- Web-Suche
-
Eine Suchmaschine ist ein Programm zur Recherche von Dokumenten, die in einem Computer oder einem Computernetzwerk wie z. B. dem World Wide Web gespeichert sind. Internet-Suchmaschinen haben ihren Ursprung in Information-Retrieval-Systemen. Sie erstellen einen Schlüsselwort-Index für die Dokumentbasis, um Suchanfragen über Schlüsselwörter mit einer nach Relevanz geordneten Trefferliste zu beantworten. Nach Eingabe eines Suchbegriffs liefert eine Suchmaschine eine Liste von Verweisen auf möglicherweise relevante Dokumente, meistens dargestellt mit Titel und einem kurzen Auszug des jeweiligen Dokuments. Dabei können verschiedene Suchverfahren Anwendung finden.
Die wesentlichen Bestandteile bzw. Aufgabenbereiche einer Suchmaschine sind:
- Erstellung und Pflege eines Indexes (Datenstruktur mit Informationen über Dokumente),
- Verarbeiten von Suchanfragen (Finden und Ordnen von Ergebnissen) sowie
- Aufbereitung der Ergebnisse in einer möglichst sinnvollen Form.
In der Regel erfolgt die Datenbeschaffung automatisch, im WWW durch Webcrawler, auf einem einzelnen Computer durch regelmäßiges Einlesen aller Dateien in vom Benutzer spezifizierten Verzeichnissen im lokalen Dateisystem.
Inhaltsverzeichnis
Arten von Suchmaschinen
Suchmaschinen lassen sich nach einer Reihe von Merkmalen kategorisieren. Die nachfolgenden Merkmale sind weitgehend unabhängig. Man kann sich beim Entwurf einer Suchmaschine also für eine Möglichkeit aus jeder der drei Merkmalsgruppen entscheiden, ohne dass dies die Wahl der anderen Merkmale beeinflusst.
Art der Daten
Verschiedene Suchmaschinen können unterschiedliche Arten von Daten durchsuchen. Zunächst lassen sich diese grob in „Dokumenttypen“ wie Text, Bild, Ton, Video und andere unterteilen. Ergebnisseiten werden in Abhängigkeit von dieser Gattung gestaltet. Bei einer Suche nach Textdokumenten wird üblicherweise ein Textfragment angezeigt, das die Suchbegriffe enthält. Bildsuchmaschinen zeigen eine Miniaturansicht der passenden Bilder an.
Eine weitere feinere Aufgliederung geht auf datenspezifische Eigenschaften ein, die nicht alle Dokumente innerhalb einer Gattung teilen. Bleibt man beim Beispiel Text, so kann bei Usenet-Beiträgen nach bestimmten Autoren gesucht werden, bei Web-Seiten im HTML-Format nach dem Dokumententitel.
Je nach Datengattung ist als weitere Funktion eine Einschränkung auf eine Untermenge aller Daten einer Gattung möglich. Dieses wird im Allgemeinen über zusätzliche Suchparameter realisiert, die einen Teil der erfassten Daten ausschließt. Alternativ kann sich eine Suchmaschine darauf beschränken, von Anfang an nur passende Dokumente aufzunehmen. Beispiele sind etwa eine Suchmaschine für Weblogs (statt für das komplette Web) oder Suchmaschinen, die nur Dokumente von Universitäten verarbeiten, oder ausschließlich Dokumente aus einem bestimmten Land, in einer bestimmten Sprache oder einem bestimmten Dateiformat.
Datenquelle
Ein anderes Merkmal zur Kategorisierung ist die Quelle, aus der die von der Suchmaschine erfassten Daten stammen. Meistens beschreibt bereits der Name der Suchmaschinenart die Quelle.
- Websuchmaschinen erfassen Dokumente aus dem World Wide Web,
- vertikale Suchmaschinen betrachten einen ausgewählten Bereich des World Wide Web und erfassen nur Webdokumente zu einem bestimmten Thema wie Fussball, Gesundheit oder Recht.
- Usenetsuchmaschinen Beiträge aus dem weltweit verteilten Diskussionsmedium Usenet.
- Intranetsuchmaschinen beschränken sich auf die Rechner des Intranets einer Firma.
- Als Desktop-Suchmaschinen werden Programme bezeichnet, die den lokalen Datenbestand eines einzelnen Computers durchsuchbar machen.[1]
Wird die Datenbeschaffung manuell mittels Anmeldung oder durch Lektoren vorgenommen, spricht man von einem Katalog oder Verzeichnis. In solchen Verzeichnissen wie dem Open Directory Project sind die Dokumente hierarchisch in einem Inhaltsverzeichnis nach Themen organisiert.
Realisierung
Dieser Abschnitt beschreibt Unterschiede in der Realisierung des Betriebs der Suchmaschine.
 Indexbasierte Suchmaschine
Indexbasierte Suchmaschine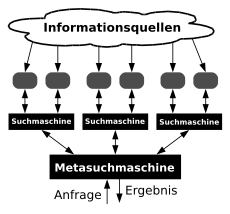 Metasuchmaschine
Metasuchmaschine Föderierte Suchmaschine
Föderierte Suchmaschine- Die heutzutage wichtigste Gruppe sind indexbasierte Suchmaschinen. Diese lesen passende Dokumente ein und legen einen Index an. Dabei handelt es sich um eine Datenstruktur, die bei einer späteren Suchanfrage verwendet wird. Nachteil ist die aufwendige Pflege und Speicherung des Indexes, Vorteil ist die Beschleunigung des Suchvorgangs. Häufigste Ausprägung dieser Struktur ist ein Invertierter Index.
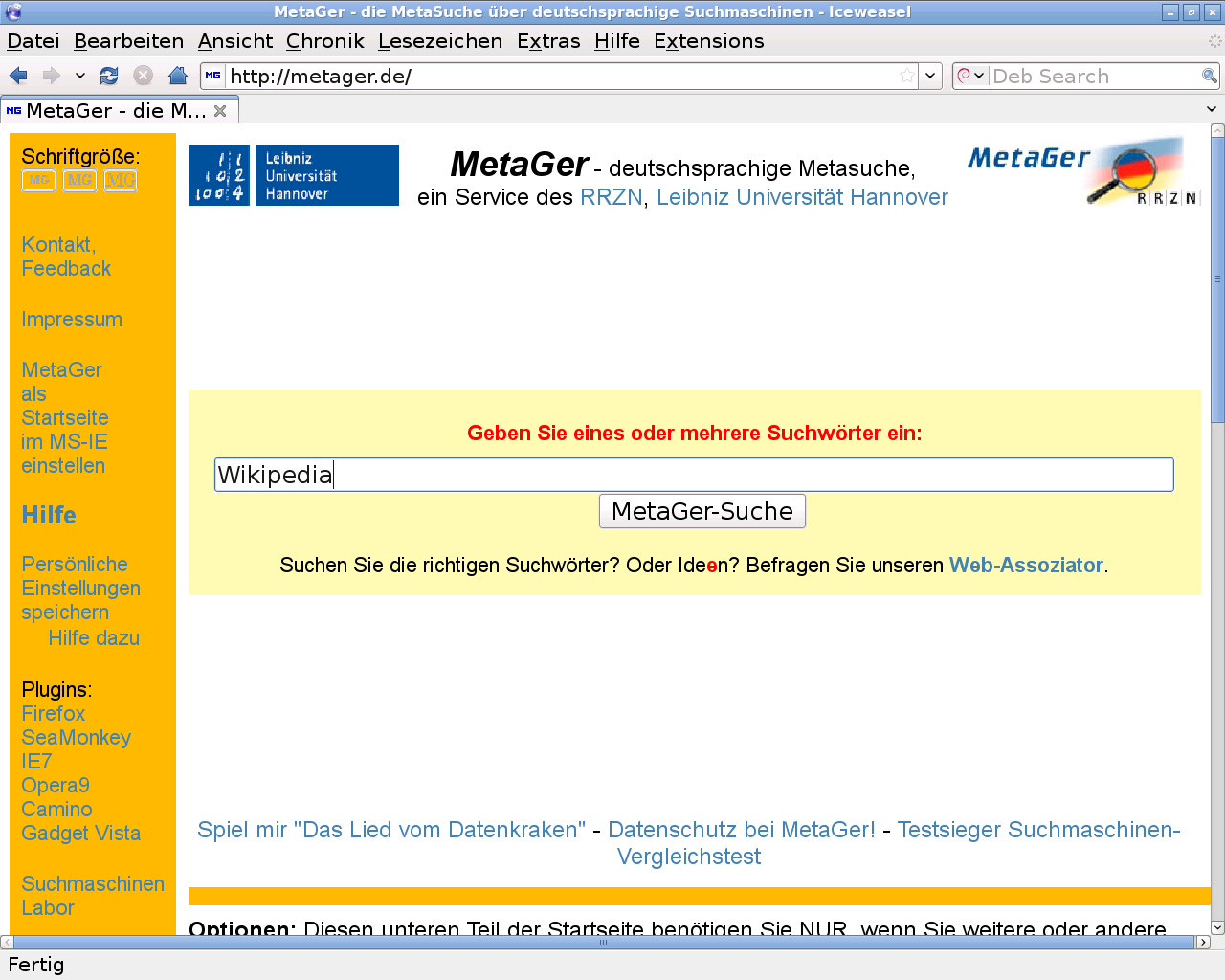
 Screenshot der Metasuchmaschine "MetaGer"
Screenshot der Metasuchmaschine "MetaGer"- Metasuchmaschinen senden Suchanfragen parallel an mehrere indexbasierte Suchmaschinen und kombinieren die Einzelergebnisse. Als Vorteil ergeben sich die größere Datenmenge sowie die einfachere Implementierung, da kein Index vorgehalten werden muss. Nachteil ist die relativ lange Dauer der Anfragebearbeitung. Außerdem ist das Ranking durch reine Mehrheitsfindung von fragwürdigem Wert. Die Qualität der Ergebnisse wird unter Umständen auf die Qualität der schlechtesten befragten Suchmaschine reduziert. Metasuchmaschinen sind vor allem bei selten vorkommenden Suchbegriffen sinnvoll.
- Weiterhin existieren Hybridformen. Diese besitzen einen eigenen, oft relativ kleinen Index, befragen aber auch andere Suchmaschinen und kombinieren schließlich die Einzelergebnisse. Sogenannte Echtzeitsuchmaschinen starten etwa den Indexierungsvorgang erst nach einer Anfrage. So sind die gefundenen Seiten zwar stets aktuell, die Qualität der Ergebnisse ist aber aufgrund der fehlenden breiten Datenbasis insbesondere bei weniger gängigen Suchbegriffen schlecht.
- Ein relativ neuer Ansatz sind Verteiltes Suchmaschinen bzw. Föderierte Suchmaschine. Dabei wird eine Suchanfrage an eine Vielzahl von einzelnen Computern weitergeleitet, die jeweils eine eigene Suchmaschine betreiben, und die Ergebnisse zusammengeführt. Vorteil ist die hohe Ausfallsicherheit aufgrund der Dezentralisierung und – je nach Sichtweise – die fehlende Möglichkeit, zentral zu zensieren. Schwierig zu lösen ist allerdings das Ranking, also die Sortierung der grundsätzlich passenden Dokumente nach ihrer Relevanz für die Anfrage.
Interpretation der Eingabe
Die Suchanfrage eines Nutzers wird vor der eigentlichen Suche interpretiert und in eine für den intern verwendeten Such-Algorithmus verständliche Form gebracht. Dies dient dazu, die Syntax der Anfrage möglichst einfach zu halten und dennoch komplexe Anfragen zu erlauben. Viele Suchmaschinen unterstützen die logische Verknüpfung von verschiedenen Suchworten durch Boolesche Operatoren. Dadurch lassen sich Webseiten finden, die bestimmte Begriffe enthalten, andere jedoch nicht.
Eine neuere Entwicklung ist die Fähigkeit von etlichen Suchmaschinen, implizit vorhandene Informationen aus dem Zusammenhang der Suchanfrage selbst zu erschließen und zusätzlich auszuwerten. Die bei unvollständigen Suchanfragen typischerweise vorhandenen Mehrdeutigkeiten der Suchanfrage können so reduziert, und die Relevanz der Suchergebnisse (das heißt, die Übereinstimmung mit den bewussten oder unbewussten Erwartungen des/der Suchenden) erhöht werden. Aus den semantischen Gemeinsamkeiten der eingegebenen Suchbegriffe wird (siehe auch: Semantik) auf eine, oder mehrere, hinterliegende Bedeutungen der Anfrage geschlossen. Die Ergebnismenge wird so um Treffer auf semantisch verwandte, in der Anfrage jedoch nicht explizit eingegebene Suchbegriffe, erweitert. Dies führt in der Regel nicht nur zu einer quantitativen, sondern, vor allem bei unvollständigen Anfragen und nicht optimal gewählten Suchbegriffen, auch zu einer qualitativen Verbesserung (der Relevanz) der Ergebnisse, weil die in diesen Fällen eher unscharf durch die Suchbegriffe abgebildeten Such-Intentionen durch die von den Suchmaschinen verwendeten statistischen Verfahren in der Praxis erstaunlich gut wiedergegeben werden. (Siehe auch: semantische Suchmaschine und Latent Semantic Indexing).
Unsichtbar mitgegebene Informationen (Ortsangaben, und andere Informationen, im Fall von Anfragen aus dem Mobilfunknetz), oder erschlossene 'Bedeutungs-Vorlieben' aus der gespeicherten Such-History des Benutzers, sind weitere Beispiele für nicht explizit in den eingegebenen Suchbegriffen vorgegebene, von etlichen Suchmaschinen zur Modifikation und Verbesserung der Ergebnisse verwendete Informationen.
Es gibt daneben auch Suchmaschinen, die nur mit streng formalisierten Abfragesprachen abgefragt werden können, dadurch in der Regel jedoch auch sehr komplexe Anfragen sehr präzise beantworten können.
Eine bislang noch nur ansatzweise oder auf beschränkte Informationensgrundlagen realisierbare Fähigkeit von Suchmaschinen ist die Fähigkeit zur Bearbeitung natürlichsprachiger sowie unscharfer Suchanfragen. (Siehe auch: semantisches Web).
Merkmale häufig genutzter Suchmaschinen
Die gängigste und meistgenutzte Kombination von Merkmalen benutzt das WWW als Datenquelle, für Text-Dokumente im HTML-Format und baut zur Realisierung einen Index auf. Die Interpretation der Eingabe erfolgt meist auf der Basis einer einfachen Syntax, bei der etwa durch ein dem vorangestelltes "-" ein Schlüsselwort ausgeschlossen werden kann. Die Suchmaschinen der drei in den USA größten Anbieter Google (53,7 %), Yahoo Search (22,7 %) und Microsofts Live Search (8,9 %) arbeiten nach diesem Muster[2].
Darstellung der Ergebnisse
Die Seite, auf der die Suchergebnisse dem Benutzer ausgegeben werden (manchmal auch als Search engine results page bezeichnet), gliedert sich (häufig auch räumlich) bei vielen Suchmaschinen in die Natural Listings und die Sponsorenlinks. Während letztere ausschließlich gegen Bezahlung in den Suchindex aufgenommen werden, sind in ersteren alle dem Suchwort entsprechenden Webseiten aufgelistet.
Um dem Anwender die Benutzung der Suchmaschine zu erleichtern, werden Ergebnisse nach Relevanz (Hauptartikel: Suchmaschinenranking) sortiert, wofür jede Suchmaschine ihre eigenen, meistens geheim gehaltenen Kriterien heranzieht. Dazu gehören:
- Die grundlegende Bedeutung eines Dokuments (bei Google der PageRank-Wert).
- Häufigkeit und Stellung der Suchbegriffe im jeweiligen gefundenen Dokument.
- Einstufung und Anzahl der zitierten Dokumente.
- Häufigkeit von Verweisen anderer Dokumente auf das im Suchergebnis enthaltene Dokument sowie in Verweisen enthaltener Text.
- Einstufung der Qualität der verweisenden Dokumente (ein Link von einem „guten“ Dokument ist mehr wert als der Verweis von einem mittelmäßigen Dokument).
Suchverhalten der Nutzer
Suchmaschinen bieten den Zugriff auf eine Unmenge verschiedenster Informationen. Diesbezüglich lassen sich Suchanfragen in drei Arten einteilen.
Navigationsorientiert
Der Nutzer sucht bei navigationalen Anfragen gezielt nach Seiten, die er bereits kennt, oder von denen er glaubt, sie existieren. Das Informationsbedürfnis des Nutzers ist nach dem Auffinden der Seite befriedigt. Solche Suchanfragen machen etwa 45 Prozent aller Anfragen in Deutschland aus.
Informationsorientiert
Der Nutzer sucht bei informationalen Anfragen eine Vielzahl von Angaben zu einem bestimmten Themengebiet. Mit Erhalt der Information ist die Suche beendet. Ein weiteres Arbeiten mit den benutzten Seiten bleibt meist aus. Solche Suchanfragen machen etwa 40 Prozent aller Anfragen in Deutschland aus.
Transaktionsorientiert
Der Nutzer sucht bei transaktionalen Anfragen nach Internetseiten, mit denen er zu arbeiten gedenkt. Dies sind zum Beispiel Internetshops, Chats usw. Solche Suchanfragen machen etwa 15 Prozent aller Anfragen in Deutschland aus. [3]
Probleme bei Suchmaschinen
Suchmaschinen müssen im Betrieb mit verschiedenartigen Problemen umgehen:
- Mehrdeutigkeit
- Suchanfragen sind oft unpräzise. So kann die Suchmaschine nicht selbstständig entscheiden, ob beim Begriff Laster nach einem LKW oder einer schlechten Angewohnheit gesucht werden soll (semantische Korrektheit). Umgekehrt sollte die Suchmaschine nicht zu stur auf dem eingegebenen Begriff bestehen. Sie sollte auch Synonyme einbeziehen, damit der Suchbegriff Rechner Linux auch Seiten findet, die statt Rechner das Wort Computer enthalten.
- Grammatik
- Viele mögliche Treffer gehen verloren, weil der Nutzer nach einer bestimmten grammatikalischen Form eines Suchbegriffes sucht. So findet die Suche nach dem Begriff Auto zwar alle im Suchindex enthaltenen Seiten, die diesen Begriff enthalten, nicht aber jene mit dem Begriff Autos. Manche Suchmaschinen erlauben die Suche mittels Wildcards, mit denen sich dieses Problem teilweise umgehen lässt (z. B. berücksichtigt die Suchanfrage Auto* auch den Begriff Autos oder Automatismus), allerdings muss der Nutzer die Möglichkeit auch kennen. Weiterhin wird oft Stemming verwendet, dabei werden Wörter auf ihren Grundstamm reduziert. So ist einerseits eine Abfrage nach ähnlichen Wortformen möglich (schöne Blumen findet so auch schöner Blume), außerdem wird die Anzahl der Begriffe im Index reduziert. Eine weitere Möglichkeit ist der Einsatz statistischer Verfahren, mit denen die Suchmaschine die Anfrage z. B. durch das Auftauchen verschiedener verwandter Begriffe auf Webseiten danach bewertet, ob mit der Suche nach Auto reparieren auch die Suche nach Autos reparatur oder Automatismus repariert gemeint gewesen sein könnte.
- Satzzeichen
- Fachbegriffe und Produktbezeichnungen zu deren Eigennamen ein Satzzeichen gehört (z. B. Apples Webservice .Mac oder C/net) können bei den gängigen Suchmaschinen nicht effektiv gesucht und gefunden werden. Lediglich für ein paar sehr häufige Begriffe (z. B. .Net, C#, oder C++) wurden Ausnahmen geschaffen [4].
- Datenmenge
- Das Web wächst schneller als die Suchmaschinen mit der derzeitigen Technik indizieren können. Dabei ist der den Suchmaschinen unbekannte Teil – das so genannte Deep Web – noch gar nicht eingerechnet.
- Aktualität
- Viele Webseiten werden häufig aktualisiert, was die Suchmaschinen zwingt, diese Seiten nach definierbaren Regeln (Robots) immer wieder zu besuchen. Dieses ist auch notwendig, um zwischenzeitlich aus der Datenbasis entfernte Dokumente zu erkennen und nicht länger als Ergebnis anzubieten. Das regelmäßige Herunterladen der mehreren Milliarden Dokumente, die eine Suchmaschine im Index hat, stellt große Anforderungen an die Netzwerkressourcen (Traffic) des Suchmaschinenbetreibers.
- Spam
- Mittels Suchmaschinen-Spamming versuchen manche Website-Betreiber, den Ranking-Algorithmus der Suchmaschinen zu überlisten, um eine bessere Platzierung für gewisse Suchanfragen zu bekommen. Sowohl den Betreibern der Suchmaschine als auch deren Kunden schadet dieses, da nun nicht mehr die relevantesten Dokumente zuerst angezeigt werden.
- Technik
- Suchen auf sehr großen Datenmengen so umzusetzen, dass die Verfügbarkeit hoch ist (trotz Hardware-Ausfällen und Netzengpässen) und die Antwortzeiten niedrig (obwohl oft pro Suchanfrage das Lesen und Verarbeiten mehrerer 100 MB Index-Daten erforderlich ist), stellt große Anforderungen an den Suchmaschinenbetreiber. Systeme müssen sehr redundant ausgelegt sein, zum einen auf den Computern vor Ort in einem Rechenzentrum, zum anderen sollte es mehr als ein Rechenzentrum geben, das die komplette Suchmaschinenfunktionalität anbietet.
- Recht
- Suchmaschinen werden meistens international betrieben und bieten somit Benutzern Ergebnisse von Servern, die in anderen Ländern stehen. Da die Gesetzgebungen der verschiedenen Länder unterschiedliche Auffassungen davon haben, welche Inhalte erlaubt sind, geraten Betreiber von Suchmaschinen oft unter Druck, gewisse Seiten von ihren Ergebnissen auszuschließen. Die deutschen Internet-Suchmaschinen wollen jugendgefährdende Seiten durch die Freiwillige Selbstkontrolle aus ihren Trefferlisten streichen.
Siehe auch
Themen im Umkreis von Suchmaschinen
- Suchfunktion
- Suchmaschinenoptimierung
- Semantisches Web
- Open Archives Initiative
- Business-Suchmaschine
- Top-N-Anfrage
- Schweizer Portal für Recherche im Internet
Algorithmische Grundlagen
Literatur
- Christian Ellwein: Suche im Internet für Industrie und Wissenschaft Oldenbourg, 2002, ISBN 3-486-27039-7
- Stefan Karzauninkat: Die Suchfibel: Wie findet man Informationen im Internet? Klett, 2002, 3. Aufl., ISBN 3-12-238106-0
- Michael Glöggler: Suchmaschinen im Internet Springer, 2003, ISBN 3-540-00212-X
- Heike Faller: David gegen Google. In: Die Zeit Nr. 41/2005, 6. Oktober 2005, S. 17 ff. (Dossier).
- Dirk Lewandowski: Web Information Retrieval: Technologien zur Suche im Internet, DGI, 2005, ISBN 3-925474-55-2 Online-Version des Buchs
- Dirk Lewandowski: Handbuch Internet-Suchmaschinen, Akademische Verlagsgesellschaft, Heidelberg 2008, ISBN 978-3-89838-607-4 Online-Version des Buchs
- Soumen Chakrabarti: Mining the Web: Discovering Knowledge from Hypertext Data, Morgan-Kauffman, 2003
- Rainer Strzolka: Suchmaschinenkunde für Bibliothekare, Archivare und Dokumentare Koechert, 2006, ISBN 3-922556-96-5
- Steve Lawrence und C. Lee Giles: Accessibility of information on the web, in: Nature 400, 1999, S. 107, doi:10.1038/21987
Quellen
- ↑ Artur Hoffmann: Suchmaschinen für PCs. Artikel in PC Professionell 2/2007, S. 108ff.
- ↑ Nielsen//Netratings, 2007 (Studie des US-amerikanischen Marktes)
- ↑ Broder A., A taxonomy of web search, 2002
- ↑ Wie kann ich dafür sorgen, dass Google die in meiner Suchanfrage enthaltenen Satzzeichen erkennt?
Weblinks
- Nachrichten zum Thema Suchmaschinen
- FAQ der Newsgroup de.comm.infosystems.suchmaschinen
- Suchen und Finden im Internet – Vorträge der Fachkonferenz des Münchner Kreises
- Suchmaschinen & Recht - Aktuelle Urteile und Aufsätze zu Suchmaschinen – SEO-Themen
- Links zum Thema Liste von Suchmaschinen im Open Directory Project
- Marcel Machill, Carsten Welp (Hrsg.): Wegweiser im Netz. Qualität und Nutzung von Suchmaschinen (Verlag Bertelsmann Stiftung, pdf)



Wikimedia Foundation.