- Wörterbuch der Deutschen Sprache
-
Das Digitale Wörterbuch der deutschen Sprache des 20. Jahrhunderts (DWDS) ist ein Projekt, dessen Ziel die Erstellung eines digitalen Wörterbuchsystems auf der Basis sehr großer elektronischer Textkorpora ist. Dabei baut es auf dem sechsbändigen Wörterbuch der deutschen Gegenwartssprache (WDG) auf, und verknüpft dieses mit eigenen Text- und Wörterbuchressourcen.
Inhaltsverzeichnis
Komponenten
In der derzeitigen Fassung des DWDS, dem Wortinformationssystem, werden vier lexikalische Informationstypen verknüpft: die Wörterbuchartikel des WDG, automatisch generierte Informationen zu Synonymen, Hyponymen, Hyperonymen aus dem WDG, Textbeispiele aus dem DWDS-Kernkorpus sowie statistische Konkurrenzinformationen aus dem Kernkorpus (die so genannten Kollokationen, die die Häufigkeiten des Vorkommens benachbarter Wörter angeben).
Wörterbuch
Das Wörterbuch der deutschen Gegenwartssprache (WDG) wurde in Berlin an der Deutschen Akademie der Wissenschaften (ab Oktober 1972: Akademie der Wissenschaften der DDR) zwischen 1952 und 1977 erarbeitet. Das WDG umfasst über 4.500 Seiten und enthält 60.000 bzw. unter Hinzunahme der Komposita 121.000 Stichwörter. Von Februar 2002 bis März 2004 wird das WDG digital erfasst, strukturiert und für die Recherche aufbereitet; es steht seit März 2003 als Nachschlagewerk über die Website des DWDS zur Verfügung.
Textkorpora
Die DWDS-Korpora werden kontinuierlich ausgebaut. Derzeit umfassen sie mehr als 1,6 Milliarden laufende Textwörter und bestehen aus zwei großen Teilkorpora: dem Kernkorpus und dem Ergänzungskorpus.
- Das DWDS-Kernkorpus umfasst etwa 100 Millionen Textwörter in 80.000 Dokumenten; es ist zeitlich gleichmäßig über das gesamte 20. Jahrhundert gestreut und nach Textsorten ausgewogen. Vier Textsorten liegen dem Korpus zugrunde: Belletristik (27%), Journalistische Prosa (26%), Fachtexte (22%) und Gebrauchstexte (20%). Die Integration von Transkriptionen gesprochener Sprache ist für das 2. Halbjahr 2007 geplant. Das DWDS-Kernkorpus ist das erste Referenzkorpus der deutschen Sprache des 20. Jahrhunderts und dem bislang als Standard geltenden British National Corpus (BNC) in seiner Qualität zumindest ebenbürtig.
- Das DWDS hat mit 15 Verlagen sowie mehreren öffentlichen und privaten Textgebern Nutzungsvereinbarungen über rechtebehaftete Texte abgeschlossen und kann z.B. Werke von Thomas und Heinrich Mann, Martin Walser, Heinrich Böll, Jürgen Habermas oder Victor Klemperer für die Internetrecherchen zur Verfügung stellen.
- Das Ergänzungskorpus umfasst über 1,5 Milliarden Textwörter in etwa 3,5 Millionen Dokumenten. Es ist weniger auf Ausgewogenheit als auf Umfang und Aktualität hin ausgelegt und besteht im wesentlichen aus Zeitungsquellen der Jahre 1980 - 2006. Alle Quellen sind bibliographisch referenzierbar, und bei der Aufbereitung wurde auf inhaltliche und qualitative Streuung geachtet.
Paradigmatische Relationen
Über 65.000 Synonyme, Ober- und Unterbegriffe wurden mit Hilfe automatischer Analyseprogramme aus den Definitionen des WDG extrahiert. Neben dem Nutzen als Synonymwörterbuch und Thesaurus kann man über diesen Informationstyp im WDG nicht mehr nur elektronisch blättern, sondern auch 'semantisch' navigieren. Beispielsweise kann man vom Stichwort Insekt direkt zu dessen Synonym Kerbtier springen, aber genauso zu allen untergeordneten Begriffen wie beispielsweise Ameise, Floh, Johanniskäfer oder Wasserläufer.
Kollokationen
Die im DWDS-Kernkorpus ermittelten statistischen Kollokationen werden grafisch dargestellt. Die Kollokationen basieren auf statistischen Assoziationsmaßen (Mutual_Information, Log-Likelihood und t-score):
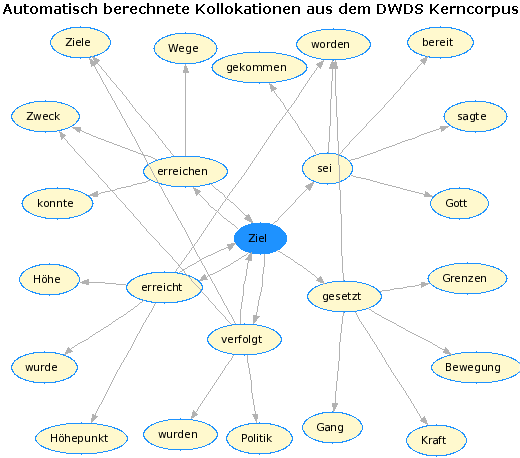
 Kollokationsgraph für "Ziel"
Kollokationsgraph für "Ziel"Öffentlich recherchierbare Korpora
In den Korpora des DWDS kann kostenlos recherchiert werden. Aufgrund der Nutzungsvereinbarungen mit den Rechtegebern ist für eine Vielzahl von Texten jedoch eine vorherige Registrierung notwendig. Mehr als 10.000 Benutzer sind im DWDS-Wortinformationssystem registriert.
- DWDS-Kernkorpus
- Korpus Berliner Zeitungen (Tagesspiegel, Berliner Zeitung) von 1994-2006 mit einem Gesamtumfang von 1,5 Millionen Dokumenten.
- Korpus jüdischer Periodika des 19. und 20. Jh. (Kooperation mit dem DFG-geförderten Projekt Compact Memory) mit einem Gesamtumfang von 25 Millionen Textwörtern.
- DDR-Korpus (9 Millionen Textwörter). Das DDR-Korpus umfasst Texte aus der Zeit von 1949 bis 1990, die in der DDR erschienen sind, bzw. von DDR-Schriftstellern geschrieben und in der Bundesrepublik veröffentlicht wurden. Das DDR-Corpus wird in Zusammenarbeit mit der Humboldt-Universität zu Berlin weiter ausgebaut.
- Korpus Gesprochene Sprache. Dieses umfasst Transkripte aus dem gesamten 20. Jh. Jahrhundert im Umfang von ca. 2,5 Millionen Textwörtern. Darunter befinden sich Redensammlungen u.a. von Kaiser Wilhelm, Hitler, Ulbricht und Honecker, Rundfunkansprachen von 1929-1944 (in Kooperation mit dem Deutschen Rundfunkarchiv wurden etwa 80 Stunden Tonmaterial transkribiert), ferner Auszüge aus österreichischen Parlamentsprotokollen und Bundestagsprotokollen sowie Auszüge aus dem literarischen Quartett
Weblinks
Wikimedia Foundation.