererseits kann es durchaus angebracht sein, auch bei einer Totalordnung Duplikate in den Baum aufzunehmen, z. B. aus dem Eingabestrom. Es kommt in der praktischen Anwendung also nur darauf an, ob es im Baum Duplikate geben soll oder nicht. Konsequenterweise wird hier von vorn herein von totalen Quasiordnungen ausgegangen.
Suchen
Die Suche nach einem Eintrag verläuft derart, dass der Suchschlüssel zunächst mit dem Schlüssel der Wurzel verglichen wird. Sind beide gleich, so ist der Eintrag (oder ein Duplikat) gefunden.
Andernfalls (bei „ungleich“) wird überprüft, ob der Suchschlüssel kleiner (größer) ist als der Schlüssel im Knoten: dann wird die Suche rekursiv im linken (rechten) Teilbaum der Wurzel fortgeführt; gibt es keinen linken (rechten) Teilbaum, so existiert der gesuchte Eintrag im binären Suchbaum nicht.
Der auf diese Weise erhaltene finale „ungleich“-Knoten stellt zusammen mit der letzten Vergleichsrichtung den sog. Einfügepunkt für das gesuchte Element dar. Wird es hier eingefügt, dann stimmt die in-order- mit der Sortier-Reihenfolge überein. Der finale „ungleich“-Knoten hat einen Schlüssel, der entweder der kleinste unter den größeren ist oder der größte unter den kleineren. Dasselbe gilt spiegelbildlich für seinen Nachbarknoten in der letzten Vergleichsrichtung, sofern es einen solchen gibt. (Allerdings ist dieser kein „Einfügepunkt“, sondern ein Vorfahr desselben.)
Suchen duplikatfrei
Der folgende Pseudocode Find illustriert die Arbeitsweise des Algorithmus für eine Suche, bei der in keinem Fall Duplikate in den Baum aufgenommen werden sollen. (Das ist letztlich unabhängig davon, ob die Ordnungsrelation Duplikate zulässt oder nicht.)
Die Funktion gibt einen Knoten und ein Vergleichsergebnis zurück. Dieses Paar stellt – außer beim Vergleichsergebnis „Equal“ – einen Einfügepunkt dar.
Find(t, s) { t: binärerSuchbaum s: Suchschlüssel return Find0(t, s, t.root, Empty) // zurück kommt ein Knoten und ein VergleichsergebnisFind0(t, s, x, d) t: Teilbaum s: Suchschlüssel x: Knoten d: Vergleichsergebnis (Equal, LessThan, GreaterThan oder Empty) if x ≠ null then { if s = x.key then return (x, Equal) // Suchschlüssel s gefunden if s < x.key then return Find0(x, s, x.left, LessThan) else return Find0(x, s, x.right, GreaterThan) } return (t, d) // Suchschlüssel s nicht gefunden // zurück kommt (Baum,Empty) oder (Knoten,Vergleichsergebnis) }Bei dem in der Abbildung gewählten Beispiel gibt Find beim Suchschlüssel s den ersten Treffer „F“ als Ergebnis zurück.
Suchen mit Duplikaten
Sollen Einträge von Duplikaten in den Baum zugelassen sein, ist es vorteilhaft, die Suche nicht beim ersten besten gefundenen Knoten abzubrechen, sondern entweder auf der kleineren oder auf der größeren Seite bis zu den Blättern weiter zu suchen. Dies unterstützt eine gezielte Einfügung von Duplikaten und ist insbesondere dann interessant, wenn im Suchbaum nicht nur gesucht und gefunden werden soll, sondern u. U. auch traversiert wird. Der Einsatz der nachfolgenden Suchfunktionen beim Sortierverfahren Binarytreesort macht dieses Verfahren zu einem „stabilen“ (s. Stabilität (Sortierverfahren) mit erklärenden Beispielen).
Beim folgenden Pseudocode FindDupGE gibt der Benutzer die Richtung rechts vor, auf welcher Seite der Duplikate ein ggf. neues eingefügt werden soll.
FindDupGE(t, s, c) { t: binärerSuchbaum s: Suchschlüssel // FindDupGE: falls s ein Duplikat ist, // soll es rechts eingefügt werden. c: Cursor { // Dieser Cursor enthält am Ende: c.d: Richtung // (1) Left, Right oder Empty c.n: Knoten // (2) Knoten oder Baum (nur bei Empty) } c.n = t // Für den leeren Baum return FindDupGE0(t.root, s, c, Empty) // zurück kommt ein Einfügepunkt im Cursor c }FindDupGE0(x, s, c, d) { x: Knoten s: Suchschlüssel c: Cursor d: Richtung if x ≠ null then { c.n = x if s ≥ x.key // Suchschlüssel s ≥ Knoten.Schlüssel ? then return FindDupGE0(x.right, s, c, Right) // ≥ (GE) else return FindDupGE0(x.left, s, c, Left) // < } c.d = d // Setzen Einfüge-Richtung return c // zurück kommt ein Einfügepunkt im Cursor c }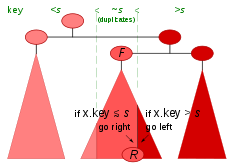 Einfügepunkt beim rechtesten Duplikat von s
Einfügepunkt beim rechtesten Duplikat von sDas Paar (Knoten, Richtung) des vorigen Beispiels Find ist hier zu dem einen Objekt, genannt Cursor, zusammengefasst. Es ist ein reiner Ausgabeparameter, der den Einfügepunkt spezifiziert.
FindDupGE ist so gehalten, dass im Ergebnis-Cursor immer ein unmittelbarer Einfügepunkt geliefert wird. Aus dem Ergebnis ist aber nicht ohne Weiteres erkennbar, ob es sich um ein Duplikat handelt, da der Einfügepunkt nicht den gesuchten Schlüssel haben muss, selbst wenn dieser im Baum vorkommt. Dies hängt von der mehr oder minder zufälligen Anordnung der Knoten im Baum ab. Ist nämlich das rechteste Duplikat (im Beispiel der Abbildung „R“) ein rechtes Halbblatt, dann stellt es zusammen mit der Richtung „rechts“ den Einfügepunkt dar; ist es das nicht, dann ist es in der Struktur des Binärbaums ein Vorfahr des rechten Nachbarn von „R“, der nun ein linkes Halbblatt ist und zusammen mit der Richtung „links“ denselben Einfügepunkt spezifiziert und also in diesem Fall das Resultat von FindDupGE darstellt.
Während bei Find alle 3 Wege der Vergleichsfunktion abgefragt werden, begnügt sich FindDupGE mit der Abfrage von deren 2.
Der nachfolgende Pseudocode FindDup kombiniert die Fähigkeiten von Find und FindDupGE, indem er sowohl ein Ergebnis über das Vorhandensein eines Suchschlüssels als auch einen Einfügepunkt für Duplikate liefert. Hierzu gibt der Benutzer eine Richtung d (links oder rechts) vor, auf welcher Seite der Duplikate ein ggf. neues eingefügt werden soll. Als Ergebnis kommt ein Paar (Knoten, Cursor) zurück, wobei Knoten angibt, ob und wo der Suchschlüssel gefunden wurde.Der Vorschlag baut beispielhaft ein Objekt auf, hier Cursor genannt, welches den ganzen Pfad vom Ergebnisknoten bis zur Wurzel enthält. Damit passt er zur nachfolgenden in-order-Traversierfunktion Next, die ohne Zeiger zum Vaterknoten auskommen möchte. Die passende Datenstruktur für den Pfad ist der Stapelspeicher, engl. Stack, mit den Operationen push und pop. Die Überlaufbedingung bei push wird im vorliegenden Vorschlag nicht explizit behandelt; aber es könnte ohnehin nur mit abnormalen Ende reagiert werden, was die push-Funktion alleine genauso gut kann. Bei höhen-balancierten Bäumen ist der Speicherbedarf für den Stack logarithmisch in der Zahl der Knoten und damit recht überschaubar (vorgerechnetes Beispiel AVL-Baum).
Der etwas einfacheren Version der Funktion, bei der ein Zeiger zum Vater in jedem Knoten vorausgesetzt wird und deshalb der Cursor ohne Stack auskommt, fehlen einfach die push- und clear-Aufrufe. Der Speicherbedarf für den Baum erhöht sich allerdings um einen festen Prozentsatz.
FindDup(t, s, c, d) { t: binärerSuchbaum s: Suchschlüssel c: Cursor { // Dieser Cursor enthält am Ende: c.d: Richtung // (1) Left, Right oder Empty c.n: Knoten // (2) Knoten oder Baum (nur bei Empty) c.t: Baum // (3) Baum (enthält den Zeiger zur Wurzel) c.p: Pfad // (4) Pfad vom Vater des Knotens zur Wurzel } d: Richtung // Falls s ein Duplikat ist, soll es ... c.d = d // ... auf dieser Seite eingefügt werden. c.t = t // initialisiere den Cursor clear(c.p) // initialisiere den Stack c.n = t // für den leeren Baum return FindDup0(t.root, s, c, Empty) // zurück kommt ein Knoten und ein Einfügepunkt im Cursor c }FindDup0(x, s, c, d) { x: Knoten s: Suchschlüssel c: Cursor d: Richtung if x ≠ null then { push(c.p, c.n) // Vater von x in den Stack c.n = x // setze neuen Knoten im Cursor if s = x.key then return FindDup1(x, s, c, c.d) if s < x.key then return FindDup0(x.left, s, c, Left) else return FindDup0(x.right, s, c, Right) } c.d = d // Setzen Einfüge-Richtung return (null, c) // Suchschlüssel s nicht gefunden // zurück kommt null und ein Einfügepunkt im Cursor c }FindDup1(q, s, c, d) { q: Knoten // letzter Knoten mit Equal s: Suchschlüssel c: Cursor d: Richtung x: Knoten x = c.n.child[d] if x ≠ null then { push(c.p, c.n) // Vater von x in den Stack c.n = x // setze neuen Knoten im Cursor if s = x.key then return FindDup1(x, s, c, c.d) // x ist neuer Knoten mit Equal else return FindDup1(q, s, c, 1 - c.d) // bei ≠ weiter in der Gegen-Richtung } c.d = d // Setzen Einfüge-Richtung return (q, c) // zurück kommt ein Duplikat und ein Einfügepunkt im Cursor c }FindDup ist so gehalten, dass im Ergebnis-Cursor immer ein unmittelbarer Einfügepunkt geliefert wird. Wenn der Suchschlüssel nicht gefunden wurde, wird im Feld Knoten der Nullzeiger zurückgegeben. Wenn der Suchschlüssel gefunden wurde, gibt FindDup das linkeste oder rechteste Duplikat, im Beispiel der Abbildung das rechteste Duplikat „R“, als gefundenen Knoten zurück. Der Einfügepunkt kann mit dem gefundenen Knoten zusammenfallen; er kann aber auch sein unmittelbarer (im Beispiel der Abbildung rechter) Nachbar sein, in welchem Fall er einen anderen Schlüssel hat.
Im ersten Teil, FindDup0, werden alle 3 Wege der Vergleichsfunktion abgefragt; im zweiten Teil, FindDup1, wenn das Vorhandensein des Suchschlüssels positiv geklärt ist, nur noch deren 2.
Komplexität
Da die Suchoperation entlang eines Weges von der Wurzel zu einem Blatt verläuft, hängt die aufgewendete Zeit im Mittel und im schlechtesten Fall linear von der Höhe h des Suchbaums ab (Komplexität O(h)); im asymptotisch vernachlässigbaren besten Fall ist die Laufzeit bei Find konstant, bei FindDupGE und FindDup jedoch immer O(h).
Die Höhe h ist im entarteten Fall so groß wie die Anzahl der vorhanden Elemente n. Beim Aufbau eines Baumes, was einem Sortierlauf entspricht, muss im Extremfall jedes Element mit jedem verglichen werden – ergibt in summa
 Vergleiche.
Vergleiche.Gewichtsbalancierte Suchbäume können im Mittel auf konstante Laufzeit kommen, verhalten sich jedoch linear im schlechtesten Fall. Höhen-balancierte Suchbäume haben eine Höhe von O(log n) und ermöglichen so die Suche in garantiert logarithmischer Laufzeit. Der Aufbau eines Baumes kommt dann auf O(n log n) Vergleiche – das entspricht den besten Sortieralgorithmen.
Logarithmische Höhe gilt sogar im Durchschnitt für zufällig erzeugte Suchbäume, wenn die folgenden Bedingungen erfüllt sind:
- Alle Permutationen der einzufügenden und zu löschenden Elemente sind gleich wahrscheinlich.
- Bei Modifikationen des Baumes wird auf „asymmetrische“ Löschoperation verzichtet, d. h. die Abstiege bei den Löschungen nach links und die nach rechts halten sich im Mittel die Waage.
Traversierung
Traversierung (Querung) bezeichnet das systematische Erforschen der Knoten des Baumes in einer bestimmten Reihenfolge.
Es gibt verschiedene Möglichkeiten, die Knoten von Binärbäumen zu durchlaufen. Beim binären Suchbaum sind jedoch die sog. in-order- oder reverse in-order-Traversierungen die eindeutig bevorzugten, da sie mit der eingeprägten Totalordnung korrespondieren.
Traversierung (Einzelschritt)
Der folgende Pseudocode Next gibt ausgehend von einem Knoten das nächste Element in ab- oder aufsteigender Reihenfolge zurück – eine iterative Implementierung. Der Vorschlag kommt ohne Zeiger zum Vaterknoten aus. Dafür muss das Eingabeobjekt, hier Cursor genannt, den ganzen Pfad vom aktuellen Knoten bis zur Wurzel enthalten, und dieser muss von der Next-Funktion auch entsprechend gepflegt werden. Die passende Datenstruktur für den Pfad ist der Stapelspeicher, engl. Stack, mit den Operationen push und pop. Die Überlaufbedingung bei push wird im vorliegenden Vorschlag nicht explizit behandelt; aber es könnte ohnehin nur mit abnormalen Ende reagiert werden, was die push-Funktion alleine genauso gut kann. Bei höhen-balancierten Bäumen ist der Speicherbedarf für den Stack logarithmisch in der Zahl der Knoten und damit recht überschaubar (vorgerechnetes Beispiel AVL-Baum).
Die etwas einfachere Version der Funktion, bei der ein Zeiger zum Vater in jedem Knoten vorausgesetzt wird und deshalb der Cursor ohne Stack auskommt, ist beim Binärbaum aufgeführt. Der Speicherbedarf für den Baum erhöht sich allerdings um einen festen Prozentsatz.
Bei einer längeren Traversierung (mehreren Aufrufen von Next) wechseln sich Halbblätter und höherrangige Vorfahren ab.
Next(c) { c: Cursor { // Dieser Cursor enthält: c.d: Richtung // (1) Left, Right oder EndOfTree c.n: Knoten // (2) Knoten oder Baum (nur bei EndOfTree) c.t: Baum // (3) Baum (enthält den Zeiger zur Wurzel) c.p: Pfad // (4) Pfad vom Vater des Knotens zur Wurzel } x,y: Knoten x = c.n // Ausgangsknoten dieses Einzelschritts d = c.d // gewünschte Richtung der Traversierung y = x.child[d] if y ≠ null then { // 1 Schritt in die gegebene Richtung push(c.p, x) // Vater von y in den Stack d = 1 - d // spiegele Left <-> Right // Abstieg in Richtung Blätter über Kinder in der gespiegelten Richtung x = y.child[d] while x ≠ null do { push(c.p, y) // Vater von x in den Stack y = x x = y.child[d] } c.n = y // Ergebnis: das nächste Halbblatt in Richtung c.d return c // (Es ist Halbblatt auf seiner (1-c.d)-Seite.) } // Am Anschlag, deshalb Aufstieg zur Wurzel über die Vorfahren in der ... do { // ... c.d-„Linie“ (nur linke oder nur rechte) y = x x = pop(c.p) // Vater von y aus dem Stack if x = c.t then { // y ist die Wurzel. // Somit gibt es kein Element mehr in dieser Richtung. c.n = c.t // Ergebnis: der Baum als Vater der Wurzel c.d = EndOfTree // signalisiere das Ende der Traversierung return c } } until y ≠ x.child[d] // Es gab beim Aufsteigen einen Richtungswechsel: c.n = x // Ergebnis: der erste Vorfahr in der gespiegelten Richtung return c }Die Traversierung über den ganzen Baum umfasst pro Bogen einen Abstieg und einen Aufstieg; der Aufwand bei n Knoten ist also
 . Daher ist der Aufwand für eine Einzel-Traversierung im Mittel O(1). Im schlechtesten Fall ist er O(h) mit h als der Höhe des Baums.
. Daher ist der Aufwand für eine Einzel-Traversierung im Mittel O(1). Im schlechtesten Fall ist er O(h) mit h als der Höhe des Baums.Für rekursive Implementierungen siehe Binärbaum.
Proximitäts-Suche
Zusammen mit der Suchfunktion lässt sich mit der oben gezeigten Einzelschritt-Traversierung eine „Proximitäts“-Suche realisieren. (Proximitäts-Suche ist ein Arbeitstitel. Der Sachverhalt ist nichts Besonderes und kommt in der Literatur sicherlich vor, ist aber jetzt nicht gefunden worden. Leider ist „unscharfe Suche“ als Fuzzy-Suche schon vergeben und bedeutet etwas wesentlich Anderes.) Gemeint ist eine Suche in der Nähe eines bestimmten Schlüssels, z. B. auf „größer gleich“ (bzw. „kleiner gleich“). Die obigen Suchfunktionen Find, FindDupGE und FindDup liefern nämlich im „ungleich“-Fall einen Einfügepunkt. Dieser enthält, wenn der Baum nicht leer ist, ein Element, das entweder das kleinste unter den größeren ist oder das größte unter den kleineren. Im ersteren Fall können wir den Wunsch „größer gleich“ direkt befriedigen. Im letzteren Fall gehen wir zum nächsten Element in aufsteigender Reihenfolge, wenn es noch eines gibt, und geben dieses zurück, denn es muss ein größeres sein. Die Logik für die gespiegelte Version liegt auf der Hand.
Eine ähnliche Vorgehensweise findet sich bei der Index Sequential Access Method, wenn auch nicht auf derselben Ebene.
Einfügen
Es sei angenommen, dass die Navigation zum Einfügepunkt bereits erledigt ist. Einfügepunkt bedeutet einen Knoten und eine Richtung (rechts bzw. links). Ein unmittelbarer Einfügepunkt in einem binären Baum ist immer ein rechtes (bzw. linkes) Halbblatt (d. i. ein Knoten ohne rechten (bzw. linken) Nachfolger), ein mittelbarer ist der unmittelbare Nachbar in der angegebenen Richtung und spezifiziert zusammen mit der Gegenrichtung dieselbe Stelle im Binärbaum – zum echten Einfügen muss aber die Einfügefunktion noch bis zu dem Halbblatt hinabsteigen, welches den unmittelbaren Einfügepunkt darstellt. Die obigen Funktionen Find, FindDupGE und FindDup liefern als Ergebnis einen (unmittelbaren) Einfügepunkt (Find nicht bei „Equal“).
Zum Einfügen lässt man den unmittelbaren Einfügepunkt (das Kind in der entsprechenden Richtung) auf das neue Element verweisen, damit ist dieses korrekt entsprechend der totalen Quasiordnung eingefügt. Die Komplexität der Einfügeoperation ist somit konstant. Wird allerdings ein Suchvorgang mit hinzugerechnet, dominiert dieser die Komplexität.
Nach dem Einfügen ist das neue Element ein Blatt des Suchbaums.
Durch wiederholtes Einfügen von aufsteigend (oder absteigend) sortierten Schlüsseln kann es dazu kommen, dass der Baum zu einer linearen Liste entartet.
Löschen
Das Löschen im binären Suchbaum unterscheidet sich nicht vom Löschen in einem binären Baum. Gegeben ist der zu löschende Knoten.
Durch wiederholtes Löschen kann es dazu kommen, dass der Baum zu einer linearen Liste entartet.
Wegen der unvermeidlichen Abstiege bis zu den Halb-Blättern ist die Komplexität der Löschoperation im schlechtesten Fall O(h), wobei h die Höhe des Baumes ist.
Auswahlkriterien
Das binäre Suchen im Array kann als eine Art „Vorläufer“ der binären Suchbäume angesehen werden. Da es sich bei Einfügungen und Löschungen linear verhält und dann auch die Speicherverwaltung seines Arrays sorgfältig überlegt werden muss, wird es in der Praxis fast nur für statische, vorsortierte Tabellen eingesetzt. Sind also Einfügungen oder Löschungen für die Anwendung wichtig, sind die Binärbäume geeigneter. Bezüglich Suchzeit und Speicher verhalten sich binäres Suchen im Array und höhenbalancierte binäre Suchbäume asymptotisch gleich.
Obwohl rein zufällige binäre Suchbäume sich im Mittel logarithmisch verhalten, garantiert ein binärer Suchbaum ohne irgendeine Vorkehrung, die einer Entartung entgegenwirkt, keineswegs eine unterlineare Laufzeit. Leider können Entartungen systematisch vorkommen, z. B. wenn ein Programmierer massenhaft nahe benachbarte Sprungmarkennamen vergibt.
Es gibt jedoch sehr viele Konzepte, die dazu entwickelt wurden, eine ausreichende Balanciertheit sicherzustellen. Hierbei stehen sich immer Aufwand und Ertrag gegenüber. Z. B. ist der Aufwand, einen binären Suchbaum ständig vollständig gefüllt zu halten, so hoch, dass sich dieser Aufwand nur bei ganz extrem vom Suchen dominierten Anwendungen lohnen dürfte.
Ein wichtiges Kriterium für die Auswahl ist, ob der Binärbaum statisch ist, und so ein einmaliger optimaler Aufbau ausreicht, oder ob verändernde Operationen wie Einfügen und Löschen wichtig sind. Für erstere kommen gewichtete Suchbäume in Betracht, worunter auch der Bellman-Algorithmus. Bei letzteren sind höhen-balancierte Suchbäume wie der AVL-Baum und der Rot-Schwarz-Baum, aber auch Splay-Bäume von Interesse.
Vergleiche der Effizienz verschiedener Suchalgorithmen anhand realistischer Beispiele sind zu finden bei Ben Pfaff.
Bei diesen Überlegungen wurde generell angenommen, dass der ganze Baum im Arbeitsspeicher (Hauptspeicher) untergebracht ist. Spielen Zugriffe zu externen Medien eine Rolle, kommen ganz andere Kriterien hinzu. Schon der B-Baum, der solche Gesichtspunkte zu berücksichtigen versucht, ist zwar ein Suchbaum, aber nicht mehr binär.
Siehe auch
Literatur
- Donald Knuth. The art of computer programming Volume 3, Sorting and Searching, Dritte Auflage. Addison-Wesley, 1997. ISBN 0-201-89683-4.
Weblinks



Wikimedia Foundation.