- Webcrawler
-
Ein Webcrawler (auch Spider oder Searchbot) ist ein Computerprogramm, das automatisch das World Wide Web durchsucht und Webseiten analysiert. Webcrawler werden vor allem von Suchmaschinen eingesetzt. Weitere Anwendungen sind das Sammeln von RSS-Newsfeeds, E-Mail-Adressen oder von anderen Informationen.
Webcrawler sind eine spezielle Art von Bots, d. h. Computerprogrammen, die weitgehend autonom sich wiederholenden Aufgaben nachgehen.
Inhaltsverzeichnis
Geschichte
Der erste Webcrawler war 1993 der World Wide Web Wanderer der das Wachstum des Internets messen sollte. 1994 startete mit WebCrawler die erste öffentlich erreichbare WWW-Suchmaschine mit Volltextindex. Von dieser stammt auch der Name Webcrawler für solche Programme. Da die Anzahl der Suchmaschinen rasant wuchs, gibt es heute eine Vielzahl von unterschiedlichen Webcrawlern. Diese erzeugen bis zu 40% des gesamten Internettraffics[1].
Technik
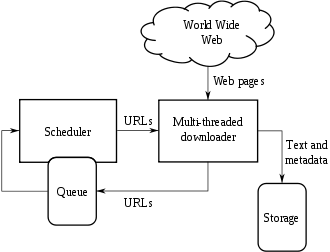 Struktur von Webcrawlern
Struktur von Webcrawlern
Wie beim Internetsurfen gelangt ein Webcrawler über Hyperlinks von einer Webseite zu weiteren URLs. Dabei werden alle aufgefundenen Adressen gespeichert und der Reihe nach besucht. Die neu gefundenen Hyperlinks werden zur Liste aller URLs hinzugefügt. Auf diese Weise können theoretisch alle erreichbaren Seiten des WWW gefunden werden. In der Praxis wird jedoch oft eine Auswahl getroffen, der Prozess irgendwann beendet und von vorne begonnen. Je nach Aufgabe des Webcrawlers wird der Inhalt der gefundenen Webseiten beispielsweise mittels Indexierung ausgewertet und gespeichert, um ein späteres Suchen in den so gesammelten Daten zu ermöglichen.
Mit Hilfe des Robots Exclusion Standards kann ein Webseitenbetreiber in der Datei robots.txt und in bestimmten Meta-Tags im HTML-Header einem Webcrawler mitteilen, welche Seiten er indizieren soll und welche nicht, sofern sich der Webcrawler an das Protokoll hält. Zur Bekämpfung unerwünschter Webcrawler gibt es auch spezielle Webseiten, sogenannte Teergruben, die den Webcrawlern falsche Informationen liefern und diese zusätzlich stark ausbremsen.
Probleme
Ein Großteil des gesamten Internets wird von Webcrawlern und damit auch von öffentlichen Suchmaschinen nicht erfasst, da viele Inhalte nicht über einfache Links, sondern beispielsweise nur über Suchmasken und zugangsbeschränkte Portale erreichbar sind. Man spricht bei diesen Bereichen auch vom „Deep Web“. Außerdem stellt die ständige Veränderung des Webs sowie die Manipulation der Inhalte (Cloaking) ein Problem dar.
Arten
Thematisch fokussierte Webcrawler werden als focused crawlers bzw. fokussierte Webcrawler bezeichnet. Die Fokussierung der Web-Suche wird einerseits durch die Klassifizierung einer Webseite an sich und die Klassifizierung der einzelnen Hyperlinks realisiert. Dadurch findet der fokussierte Crawler den besten Weg durch das Web und indiziert nur (für ein Thema bzw. eine Domäne) relevante Bereiche des Webs. Hürden bei der praktischen Umsetzung derartiger Webcrawler sind vor allem nicht-verlinkte Teilbereiche und das Training der Klassifizierer.
Webcrawler werden auch zum Data-Mining und zur Untersuchung des Internets (Webometrie) eingesetzt und müssen nicht zwangsläufig auf das WWW beschränkt sein.
Eine Sonderform der Webcrawler sind Harvester (für „Erntemaschine“). Diese Bezeichnung wird für Software verwendet, die das Internet (WWW, Usenet usw.) nach E-Mail-Adressen absucht und diese „erntet“. So werden elektronische Adressen gesammelt und können danach vermarktet werden. Die Folge sind i. d. R., vor allem aber bei Spambots, Werbe-E-Mails (Spam). Daher wird von der früher gängigen Praxis, auf Webseiten E-Mail-Adressen als Kontaktmöglichkeit per mailto:-Link anzugeben, immer häufiger Abstand genommen; manchmal wird versucht, die Adressen durch den Einschub von Leerzeichen oder Wörtern für die Bots unlesbar zu machen. So wird a@example.com zu a (at) example (dot) com. Die meisten Bots können solche Adressen allerdings erkennen. Eine ebenfalls beliebte Methode ist, die E-Mail-Adresse in eine Grafik einzubetten. Die E-Mail-Adresse ist dadurch nicht als Zeichenkette im Quelltext der Webseite vorhanden und somit für den Bot nicht als Textinformation auffindbar. Das hat für den User jedoch den Nachteil, dass er die E-Mail-Adresse nicht durch „Anklicken“ bedienerfreundlich in sein E-Mail-Programm zum Versand übernehmen kann, sondern die Adresse abschreiben muss. Viel gravierender ist jedoch, dass die Seite damit nicht mehr barrierefrei ist und sehbehinderte Menschen genauso wie Bots ausgegrenzt werden.
Ein weiterer Verwendungszweck von Webcrawlern ist das Auffinden von urheberrechtlich geschützten Inhalten im Internet.
Siehe auch
Einzelnachweise
- ↑ Yuan X., MacGregor M.H., Harms J.: "An efficient scheme to remove crawler traffic from the Internet", Computer Communications and Networks, 2002. Proceedings. Eleventh International Conference on Communications and Networks
Weblinks
- The Web Robots Pages (Englisch)
- Webcrawling – Die Erschließung des Webs, Ronny Harbich, 2008

Wikimedia Foundation.