- Umlaute
-
Der Begriff Umlaut wird für zwei unterschiedliche Dinge benutzt:
- für eine bestimmte Art der Vokalveränderung in germanischen Sprachen: a-Umlaut, i-Umlaut und u-Umlaut. Vom Umlaut zu unterscheiden ist der Ablaut, der eine andere Etymologie und Funktionsweise hat.
- für spezielle Buchstaben im deutschen Alphabet, mit denen die entsprechenden Laute des Neuhochdeutschen dargestellt werden, die sprachgeschichtlich allesamt i-Umlaute sind: ä, ö, ü und der Zweilaut äu.
Der Name Umlaut rührt von Jacob Grimm her, der auch den Ausdruck Brechung (für den a-Umlaut) erfand.
Auch andere Sprachen haben dem Umlaut verwandte Erscheinungen, dahin gehört insbesondere die im Griechischen und der Avestischen Sprache häufige Epenthese des i.
Inhaltsverzeichnis
- 1 Vokalveränderung
- 2 Umlautbuchstaben
- 3 Alphabetische Sortierung
Vokalveränderung
Der Umlaut ist eine Veränderung derjenigen Vokale, auf die eine Beugungs- oder Ableitungssilbe folgt oder früher folgte, die den Vokal i oder den Halbvokal j enthält. Diese Vokaländerung ist typisch für die jüngeren germanischen Sprachen. Zu unterscheiden ist der Umlaut vom Ablaut.
Ursache der Vokaländerung
i-Umlaut
Der helle Vokal i übt eine assimilierende Wirkung aus, indem er den Vokal der vorausgehenden Silbe sich selbst ähnlich, also heller macht. Dieses Phänomen nennt man auch i-Umlaut.
In althochdeutschen Zeugnissen tritt diese Wirkung zunächst nur beim ă in Erscheinung, da dessen umgelautetes Allophon durch den Buchstaben e bezeichnet wird, sowie beim schon früher eingetretenen Wandel von e>i. In späterer Zeit, deutlich seit dem Mittelhochdeutschen, kommen auch bei den Vokalen â, ŏ/ô und ŭ/û je länger je mehr eigene Grapheme (heute ä, ö, ü) oder Digraphe wie ae, oe, iu (für die Diphthonge üe<uo, öu<ou) auf. Der Umlaut bleibt auch erhalten, wenn das i oder j ausgefallen ist.
Die Umlaute ö und ü werden gegenüber dem dazugehörigen Vokal mit spitzerem Mund, bzw. weiter vorne im Mund gebildet, das heißt, ö ist ein mit runden Lippen artikuliertes e und ü ein mit runden Lippen artikuliertes i.
So heißt es im Mittelhochdeutschen ich valle, aber du vellest (fällst), weil die zweite Person ursprünglich ein i hatte (althochdeutsch fallis).
Eine spätere Entwicklung (durch Analogie) ist dagegen die Bildung des Verbs rüemen (rühmen, neben ruomen) von ruom (Ruhm); hier konnte primär kein Umlaut eintreten, weil im Althochdeutschen das ursprüngliche j der Infinitivendung wegen des vorherigen Wandels von -jan zu -en bereits verschwunden war (germanisch *hrōmjan → althochdeutsch hruomen, ruomen).
Auch bei Substantiven, deren Stammvokal im Plural umgelautet wird (Mann – Männer), erklärt sich diese Änderung durch den Einfluss eines früher in der Endsilbe der Pluralform stehenden i.
Anderseits kommt es auch nicht selten vor, dass scheinbar mit dem Verlust eines i oder j auch seine Wirkung, der Umlaut, verschwunden ist (sog. „Rückumlaut“), so wie z. B. im Mittelhochdeutschen und Neuhochdeutschen im Infinitiv für gotisch brannjan (brennen) gesagt wird, aber im Imperfekt mittelhochdeutsch brante (heute: brannte), obwohl die entsprechende gotische Form brannida lautet. Tatsächlich ist jedoch in solchen Fällen (lange Stammsilbe) primär nie ein Umlaut eingetreten (siehe schon althochdeutsch brennen / branta / gi-brant !), da das im Gotischen zwischen dem Wortstamm und der Ableitung des Imperfekts und des Partizip Perfekts noch erhaltene i im Westgermanischen schon vorher ausgefallen war. In diese Kategorie fällt u. a. auch denken / dachte / gedacht, bringen / brachte / gebracht, niederdeutsch sööken / sochte / (ge-)socht bzw. englisch to seek / sought / sought (suchen / suchte / gesucht – wegen des Wandels von germanisch *sōkjan → suohhen im Hochdeutschen gänzlich ohne Umlaut); der konsonantische Lautwandel (k/g → ch/gh, Schwund des n) ist auf den frühen Wegfall des i zurückzuführen.
Neuhochdeutsch
Im Neuhochdeutschen gelten als Umlautvokale und Diphthonge in der Regel ä, ö, ü, äu; äu werden im Allgemeinen da geschrieben, wo ein verwandtes Wort oder eine verwandte Form mit a vorhanden oder auch ohne historische Sprachkenntnis leicht zu vermuten ist, z. B. Mann – Männer, Haus – Häuser.
Der Umlaut hat auch für die deutsche Flexion immer größere Bedeutung erlangt; so dient er jetzt zur Bezeichnung der Mehrzahl, z. B. in Männer, zum Ausdruck von Verkleinerungsformen, z. B. in Häuschen. Übrigens ist er keineswegs konsequent durchgeführt, und einzelne Mundarten haben ihn fast gar nicht. In den Schweizer Dialekten hingegen hat sich der Umlaut ausgebreitet (durch Analogiebildung) und kommt oft auch dort vor, wo historisch kein i vorhanden war, welches den Umlaut hätte hervorrufen können (bspw. Taag – Tääg oder Hund – Hünd). Er ist sehr produktiv und wird auch auf jüngere Fremdwörter angewendet (Kurs – Kürs, Kantoon – Kantöön).
u-Umlaut
In den skandinavischen Sprachen (altnordische Sprachstufe, Isländisch, Färöisch) hat auch das u die gleiche assimilierende Kraft, wie das i. In diesem Fall spricht man vom u-Umlaut.
a-Umlaut
In der urgermanischen Sprachstufe gab es auch den a-Umlaut.
Umlautbuchstaben
ÜüÖöÄäMit Umlaut (Pl.: Umlaute) bezeichnet man auch die Buchstaben, die im Deutschen zur Darstellung umgelauteter Vokale benutzt werden, also Ää, Öö, Üü.
 Neue und alte Umlautformen
Neue und alte UmlautformenUmlaute werden in der Schriftkunde von den diakritischen Zeichen mit Trema unterschieden, die identisch aussehen können, aber verschiedene Bedeutungen haben (zum Beispiel die getrennte Aussprache der Vokale „A“ und „e“ in „Aëlita“). Zur in der Datenverarbeitung gelegentlich notwendigen Unterscheidung von Umlaut und Trema siehe Trema.
Artikulation in der deutschen Sprache
Artikulation im Estnischen
Im Estnischen stehen die Buchstaben Ä, Ö und Ü am Ende des Alphabets und gelten als eigenständige Buchstaben. Eine Umschreibung von Ä als AE, Ö als OE und Ü als UE ist nicht möglich, da diese dann als Diphthonge gelten würden.
Artikulation im Finnischen
Im Finnischen stehen die Buchstaben Ä ([æ]) und Ö ([œ]) am Ende des Alphabetes, nach dem Y, welches wie das deutsche Ü als [y] ausgesprochen wird. Den Buchstaben Ü gibt es in der finnischen Sprache nicht.
Artikulation im Schwedischen
Im Schwedischen stehen die Buchstaben Ä ([æ]) und Ö ([œ]) am Ende des Alphabetes, nach dem Å, welches ähnlich wie das deutsche O ausgesprochen wird. Den Buchstaben Ü gibt es in der schwedischen Sprache nicht mit Ausnahme von Namen, z. B. Müller. Diese werden z. B. in Telefonbüchern unter Y eingeordnet. (Quelle: Svenska skrivregler)
Artikulation im Ungarischen
Im Ungarischen stehen die Buchstaben ö, ü, ő, ű nach o bzw. u, wie o ó ö ő und u ú ü ű. Im Ungarischen heißen Umlaute „ékezet“, auf deutsch „Beschmückung“ oder „Verschönerung“, wobei die Umlaute mit Strich ( ’ bzw. ” ) die lange Betonung ausdrücken.
Artikulation im Isländischen
Der Buchstabe Ö ist der letzte im isländischen Alphabet.
- Gesprochen wird er: [œ], wie ein Ö in Löffel.
- Beispiel: köttur (Katze)
- Steht er jedoch vor nk, ng oder gi so spricht man ihn wie [œy], ähnlich wie in feuille (franz. für Blatt)
- Beispiel: fjallgöngumaður (Bergsteiger)
Darstellung von Umlauten
 Entstehung der Umlautpunkte am Beispiel des ä
Entstehung der Umlautpunkte am Beispiel des äIn Frakturschriften wurden die Umlaute durch ein nachgestelltes oder über den Buchstaben gestelltes kleines „e“ geformt. Die Konvention, Umlaute mit zwei Punkten über dem Buchstaben auszuzeichnen, entwickelte sich im Deutschen aus einer vertikalen Ligatur von Vokal und einem darüber angedeuteten Kurrent-e, das wie zwei verbundene Aufstriche (etwa wie 11) geschrieben wurde. In einigen Frakturschriften ist das übergeschriebene e auch heute noch zu finden. Die Darstellung eines Umlauts mit e ist inzwischen bis auf wenige Ausnahmen nur noch üblich, wenn der verwendete Zeichensatz keine entsprechenden Buchstaben zur Verfügung stellt (Beispiele: ä → ae, Ä → AE oder Ae). In deutschsprachigen Kreuzworträtseln werden Umlaute dagegen meistens als AE, OE und UE geschrieben.
In der Schreibschrift gibt es neben den zwei übergestellten Punkten auch noch andere Schreibweisen (allographische Varianten). Die beiden häufigsten Varianten sind a) zwei kurze vertikale Striche anstelle der Punkte (daher ist in Österreich, wo diese Schreibweise bevorzugt wird, auch von ü-/ä-/ö-Stricherl die Rede), b) ein horizontaler Strich über dem Buchstaben, der gerade oder leicht nach unten durchgebogen ist. Letztere Schreibweise hat den Nachteil, dass sie dem u-Strich ähnelt, mit dem manche in der Schreibschrift den Kleinbuchstaben u versehen, um ihn vom Buchstaben n zu unterscheiden. Somit besteht bei dieser Schreibweise eine Verwechselungsgefahr zwischen u und ü.
In der Werbegraphik und bei stilisierter Schrift werden die Umlautpunkte oft verfremdet; z. B. werden stattdessen einzelne Punkte, Striche gesetzt oder andere graphische Merkmale, die origineller wirken und den Umlaut trotzdem unterscheiden sollen (vgl. etwa die Logos österreichischer Parteien).
Im Ungarischen sind dagegen zwei Formen der Umlautkennzeichnung jeweils als graphematisches Merkmal zu werten, d. h. sie haben bedeutungsunterscheidende Funktion. Von den Punkten (Trema) zu unterscheiden ist der so genannte Doppelakut (zwei nebeneinanderstehende Akut-Akzente), der wie der einfache Akut-Akzent auf anderen Vokalbuchstaben der Kennzeichnung der langen Aussprache dient.
Im Finnischen können auch Akzentzeichen (Á, Ó) anstelle der Umlautpunkte verwendet werden. Diese Schreibweise gilt aber als veraltet und wird nur noch selten in handschriftlichen Texten, sowie in der Werbung (v. a. Lichtreklame) verwendet.
Im Nauruischen werden die Umlaute mit einer Tilde dargestellt (ä=ã, ö=õ, ü=ũ). Die Schreibung der Tilden ist heutzutage jedoch nicht mehr üblich, sodass Wörter mit Umlauten in der Regel ohne Tilden geschrieben werden.
Darstellung in Computersystemen
 Umlaute auf deutscher Computertastatur
Umlaute auf deutscher ComputertastaturDa frühe Computertechnologie oft ohne Rücksicht auf nationale Besonderheiten entwickelt wurde, war die Darstellung von Umlauten in vielen Bereichen, wenn überhaupt, nur durch spezielle Anpassungen möglich.
Im Sieben-Bit-ASCII-Zeichensatz sind Umlaute nicht enthalten, weshalb viele ältere Computersysteme sie nicht ohne weiteres darstellten. Allerdings waren nach ISO 646 zwölf Zeichen zur Verwendung für nationale Sonderzeichen vorgesehen. Von diesen wurden für die Darstellung des deutschen Alphabets vor der Einführung erweiterter Zeichensätze sieben Zeichen ([\]{\}~) zur Darstellung der deutschen Umlaute und des Eszett (ÄÖÜäöüß) benutzt. Für den ASCII-Code war ursprünglich auch die zusätzliche Verwendung des ASCII-Anführungszeichens (") als Umlaut-Zeichen gedacht, analog zur Doppelverwendung der Tilde (~), des Zirkumflex (^) und des Gravis (`).
Die ASCII-Erweiterung ISO 8859-1 (Latin 1) enthält alle Umlaute. Fast alle modernen Computer benutzen auch den im Jahr 1991 erstmals veröffentlichten Unicode-Standard und können Umlaute verarbeiten und darstellen. Da die älteren ISO-Kodierungen nicht mit der verbreiteten UTF-8-Kodierung für Unicode übereinstimmen, können sich auch auf modernen Computern Probleme mit der Darstellung von Umlauten ergeben.
In der Eingabeaufforderung von Microsoft Windows wird aus Kompatibilitätsgründen immer noch der alte IBM-PC-Zeichensatz verwendet, sodass Umlaute und ß dort andere Codenummern erhielten.
Durch fremdsprachige optische Zeichenerkennung wird aus dem „ü“ manchmal fälschlicherweise „ii“, wie beispielsweise in „Miihe“, was manchmal von Deutsch-Unkundigen weiterverwendet wird.
Unicode
Die Umlaute sind im Unicode-Zeichensatz folgendermaßen definiert und kodiert:
Kodierung in Unicode Zeichen Unicode Name Position Bezeichnung Ä U+00C4 Latin capital letter A with diaeresis Lateinischer Großbuchstabe Ä Ö U+00D6 Latin capital letter O with diaeresis Lateinischer Großbuchstabe Ö Ü U+00DC Latin capital letter U with diaeresis Lateinischer Großbuchstabe Ü ä U+00E4 Latin small letter a with diaeresis Lateinischer Kleinbuchstabe ä ö U+00F6 Latin small letter o with diaeresis Lateinischer Kleinbuchstabe ö ü U+00FC Latin small letter u with diaeresis Lateinischer Kleinbuchstabe ü Linguistisch gesehen ist die Unicode-Benennung jedoch nicht korrekt, da eine Diärese (ein Trema) das getrennte Sprechen von Vokalen bezeichnet.
Unicode kennt zwei kanonisch äquivalente Formen der Kodierung der Umlaut-Buchstaben, precomposed und decomposed. Die decomposed-Form wird mit dem Zeichen U+0308 (COMBINING DIAERESIS) gebildet.
UTF-8
In der URL-Kodierung werden Umlaute nach UTF-8 und mit vorangestelltem %-Zeichen kodiert und auch in E-Mails sollten Umlaute als UTF-8 kodiert werden. Letzteres sollte jedes moderne E-Mail-Programm umsetzen.
Die Umlaute in URLs Zeichen Unicode Unicode binär UTF-8 binär UTF-8 hexadezimal Ä U+00C4 00000000 11000100 11000011 10000100 %C3%84 Ö U+00D6 00000000 11010110 11000011 10010110 %C3%96 Ü U+00DC 00000000 11011100 11000011 10011100 %C3%9C ä U+00E4 00000000 11100100 11000011 10100100 %C3%A4 ö U+00F6 00000000 11110110 11000011 10110110 %C3%B6 ü U+00FC 00000000 11111100 11000011 10111100 %C3%BC HTML
Weil man im normalen HTML-Quelltext ursprünglich nicht die Zeichenkodierung festlegen konnte, musste man Umlaute mittels so genannter benannter Zeichen (named entities) verwenden, die aus einem einleitenden
&, einem symbolischen Namen und einem schließenden;bestehen. Heute ist es möglich, jedes beliebige Unicode-Zeichen darzustellen, indem man die dezimale Nummer mit&#und;bzw. die hexadezimale Nummer mit&#xund;umschließt. Ferner gibt es nun die Möglichkeit, den Zeichensatz per Meta-Anweisung (<meta ... />) im HTML-Dokument festzulegen, wodurch die Darstellung der Umlaute mittels benannter Zeichen meist nicht nötig ist.Allgemein gilt, dass ein Vokal mit zwei Punkten darüber in HTML nach folgendem Schema gebildet wird:
&gefolgt vom Vokal gefolgt vonuml;.Kodierung in HTML Zeichen Unicodeposition HTML hexadezimal dezimal benannt Ä U+00C4 Ä Ä Ä Ö U+00D6 Ö Ö Ö Ü U+00DC Ü Ü Ü ä U+00E4 ä ä ä ö U+00F6 ö ö ö ü U+00FC ü ü ü TeX und LaTeX
TeX und LaTeX können den Umlaut über beliebige Zeichen setzen. Dazu gibt es zwei Befehle
- im Textmodus für den Textsatz erzeugt
"aein ä - im mathematischen Modus erzeugt
\ddot adas Formelzeichen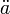
Mit dem Paket german.sty oder mit dem Paket babel vereinfacht sich die Eingabe der deutschen Umlaute zu
"a,"ound"u. Durch Angabe einer passenden Option zum Paket inputenc ist es auch möglich, die Umlaute im Textmodus direkt einzugeben.Andere Bereiche
In Domainnamen können Umlaute mittels des Kodierungsverfahrens IDNA genutzt werden.
Bei Schreibmaschinen gibt es neben der üblichen Bauform mit separaten Umlauten auch Bauformen, bei denen die Umlaute aus separaten Zeichen für die Buchstaben und die Umlautpunkte zusammengesetzt wurden.
Siehe auch: Wikipedia:Sonderzeichen, Heavy-Metal-Umlaut
Alphabetische Sortierung
Die Sortierung von Wörtern, die Umlaute enthalten, ist sowohl vom Land, als auch vom Zweck abhängig. Näheres zum Sortieren findet man unter: Alphabetische Sortierung.



Wikimedia Foundation.