- Suffix-Baum
-
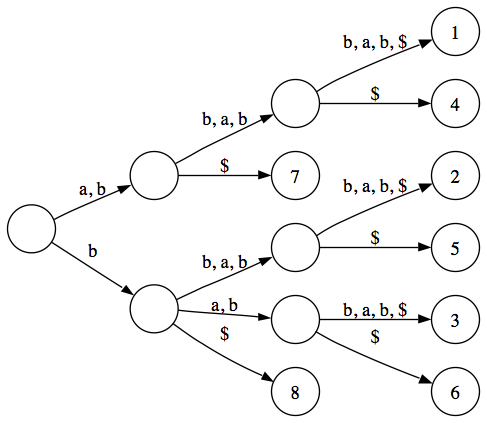
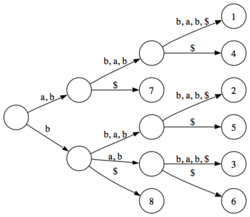 Suffixbaum für abbabbab, Blätter sind mit den Startindizes (1-basiert) der entsprechenden Suffixe beschriftet, $ markiert das Ende eines Suffixes
Suffixbaum für abbabbab, Blätter sind mit den Startindizes (1-basiert) der entsprechenden Suffixe beschriftet, $ markiert das Ende eines SuffixesEin Suffixbaum ist eine vielseitige Datenstruktur, die effiziente Lösungen zahlreicher Probleme im Bereich der Stringverarbeitung ermöglicht. Ein Suffixbaum speichert alle Suffixe (Endungen) einer Zeichenkette. Er kann in linearer Zeit mit linearem Speicherverbrauch aufgebaut werden und ermöglicht, einmal aufgebaut, das schnelle Durchführen vieler Operationen wie z.B. die Suche nach Wörtern oder Sätzen in längeren Texten.
Inhaltsverzeichnis
Definition
Ein Suffixbaum T für einen String S mit m Symbolen ist ein gerichteter Baum mit m Blättern. Jede Kante ist mit einem Teilstring von S beschriftet. Jeder innere Knoten von T hat mindestens zwei Kinder, deren Kantenbeschriftungen nie mit dem gleichen Symbol beginnen. Für jedes Blatt i in T ergeben die Beschriftungen der Kanten auf dem Pfad von der Wurzel zu i aneinander gehängt das Suffix von S, das an Index i beginnt. Somit enthält T alle Suffixe von S, wobei mehrfach auftretende Teilstrings nur einmal in T enthalten sind (siehe Abbildung).
Konstruktion
Der Baum besteht zu Anfang aus einem Wurzelknoten und einer Liste von (Zeigern auf) alle fortsetzbaren Stellen im Baum, dh. zu Anfang aus lediglich einem Zeiger auf den Wurzelknoten. Der Baum wird für ein schrittweise zu verlängerndes Wort aufgebaut. Für alle Knoten aus der Liste der fortsetzbaren Stellen wird eine Kante zu einem neuen Knoten gezogen. Diese Kante wird mit dem zuletzt an das Wort angefügten Buchstaben beschriftet. Dieser neue Knoten wird dann in eine Liste der fortsetzbaren Stellen für die nächste Iteration aufgenommen. Zuletzt wird immer auch der Startknoten mit in die neue Liste aufgenommen (da das leere Wort immer ein gültiges Suffix ist). Existiert zu einer fortsetzbaren Stelle bereits eine Kante, deren Beschriftung dem zuletzt angefügten Buchstaben entspricht, so wird kein Knoten hinzugefügt, und stattdessen der bereits existierende Zielknoten in die Liste der fortsetzbaren Stellen aufgenommen.
Durch das Hinzufügen des Startknotens in jedem Schritt, ist die Liste der fortsetzbaren Stellen nach n Iterationen auch n+1 Elemente lang, was in quadratischer Laufzeit resultiert. Es existiert ein Algorithmus mit linearer Laufzeit.
Anwendungen
Dadurch ermöglicht ein Suffixbaum die effiziente Lösung zahlreicher Probleme im Bereich der Stringverarbeitung. Die Konstruktion des Baumes ist in linear wachsender Laufzeit und linear wachsendem Speicherplatzbedarf möglich. Ein Suffixbaum ermöglicht etwa im Bereich des exakten Stringvergleichs in einem Text der Länge m nach Vorverarbeitung in O(m) das Suchen von k Mustern der Länge n mit einer Laufzeitkomplexität von nur O(k+n). Auch im Bereich des weichen Stringvergleichs ermöglicht ein Suffixbaum effiziente Verfahren, etwa beim Matching mit wildcards oder k-mismatch (siehe Gusfield 1999:199ff.) oder in Form einer Beschleunigung der Ermittlung der Levenshtein-Distanz über hybrides dynamic programming (siehe Gusfield 1999:279ff.).
Für eine ausführliche Darstellung und mehr als 20 weitere Anwendungen von Suffixbäumen siehe Gusfield (1999:89ff.).
Geschichte
- Morrison (1968): Patricia-Trie.
- Weiner (1973): Erster Algorithmus zur Konstruktion von Suffixbäumen mit linear wachsender Laufzeit.
- McCreight (1976): Weiterentwicklung mit höherer Speicherplatzeffizienz.
- Ukkonen (1995): Konzeptionell neuer, einfacherer Algorithmus mit Laufzeit- und Speicherplatzkomplexität O(n), ermöglicht zudem eine on-line Konstruktion des Baumes.
- Giegerich & Kurtz (1995): Beschleunigter Algorithmus mittels funktionaler Sprache und lazy evaluation: Aufbau während des Suchens, nur relevante Teile des Baums werden erstellt, wenn noch nicht vorhanden.
Literatur
- Gusfield, Dan (1999 [1997]) Algorithms on Strings, Sequences and Trees.
- Böckenhauer, Hans-Joachim & Dirk Bongartz (2003) Algorithmische Grundlagen der Bioinformatik.
Siehe auch
Weblinks
Wikimedia Foundation.