- Benford'sches Gesetz
-
Das benfordsche Gesetz, auch Newcomb-Benford’s Law (NBL) beschreibt eine Gesetzmäßigkeit in der Verteilung der Ziffernstrukturen von Zahlen in empirischen Datensätzen, zum Beispiel ihrer ersten Ziffern. Es lässt sich etwa in Datensätzen über Einwohnerzahlen von Städten, Geldbeträge in der Buchhaltung, Naturkonstanten etc. beobachten. Kurz gefasst besagt es:
- „Je niedriger der zahlenmäßige Wert einer Ziffernsequenz bestimmter Länge an einer bestimmten Stelle einer Zahl ist, umso wahrscheinlicher ist ihr Auftreten. Für die Anfangsziffern in Zahlen des Zehnersystems gilt zum Beispiel: Zahlen mit der Anfangsziffer ‚1‘ treten etwa 6,5-mal so häufig auf wie solche mit der Anfangsziffer ‚9‘.“
1881 wurde diese Gesetzmäßigkeit von dem Mathematiker Simon Newcomb entdeckt und im „American Journal of Mathematics“ publiziert. Er soll bemerkt haben, dass in den benutzten Büchern mit Logarithmentafeln, die Seiten mit Tabellen mit Eins als erster Ziffer deutlich schmutziger waren als die anderen Seiten, weil sie offenbar öfter benutzt worden seien. Die Abhandlung Newcombs blieb unbeachtet und war schon in Vergessenheit geraten, als der Physiker Frank Benford (1883–1948) diese Gesetzmäßigkeit wiederentdeckte und darüber 1938 neu publizierte. Seither war diese Gesetzmäßigkeit nach ihm benannt, in neuerer Zeit wird aber durch die Bezeichnung „Newcomb-Benford’s Law“ (NBL) dem eigentlichen Urheber wieder Rechnung getragen. Bis vor wenigen Jahren war diese Gesetzmäßigkeit nicht einmal allen Statistikern bekannt. Erst seit der US-amerikanische Mathematiker Theodore Hill versucht hat, die Benford-Verteilung zur Lösung praktischer Probleme nutzbar zu machen, ist ihr Bekanntheitsgrad gewachsen.
Benfordsche Verteilung
Ist d die erste Ziffer einer Dezimalzahl, so tritt sie nach dem benfordschen Gesetz in empirischen Datensätzen mit folgenden Wahrscheinlichkeiten p(d) auf:
- (1)
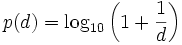
oder, anders geschrieben,
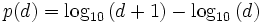 .
.
Wenn es sich nicht um eine Dezimalzahl, sondern um eine Zahl zur Basis B handelt, lässt sich p(d) berechnen durch
bzw.
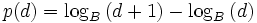 .
.
So ist für Binärzahlen die Wahrscheinlichkeit, dass die erste Ziffer eine 1 ist, immer eins.
Die Summe p(d) für alle möglichen Anfangszahlen d=1, …, B-1 ergibt, wie es sein muss, 1 (Teleskopsumme):
- (2)
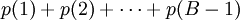
In einer ähnlichen Weise lassen sich auch Wahrscheinlichkeiten für das Auftreten der folgenden Ziffern angeben. Während die erste Ziffer d das logarithmische Intervall von log(d + 1) − log(d) belegt, tritt die zweite Ziffer e in allen entsprechenden Teilintervallen auf.
Lautet etwa die zweite Ziffer e=5, dann belegt sie die Intervalle: log(1,6)-log(1,5), log(2,6)-log(2,5), …, log(9,6)-log(9,5). Die Wahrscheinlichkeit p1(5), dass die zweite Ziffer eine 5 ist, lautet (bezogen auf die Gesamtintervall-Länge von log(10)-log(1)=1):
Allgemein gilt für die Wahrscheinlichkeit des Auftretens der Ziffer d zur Basis B an der n-ten Stelle (gezählt von 0):
- (3)
wobei
 die Gaußklammer bezeichnet.
die Gaußklammer bezeichnet.Beispiele: für die erste Ziffer, also n=0, folgt unmittelbar die Gleichung (1). Für n=1 (zweite Ziffer) läuft die Summation von Bn-1=1 bis Bn-1 = B-1 und man erhält die Reihe (2).
Gültigkeit des NBL
Ein Datensatz ist eine Benford-Variable (das heißt, das benfordsche Gesetz gilt für diesen Datensatz), wenn die Mantissen der Logarithmen des Datensatzes in den Grenzen von 0 bis 1 gleichverteilt sind; dies ist i.a. dann der Fall, wenn die Varianz innerhalb des Datensatzes einen bestimmten, von der Klasse der Verteilung, nach welcher die Logarithmen des Datensatzes verteilt sind, abhängigen Mindestwert nicht unterschreitet. Das unbedingte Postulat der Gleichverteilung der Mantissen der Logarithmen der Daten erlaubt es nicht, dass die Daten selbst gleichverteilt sind.
Bei den Fibonacci-Zahlen (jede Fibonacci-Zahl ist die Summe ihrer beiden Vorgänger) ergeben schon die Anfangsziffern der ersten 30 Zahlen eine Verteilung, die verblüffend nahe an einer Benford-Verteilung liegt. Dies gilt auch für ähnliche Folgen mit geänderten Anfangszahlen (z. B. die Lucas-Folgen.). Viele Zahlenfolgen gehorchen dem benfordschen Gesetz, viele andere gehorchen ihm aber nicht, sind also keine Benford-Variablen.
Warum folgen so viele reale Datensätze dem NBL?
Das NBL besagt, dass die Auftretenswahrscheinlichkeiten der Ziffernsequenzen in den Zahlen von realen Datensätzen (damit sind hier solche gemeint, die keinen Manipulationen unterlagen, genügend umfangreich sind und Zahlen in der Größenordnung von x bis mindestens 10000 x aufweisen. Daten also, welche einigermaßen weit verteilt (dispergiert sind) nicht gleichverteilt sind, sondern logarithmischen Gesetzen folgen. Das bedeutet, dass die Auftretenswahrscheinlichkeit einer Ziffernsequenz umso höher ist, je kleiner sie wertmäßig ist und je weiter links sie in der Zahl beginnt. Am häufigsten ist die Anfangssequenz ‚1‘ mit theoretisch 30,103 %. Das NBL beruht auf der Gleichverteilung der Mantissen der Logarithmen der Zahlenwerte des Datensatzes. Der Grund für das erstaunlich häufige Gelten des NBL liegt an dem Umstand, dass viele reale Datensätze log-normalverteilt sind, nicht also die Häufigkeiten der Daten selbst, sondern die Häufigkeiten der Logarithmen dieser Daten einer Normalverteilung folgen. Bei genügend breiter Dispersion der normalverteilten Logarithmen (wenn die Standardabweichung größer/gleich etwa 0.74 ist) kommt es dazu, dass die Mantissen der Logarithmen stabil einer Gleichverteilung folgen. Ist die Standardabweichung allerdings kleiner, sind auch die Mantissen normalverteilt, und das NBL gilt nicht mehr, zumindest nicht mehr in der dargestellten einfachen Form. Ist die Standardabweichung kleiner als 0.74, kommt es zu dem in der Statistik nicht allzu häufigen Effekt, dass sogar der jeweilige Mittelwert der Normalverteilung der Logarithmen die Auftretenshäufigkeit der Ziffernsequenzen beeinflusst. Geht man einerseits vom NBL in der heutigen Form aus, so existieren zahlreiche Datensätze, die dem NBL nicht genügen. Andererseits gibt es bereits eine Formulierung des NBL in der Form, dass ihm sämtliche Datensätze genügen. Die Formulierung des „allgemeinen NBL“ ist wesentlich komplexer und enthält die bekannte Form des NBL als Grenzverteilung. Ihre Darstellung würde den Rahmen dieser Seite sprengen.
Skaleninvarianz
Mit einer Konstanten multiplizierte Datensätze mit Newcomb-Benford-verteilten Anfangsziffern sind wiederum Benford-verteilt. Eine Multiplikation der Daten mit einer Konstanten entspricht der Addition einer Konstanten zu den Logarithmen. Sofern die Daten hinreichend weit verteilt sind, ändert sich dadurch die Verteilung der Mantissen nicht.
Diese Eigenschaft erklärt unmittelbar, warum in Steuererklärungen, Bilanzen, etc., oder allgemein bei Datensätzen, deren Zahlen Geldbeträge darstellen das Newcomb-Benfordsche Gesetz gilt. Wenn es überhaupt eine universell gültige Verteilung der Anfangsziffern in solchen Datensätzen gibt, dann muss diese Verteilung unabhängig davon sein, in welcher Währung die Daten angegeben werden, und die universelle Verteilung darf sich auch durch Inflation nicht verändern. Beides bedeutet, dass die Verteilung skaleninvariant sein muss. Da die Newcomb-Benfordsche Verteilung die einzige ist, die diese Bedingung erfüllt, muss es sich folglich um diese handeln.
Baseninvarianz
Ein Datensatz, der zu einer Basis B1 dem benfordschen Gesetz genügt, genügt diesem auch zur Basis B2. Konkreter gesagt, ein dekadischer Datensatz, der das benfordsche Gesetz erfüllt, erfüllt das benfordsche Gesetz auch dann, wenn die dekadischen Zahlen in ein anderes Zahlensystem (z. B. ins binäre, ins oktale oder ins hexadezimale) umgerechnet werden.
Anschauliche Darstellung
Benfords Gesetz besagt in seiner einfachsten Konsequenz, dass die führenden Ziffern n (n = 1…9) mit folgenden Wahrscheinlichkeiten erscheinen: log10(n+1) - log10(n), oder
Führende Ziffer Wahrscheinlichkeit 1 30,1 % 2 17,6 % 3 12,5 % 4 9,7 % 5 7,9 % 6 6,7 % 7 5,8 % 8 5,1 % 9 4,6 % Anwendungen
Entsprechen reale Datensätze trotz Erfüllung der parametrischen Anforderungen dem benfordschen Gesetz insofern nicht, als die Anzahl des Auftretens einer bestimmten Ziffer signifikant von der durch das benfordsche Gesetz angegebenen Erwartung abweicht, dann wird ein Prüfer jene Datensätze, die mit dieser Ziffer beginnen, einer tiefergehenden Analyse unterziehen, um die Ursache(n) für diese Abweichungen zu finden. Dieses Schnellverfahren kann zu tieferen Erkenntnissen über Besonderheiten des untersuchten Datensatzes bzw. zur Aufdeckung von Manipulationen bei der Datenerstellung führen.
Beispiel
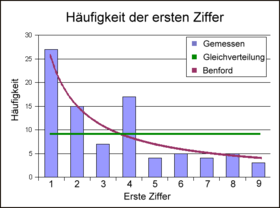 Verteilung der Anfangsziffern einer Tabelle mit 87 Zahlen (siehe Text).
Verteilung der Anfangsziffern einer Tabelle mit 87 Zahlen (siehe Text).Die Tabelle fasst die Ergebnisse zusammen. Die Spalte 1. Ziffer sagt aus, wie oft die Ziffer an erster Stelle beobachtet wird, die Spalte Benford, wie oft sie nach der Benford-Verteilung erwartet wird. Gleiches gilt für die zweite Ziffer unter Spalte 2. Ziffer. Danach tritt die Ziffer 1 27 Mal an erster Stelle auf, erwartet war 26,19 Mal. An zweiter Stelle steht die 4 5 Mal, nach Benford sollte sie 8,73 Mal auftreten.
Mit abnehmendem Stellenwert der Ziffer nähert sich die oben angegebene Benford-Verteilung immer mehr der Gleichverteilung der Ziffern.
Ziffer 1. Ziffer Benford 2. Ziffer Benford 0 - 9 10,41 1 27 26,19 17 9,91 2 15 15,32 9 9,47 3 7 10,87 11 9,08 4 17 8,43 5 8,73 5 4 6,89 9 8,41 6 5 5,82 7 8,12 7 4 5,05 8 7,86 8 5 4,45 7 7,62 9 3 3,98 5 7,39 Summe 87 87 In der Wirtschaft
Das Benfordsche Gesetz findet Anwendung bei der Aufdeckung von Betrug bei der Bilanzerstellung, der Fälschung in Abrechnungen, generell zum raschen Auffinden eklatanter Unregelmäßigkeiten im Rechnungswesen. Mit Hilfe des benfordschen Gesetzes wurde das bemerkenswert „kreative“ Rechnungswesen bei Enron und Worldcom aufgedeckt, durch welches das Management die Anleger um ihre Einlagen betrogen hatte (→ Wirtschaftskriminalität). Heute benutzen Wirtschaftsprüfer und Steuerfahnder Methoden, die auf dem benfordschen Gesetz beruhen. Diese Methoden stellen einen wichtigen Teil der mathematisch-statistischen Methoden dar, die seit mehreren Jahren zur Aufdeckung von Bilanzfälschung, Steuer- und Investorenbetrug und allgemein Datenbetrug in Verwendung sind. Es konnte weiter gezeigt werden, dass auch die führenden Ziffern der Marktpreise dem benfordschen Gesetz folgen (el Sehity, Hoelzl und Kirchler, 2005).
In der Forschung
Das benfordsche Gesetz kann auch bei der Aufdeckung von Datenfälschung in der Wissenschaft hilfreich sein. Schließlich waren es Datensätze aus den Naturwissenschaften, die zum benfordschen Gesetz führten. Dessen ungeachtet ist das benfordsche Gesetz nicht allen Wissenschaftlern bekannt, wie Wissenschaftsskandale mit gewisser Regelmäßigkeit belegen.
Größe der Städte in Deutschland
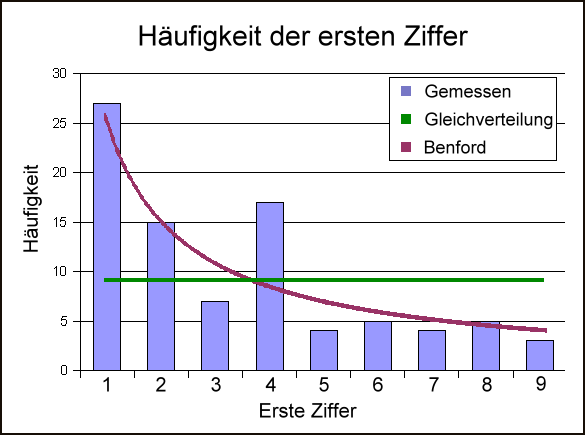
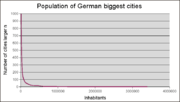 Verteilung der Größe deutscher Großstädte
Verteilung der Größe deutscher GroßstädteDie rechte Abbildung zeigt die Größenverteilung deutscher Städte. Der Grafik hinterlegt sind die Einwohnerzahlen der 998 größten Städte.[1] Eine Benford-Analyse liefert folgende Häufigkeiten der Anfangsziffern:
Ziffer Gemessen Erwartet 1 340 300 2 320 176 3 133 125 4 87 97 5 50 80 6 24 67 7 20 58 8 12 51 9 12 46 Die Häufigkeit der Ziffern 3 und 4 entsprechen der Erwartung. Hingegen tritt die Zahl 1 vermehrt auf. Besonders ausgeprägt ist die Abweichung der Ziffer 2, auf Kosten der nur selten an erster Stelle beobachteten Ziffern 7, 8 und 9.
Dieses Beispiel zeigt wiederum, dass Datensätze bestimmte Voraussetzungen erfüllen müssen, um dem NBL zu genügen; der vorliegende Datensatz tut dies nicht. Kurioserweise gehören sogar etwa 50 % der Beispiele, die Benford in seiner Publikation als Belege für das NBL anführte, zu der Klasse von Datensätzen, die keine Benford-verteilten Anfangsziffern, sondern eine höchstens im Groben ähnliche Verteilung der Anfangsziffern aufweisen.
Signifikanz
Wie groß die Abweichungen der beobachteten Verteilung von der theoretisch zu erwartenden Verteilung mindestens sein müssen, damit ein begründeter Verdacht auf Manipulation als erhärtet angesehen werden kann, wird mit Hilfe mathematisch-statistischer Methoden (z. B. dem Chi-Quadrat-Test oder dem Kolmogorow-Smirnow-Test, „KS-Test“) bestimmt. Für den χ2-Test sollte beim Test von überzufälligen Abweichungen bei der Anfangsziffer eine Stichprobe ab 109 Zahlen genügen (
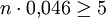 ist erfüllt für alle
ist erfüllt für alle 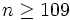 ). Sind die Stichproben viel kleiner, sind die Ergebnisse des Chi-Quadrat-Tests anfechtbar und der KS-Test gegebenenfalls zu tolerant. In einem solchen Fall kann z. B. auf einen sehr aufwändigen, aber exakten Test auf Basis der Multinomialverteilung zurückgegriffen werden. Außerdem müssen die Daten des Datensatzes voneinander statistisch unabhängig sein. (Daher können Zahlen z. B. der Fibonacci-Folge nicht mit dem Chi-Quadrat-Anpassungs-Test auf Signifikanz getestet werden, da das sich ergebende Resultat unzuverlässig wird.)
). Sind die Stichproben viel kleiner, sind die Ergebnisse des Chi-Quadrat-Tests anfechtbar und der KS-Test gegebenenfalls zu tolerant. In einem solchen Fall kann z. B. auf einen sehr aufwändigen, aber exakten Test auf Basis der Multinomialverteilung zurückgegriffen werden. Außerdem müssen die Daten des Datensatzes voneinander statistisch unabhängig sein. (Daher können Zahlen z. B. der Fibonacci-Folge nicht mit dem Chi-Quadrat-Anpassungs-Test auf Signifikanz getestet werden, da das sich ergebende Resultat unzuverlässig wird.)Dass sich gerade Saldenlisten, Rechnungslisten und ähnliche Aufstellungen gemäß dem benfordschen Gesetz verhalten, liegt an dem Umstand, dass es sich bei der Mehrzahl solcher Zahlenreihen um Sammlungen von Zahlen handelt, die die unterschiedlichsten arithmetischen Prozesse durchlaufen haben und sich daher wie Quasi-Zufallszahlen verhalten. Lässt man den geschäftlichen und buchungstechnischen Prozessen freien Lauf, dann wirken ab einer gewissen Geschäftsgröße die Gesetze des Zufalls und es gilt mithin auch das benfordsche Gesetz. Wird allerdings im Verlauf einer Rechnungsperiode konsequent Einfluss auf diese Zahlen genommen, indem man häufig welche schönt, bestimmte Zahlen verschwinden lässt oder welche hinzu erfindet oder wegen gegebener Kompetenzbeschränkungen sogar Prozesse manipuliert, dann wird der Zufall merklich gestört. Diese Störungen manifestieren sich in signifikanten Abweichungen von der theoretisch zu erwartenden Ziffernverteilung.
In der Praxis wird häufig festgestellt, dass die herkömmlichen Signifikanztests bei Benford-Analysen nicht ganz zuverlässig sind. Zudem sind bisweilen die Daten eines Datensatzes nicht völlig unabhängig voneinander, weshalb man für solche Datensätze z. B. den Chi-Quadrat-Test nicht verwenden darf. An der Entwicklung von an das NBL besser angepassten Signifikanztests wird gearbeitet.
Beispiel: Wenn ein Angestellter Bestellungen bis zu 1.000 EUR ohne Genehmigung der Geschäftsleitung durchführen darf und er bei Vorliegen von Angeboten höher als 1.000 EUR die Bestellungen häufig auf mehrere kleinere Posten aufteilt, um sich die Mühen der Genehmigung zu ersparen, dann finden sich in der Benford-Verteilung der Bestellbeträge signifikante Abweichungen von der theoretischen Erwartung.
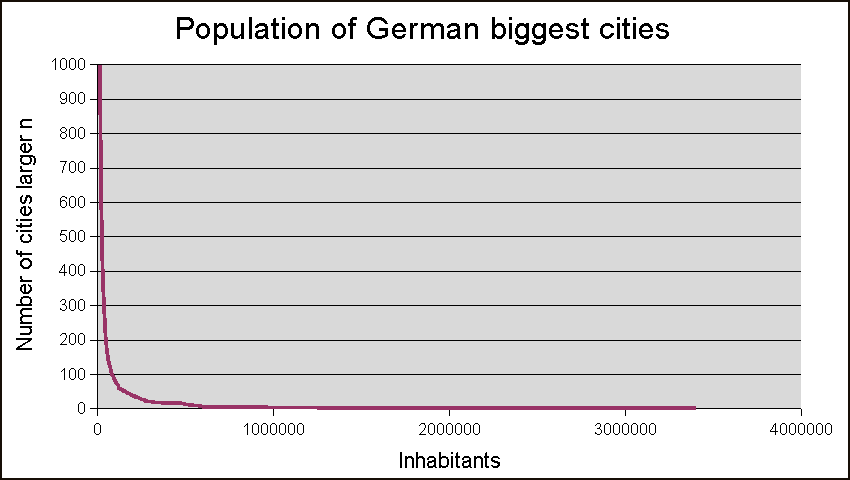
 Signifikanztest auf Abweichung von der Benford-Verteilung mit Hilfe des Chi-Quadrat-Tests
Signifikanztest auf Abweichung von der Benford-Verteilung mit Hilfe des Chi-Quadrat-TestsDieses Beispiel zeigt aber auch, dass statistische Methoden einzelne Unregelmäßigkeiten nicht aufdecken können. Eine gewisse Konsequenz der Manipulationen ist erforderlich. Je größer die Stichprobe ist, umso empfindlicher reagiert ein Signifikanztest im Allgemeinen auf Manipulationen.
Test auf signifikante Abweichungen
Benford-Analysen werden für die einfachsten Analysen der mathematischen Statistik gehalten. Das nachstehende Beispiel ist das Ergebnis der Auszählung der Anfangsziffern einer Stichprobe von 109 Summen aus einer Aufstellung. Die realen (beobachteten) Auszählungsergebnisse werden mit den bei 109 Anfangsziffern zu erwartenden Auszählungsergebnissen verglichen und mittels Chi-Quadrat-Test dahingehend untersucht, ob die gefundenen Abweichungen zufällig sein können oder durch Zufall allein nicht mehr zu erklären sind. Als Entscheidungskriterium wird in diesem Beispiel angenommen, dass von Überzufälligkeit ausgegangen wird, sobald die beobachtete Verteilung der Anfangsziffern zu jenen 4,99…9 % gehört, die diese oder noch höhere Abweichungen aufweisen (statistischer Test). Da in unserem Beispiel 52 % aller Verteilungen diese oder höhere Abweichungen aufweisen, wird ein Prüfer die Hypothese, dass die Abweichungen durch Zufall entstanden sind, nicht verwerfen.
Tiefergehende Benford-Analysen
Liegen sehr lange Listen mit mehreren tausend Zahlen vor, ist ein Benford-Test nicht nur mit der Anfangsziffer durchführbar. Eine solche Datenfülle erlaubt es, auch die 2., die 3., die Summe 1.+ 2., eventuell sogar die Summe 1.+ 2.+ 3. Ziffer simultan zu überprüfen (für diese sollte man allerdings mindestens 11.500 Zahlen haben, da ansonsten der Chi-Quadrat-Test unsichere Ergebnisse bringen könnte). Für diese Prüfungen existieren ebenfalls Benford-Verteilungen, wenngleich sie auch etwas umfangreicher sind. So z. B. beträgt die theoretische Erwartung für das Erscheinen der Anfangsziffern 123… 0,35166 %, wohingegen nur noch 0,13508 % aller Zahlen die Anfangsziffern 321… aufweisen.
Stets gilt die Regel, dass die Ziffern umso mehr einer Gleichverteilung folgen, je kleiner ihr Stellenwert ist. Cent-Beträge folgen nahezu exakt einer Gleichverteilung, wodurch sich bei Cent-Beträgen der logarithmische Ansatz im Allgemeinen erübrigt. Bei sehr kleinen Währungen werden Tests auf Gleichverteilung der Scheidemünzenbeträge (z. B. Kopeke-RUS, Heller-CZ, Fillér-H, Lipa-HR) unscharf, da in der Praxis sehr häufig gerundet wird. Große Währungen (US-Dollar, Pfund-Sterling, Euro) erlauben solche Tests aber zumeist schon.
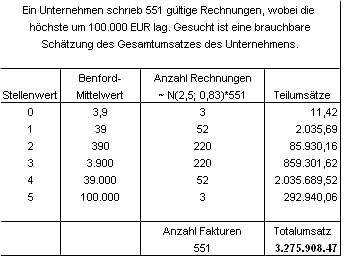
Schätzung und Planung von Unternehmensumsätzen
Das benfordsche Gesetz lässt sich auch zur Schätzung von Umsatzziffern von Unternehmen heranziehen. Für die Größenordnungen der Fakturenbeträge wird angenommen, dass sie annähernd einer Normalverteilung folgen, die Anfangsziffern der Fakturenbeträge der Benford-Verteilung, wobei der Erwartungswert der Anfangsziffer etwa 3,91 (siehe oben: Ableitung des Erwartungswerts der Benford-Verteilung) ist. Mit der Kenntnis des höchsten Fakturenbetrages und der Anzahl der gültigen Fakturen, aus welchen sich der zu schätzende Umsatz zusammensetzt, ist eine brauchbare Schätzung des Umsatzes möglich, wie nachstehendes Beispiel aus der Praxis zeigt. Der Stellenwert in der Tabelle bezeichnet die Ziffer vor dem Komma des Logarithmus. Der tatsächliche Umsatz lag bei 3,2 Mio Währungseinheiten. So nahe am tatsächlichen Ergebnis liegt man bei Umsatzschätzungen allerdings nicht immer. Wenn die Annahme der Normalverteilung für die Größenordnungen nicht zutrifft, muss man eine Schätzverteilung wählen, die der realen eher gleicht. Zumeist folgen die Größenordnungen der Fakturenbeträge dann einer Logarithmischen Normalverteilung.
 Schätzung Gesamtumsatz
Schätzung GesamtumsatzZwar wird die tatsächliche Verteilung der Fakturenbeträge immer nur zufällig mit jener der Schätzung übereinstimmen, die Summe aller Schätzfehler je Stellenwert kompensiert sich jedoch fast immer auf einen eher kleinen Betrag.
Auch im Rahmen der Planung von Unternehmensumsätzen kann dieses Verfahren zur Überprüfung der Plausibilität von Planumsätzen, die zumeist als Ergebnis von Schätzungen und Hochrechnungen von Erfahrungswerten verkaufsorientierter Abteilungen entstanden sind, eingesetzt werden, indem man eruiert, wie viele Fakturen zur Erreichung des angegebenen Umsatzes erwartet werden und wie hoch der höchste Fakturenbetrag sein wird. Oft zeigt diese Analyse, dass auf solche Schätzwerte, die der Planung zugrunde gelegt werden, kein all zu großer Verlass ist. Die Benfordanalyse gibt der Verkaufsabteilung dann das Feedback zur realitätsbezogenen Korrektur ihrer Erwartungen.
Unterstellt man, dass die Logarithmen der einzelnen Umsätze gleichverteilt sind, so sind die Umsätze quasi „logarithmisch gleichverteilt“. Die Dichtefunktion der Umsätze hat dann ein Histogramm, das bei geeigneter Klasseneinteilung der Verteilung der Ziffernsequenzen (z. B. neun Klassen, verglichen mit First Digit) der Benford-Verteilung sehr ähnlich sieht.
Erzeugung Benford-verteilter Anfangsziffern
Die Erzeugung von praktisch zufälligen Zahlen mit Benford-verteilten Anfangsziffern ist mit dem PC recht einfach möglich.
Gleichverteilte Zahlen
Die Funktion y = 10k erzeugt Zahlen mit Benford-verteilten Anfangsziffern für k = r + s. Dabei ist r eine zufällige gleichverteilte positive ganze Zahl aus einem festen Intervall, und s ist eine gleichverteilte Zufallszahl zwischen 0 und 1.
Normalverteilte Zahlen
Die Funktion
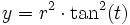 erzeugt für
erzeugt für 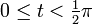 , mit t als gleichverteilter Zufallsvariablen, Zahlen mit etwa normalverteilten Größenordnungen von y und Benford-verteilten Anfangsziffern. Für praktische Zwecke sollte r relativ hoch gewählt werden (r > 1000). Ist r < 1000, erkennt man mit sinkendem r, dass die Verteilung der Zahlen der Form einer Lognormalverteilung ähnelt. Ist r < 50, sind die erzeugten Anfangsziffern der Zahlen im Allgemeinen nicht mehr Benford-verteilt. Für Anwendungen in der Praxis ist die breite Streuung der Größenordnungen von y, die das Quadrat der Tangensfunktion – noch dazu bei großen r – erzeugt, in vielen Fällen nicht optimal.
, mit t als gleichverteilter Zufallsvariablen, Zahlen mit etwa normalverteilten Größenordnungen von y und Benford-verteilten Anfangsziffern. Für praktische Zwecke sollte r relativ hoch gewählt werden (r > 1000). Ist r < 1000, erkennt man mit sinkendem r, dass die Verteilung der Zahlen der Form einer Lognormalverteilung ähnelt. Ist r < 50, sind die erzeugten Anfangsziffern der Zahlen im Allgemeinen nicht mehr Benford-verteilt. Für Anwendungen in der Praxis ist die breite Streuung der Größenordnungen von y, die das Quadrat der Tangensfunktion – noch dazu bei großen r – erzeugt, in vielen Fällen nicht optimal.Ein Spiel
A und B wetten auf die Anfangsziffer von Zahlen aus einer Tabelle, die als Benford-verteilt angenommen werden (z. B. eine Produktionsstatistik eines Landes). A und B vereinbaren, dass die Wette stets für die Anfangsziffer der letzten Zahl auf der zufällig aufgeschlagenen Seite mit ungerader Seitenzahl gilt. Wenn die so ermittelte Zahl die Anfangsziffern 1, 2 oder 3 hat, gewinnt A einen Euro. Wenn eine andere Anfangsziffer (also 4, 5, 6, 7, 8 oder 9) vorliegt, gewinnt B. Wie sind die Gewinnwahrscheinlichkeiten für A und für B?
Antwort: Die Gewinnwahrscheinlichkeit für A beträgt ca. 30 %+18 %+12 % = etwa 60 %, jene für B nur etwa 40 %.
Einzelnachweis
Literatur
- Benford, F. (1938): The Law of Anomalous Numbers. Proc. Amer. Phil. Soc. 78, S. 551–572.
- Newcomb, S. (1881): Note on the Frequency of the Use of Digits in Natural Numbers. Amer. J. Math. 4, S. 39–40.
- Nigrini, M. J. (1992): The Detection of Income Tax Evasion Through an Analysis of Digital Frequencies. Dissertation, Cincinnati, OH: University of Cincinnati.
- Ian Stewart (1994): Das Gesetz der ersten Ziffer. In: Spektrum der Wissenschaft, April 1994, S. 16 ff.
- Rafeld, H. (2003): Digitale Ziffernanalyse mit Benford's Law zur Deliktrevision doloser Handlungen, Diplomarbeit, Berufsakademie Ravensburg, 2003.
- Posch, P. N. (2005): Ziffernanalyse in Theorie und Praxis – Testverfahren zur Fälschungsaufspürung mit Benfords Gesetz – ISBN 3-8322-4492-1.
- Tarek el Sehity, Erik Hoelzl and Erich Kirchler (December 2005): Price developments after a nominal shock: Benford’s Law and psychological pricing after the euro introduction. International Journal of Research in Marketing 22 (4): 471–480. DOI:10.1016/j.ijresmar.2005.09.002.
- Günnel, S. / Tödter, K.-H. (2007): Does Benford’s law hold in economic research and forecasting? In: Deutsche Bundesbank Discussion Paper Series 1: Economic Studies No 32/2007.
- Rafeld, H. / Then Bergh, F. (2007): Digitale Ziffernanalyse in deutschen Rechnungslegungsdaten, in: Zeitschrift Interne Revision, 42. Jahrgang, 01/2007, S. 26-33.
Weblinks
- Ein didaktisch aufbereiter Artikel zu Benfords Gesetz
- Artikel über Wahrscheinlichkeiten, ab S. 11 zum benfordschen Gesetz
- Benford’s Law (englisch)
- Berliner Zeitung 15. Juni 2007: Alle Welt liebt die Eins (Artikel von Brigitte Röthlein)
Diskrete univariate VerteilungenDiskrete univariate Verteilungen für endliche Mengen:
Benford | Bernoulli-Verteilung | Binomialverteilung | Kategoriale | Hypergeometrische Verteilung | Rademacher | Zipfsche | Zipf-MandelbrotDiskrete univariate Verteilungen für unendliche Mengen:
Boltzmann | Conway-Maxwell-Poisson | Negative Binomialverteilung | Erweiterte negative Binomial | Compound Poisson | Diskret uniform | Discrete phase-type | Gauss-Kuzmin | Geometrische | Logarithmische | Parabolisch-fraktale | Poisson | Skellam | Yule-Simon | ZetaKontinuierliche univariate VerteilungenKontinuierliche univariate Verteilungen mit kompaktem Intervall:
Beta | Kumaraswamy | Raised Cosine | Dreiecks | U-quadratisch | Stetige Gleichverteilung | Wigner-HalbkreisKontinuierliche univariate Verteilungen mit halboffenem Intervall:
Beta prime | Bose-Einstein | Burr | Chi-Quadrat | Coxian | Erlang | Exponential | F | Fermi-Dirac | Folded Normal | Fréchet | Gamma | Extremwert | Verallgemeinerte inverse Gausssche | Halblogistische | Halbnormale | Hotellings T-Quadrat | hyper-exponentiale | hypoexponential | Inverse Chi-Quadrat | Scale Inverse Chi-Quadrat | Inverse Normal | Inverse Gamma | Lévy | Log-normal | Log-logistische | Maxwell-Boltzmann | Maxwell speed | Nakagami | nichtzentrierte Chi-Quadrat | Pareto | Phase-type | Rayleigh | relativistische Breit-Wigner | Rice | Rosin-Rammler | Shifted Gompertz | Truncated Normal | Type-2-Gumbel | Weibull | Wilks’ lambdaKontinuierliche univariate Verteilungen mit unbeschränktem Intervall:
Cauchy | Extremwert | Exponential Power | Fisher’s z | Fisher-Tippett (Gumbel) | Generalized Hyperbolic | Hyperbolic Secant | Landau | Laplace | Alpha stabile | logistisch | Normal (Gauss) | Normal-inverse Gausssche | Skew normal | Studentsche t | Type-1 Gumbel | Variance-Gamma | VoigtMultivariate VerteilungenDiskrete multivariate Verteilungen:
Ewen's | Multinomial | Dirichlet MultinomialKontinuierliche multivariate Verteilungen:
Dirichlet | Generalized Dirichlet | Multivariate Normal | Multivariate Student | Normalskalierte inverse Gamma | Normal-GammaMultivariate Matrixverteilungen:
Inverse-Wishart | Matrix Normal | Wishart
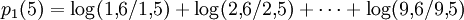

Wikimedia Foundation.