- Kachelverwaltung
-
Als Paging (vgl. engl. page Speicherseite) oder deutsch Kachelverwaltung bezeichnet man die Methode der Arbeitsspeicher-Verwaltung per Seitenadressierung durch Betriebssysteme. Dabei wird häufig aus Effizienzgründen die sogenannte Memory Management Unit des Prozessors eingesetzt, sofern der Prozessor eine solche bereitstellt.
Gelegentlich wird der Begriff Paging synonym mit der gesamten virtuellen Speicherverwaltung gebraucht. Dieser Sprachgebrauch ist jedoch unpräzise, da das Paging nur einen - wenn auch zentralen - Aspekt der virtuellen Speicherverwaltung ausmacht.
Zu unterscheiden ist das Paging jedoch deutlich vom Swapping, da letzteres nicht nur einzelne Speicherseiten, sondern praktisch vollständige Prozesse auslagert. Das Paging ist trotz einer häufig unpräzisen Bezeichnung der Auslagerungsdatei als Swap-Datei heute das bei modernen Betriebssystemen vorherrschende Verfahren zur Speicherverwaltung von Prozessen.
Inhaltsverzeichnis
Zweck des Pagings
Das wesentliche Problem, das durch Paging gelöst wird, ist die externe Fragmentierung. Darunter versteht man, dass jedem Prozess vom Betriebssystem ein Adressraum zugeordnet wird. Würde es sich hierbei um einen zusammenhängenden Hauptspeicherbereich handeln, so entstünden im Laufe der Zeit zwischen den Adressräumen der Prozesse Lücken, da neue Prozesse zumeist nicht dieselbe Speichermenge benötigen, wie beendete Prozesse. Somit könnten diese Speicherbereiche nicht exakt ersetzt werden. Eine regelmäßige Neuordnung des Speichers (Kompaktifizierung genannt) wäre zwar möglich, aber sehr aufwändig. In erster Näherung kann man das Problem lösen, indem man die Prozesse segmentiert, d. h. nicht einen einzigen zusammenhängenden Adressraum, sondern mehrere kleinere Segmente an die Prozesse vergibt. Dies würde die externe Fragmentierung jedoch nicht vollständig beseitigen. Das Paging hingegen beseitigt die externe Fragmentierung gänzlich.
Des Weiteren benutzen die meisten heutigen Betriebssysteme virtuelle Adressräume, so dass jedem Prozess ein eigener, gegen andere Prozesse und das Betriebssystem abgegrenzter, logischer Adressraum zur Verfügung steht. Diese sogenannte virtuelle Speicherverwaltung benutzt Paging, um nur die vom Programm benötigten Teile eines virtuellen Adressraums (angenähert mit Vielfachen der verwendeten Seitengröße) mit physischem Speicher zu hinterlegen.
Funktionsweise
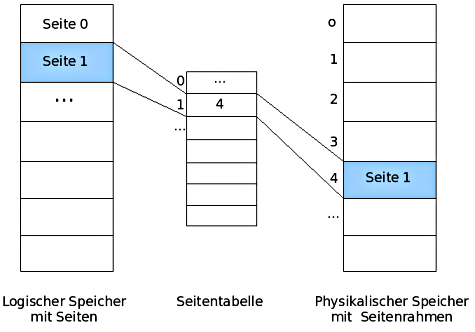
Beim Paging werden logischer Speicher und physischer Speicher unterschieden. Der logische Speicher beschreibt die Organisation des Hauptspeichers aus Programmsicht. Der physische Speicher ist durch den verfügbaren Hauptspeicher sowie ggf. zusätzlichen ausgelagerten Speicher (z.B. in Form einer Auslagerungsdatei) gegeben. Man unterteilt den logischen Speicher in gleich große Stücke, die man als Seiten (engl. „pages“) bezeichnet. Auch der physische Speicher ist derart unterteilt - hier nennt man die einzelnen Stücke Seitenrahmen oder auch Kacheln (engl. „frames“). Eine Seite und der zugehörige Seitenrahmen haben also die gleiche Größe. Um Seiten und Seitenrahmen einander zuordnen zu können, wird eine Seitentabelle verwendet. Dementsprechend existiert für jeden Prozess eine derartige Seitentabelle. Nun wird klar, warum hier keine externe Fragmentierung im Hauptspeicher mehr auftreten kann: Zwar ist der logische Speicher weiterhin zusammenhängend, im physischen Speicher können die benachbarten Seiten jedoch in weit von einander entfernt liegenden Seitenrahmen abgelegt werden. Die Reihenfolge der Seitenrahmen ist damit beliebig und somit ist es nicht mehr sinnvoll, von Lücken und damit von externer Fragmentierung zu sprechen.
Adressberechnung beim Paging
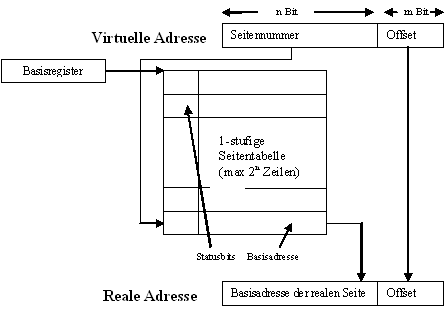
In der Terminologie der obigen Grafik entspricht eine logische Speicheradresse der virtuellen Adresse. Der physische Speicher heißt hier reale Adresse. Man entnimmt der Grafik, dass sich die physische Speicheradresse sehr einfach aus zwei Teilen berechnet: Der erste Teil wird der Seitentabelle entnommen, der zweite Teil der virtuellen Adresse. Dabei handelt es sich um zwei Binärzahlen. Werden diese konkateniert, so ergibt sich eine neue Binärzahl, die genau die physische Speicheradresse ist. Derartige Berechnungen werden von der Memory Management Unit ausgeführt.
Ein Puffer kann hier einen Teil der Adressabbildung bereithalten, so dass die Zugriffszeiten optimiert werden können. Dieser Puffer heißt Translation Lookaside Buffer.
Beispiele
Die Adresslänge beträgt 16 Bit, wobei die unteren 8 Bit der Offset und die oberen 8 Bit die Seitennummern sind.
associative mapping
Bei dieser Methode erfolgt der Zugriff assoziativ (associative mapping).
Seitentabelle:
Seite Seitenrahmen 0x11 0x33 0x01 0x17 0x17 0x20 0x42 0x08 0x05 0x05 Zu übersetzende Adressen:
virtuelle Adresse physische Adresse Bemerkung 0x083A ungültig da die Seite 0x08 nicht in der Seitentabelle vorhanden ist 0x01FF 0x17FF Seite 0x01 befindet sich in Seitenrahmen 0x17, also werden die oberen 8 bit der virtuellen Adresse durch 0x17 ersetzt 0x0505 0x0505 Seite 0x05 befindet sich in Seitenrahmen 0x05, also werden die oberen 8 bit der virtuellen Adresse durch 0x05 ersetzt 0x063A ungültig da die Seite 0x06 nicht in der Seitentabelle vorhanden ist Zur Berechnung der physischen Adresse wird die zu übersetzende virtuelle Adresse in Seitennummer und Offset aufgeteilt. Die Seitennummer wird durch die in der Seitentabelle eingetragenen Rahmennummer ersetzt, der Offset bleibt erhalten.
direct mapping
Der Zugriff erfolgt direkt (direct mapping).
Segmenttabelle:
Segment Basisadresse Länge 0 0x1830 0x020 1 0x0810 0x0FF 2 0x42AC 0x100 3 0x0400 0x004 4 0x01FE 0x0F0 5 0x0010 0x030 6 0x3302 0x050 7 0x4220 0x010 Zu übersetzende Adressen:
virtuelle Adresse physische Adresse Bemerkung 0x1832 ungültig da Segment 18 in der Segmenttabelle nicht vorhanden ist 0x0402 0x0200 Basisadresse von Segment 4 plus untere 8 bit der virtuellen Adresse Hinweis zur Berechnung: 0x01FE (Segment 4 (0x0402)) + 02 (0x0402) = 0x0200
0x0305 ungültig 0x0400+0x0005 = 0x0405, dies liegt oberhalb der Rahmengrenze, 0x0400+0x004=0x0404 Zur Berechnung der physischen Adresse wird die zu übersetzende virtuelle Adresse in Segmentnummer und Offset aufgeteilt. Mithilfe der Segmenttabelle wird die zu diesem Segment gehörende Basisadresse ermittelt. Zur Basisadresse wird der Offset addiert, wodurch sich die physische Adresse ergibt. Die Rahmengrenze erhält man, indem man Basisadresse und Länge des Segments addiert. Sollte die physische Adresse größer oder gleich der Rahmengrenze sein, so ist die Adresse ungültig.
Im Beispiel gilt: 0x0400 (Basisadresse) + 0x0004 (Länge) = 0x0404 (Ende des Speicherbereichs). Die ermittelte physische Adresse 0x0405 liegt außerhalb des Rahmens und ist damit ungültig.
Demand Paging
Wie oben schon erwähnt, wird der Paging-Mechanismus auch zur virtuellen Speicherverwaltung ausgenutzt. Erfolgt nun ein Zugriff auf eine Speicherseite, die nicht im Hauptspeicher, sondern im Auslagerungsspeicher abliegt, so wird zunächst ein Seitenfehler (engl. page fault) ausgelöst. Dieser führt zu einer Exception und schließlich zum Laden der Seite in den Hauptspeicher. Diese Technik bezeichnet man als Demand Paging.
Thrashing und Working Set
Diese Technik des Pagings hat jedoch ihre Grenzen. Wenn in einem Rechnersystem zu viele Seitenfehler auftreten, dann ist es überwiegend mit dem Nachladen und Auslagern von Seiten beschäftigt. Der Prozessor verharrt die meiste Zeit im Wartezustand, die verfügbare Rechenleistung sinkt dramatisch. Da der Rechner in diesem Betriebszustand gewissermaßen nur leeres Stroh drischt, bezeichnet man ihn auch als Thrashing (Dreschen).
Um Thrashing zu vermeiden, darf der Arbeitsspeicher im Verhältnis zum Auslagerungsspeicher nicht zu klein sein. Zu jedem gegebenen Zeitpunkt sollte mindestens einer der Prozesse, die das System zu verarbeiten hat, vom Prozessor bearbeitet werden können, das heißt: Seine Daten oder Programmbefehle, die aktuell bearbeitet werden, befinden sich im Arbeitsspeicher. In diesem Betriebszustand wartet der Prozessor nicht auf das Nachladen von Seiten, sondern arbeitet an einem Prozess, während parallel für andere Prozesse Seiten nachgeladen werden.
Entscheidend sind dabei folgende Größen:
- t: Die Zeit, die der Prozessor braucht, um auf eine Speicherstelle zuzugreifen
- T: Die Zeit, die benötigt wird, um eine Seite nachzuladen
- s: Der Anteil an Seiten, der sich im Arbeitsspeicher befindet, im Verhältnis zur Gesamtzahl aller für die Programmausführung benötigten Seiten (0 < s ≤ 1)
- p(s): Die Wahrscheinlichkeit eines Seitenfehlers, abhängig von s
Damit Thrashing vermieden wird, muss p(s) ≤ t/T sein. Der minimale Anteil w an Seiten, der sich im Speicher befinden muss, wird bestimmt durch die Gleichung
- p(w) = t/T.
Er wird als Working Set bezeichnet. Workingset ist ein Bruchteil des Programms, der im Arbeitsspeicher vorhanden ist (nicht auf der Festplatte oder ähnlichem).
Wären die Zugriffe auf den Speicher gleich verteilt, so wäre p(s) = 1 - s. Erfreulicherweise treten die Speicherzugriffe jedoch lokal gehäuft auf: In den meisten Fällen folgt ein Programmschritt dem nächsten. Auch die Daten werden meist in Reihen bearbeitet, beispielsweise wenn Rechenoperationen auf ganze Tabellen angewendet werden. Deshalb ist die Wahrscheinlichkeit sehr hoch, dass der nächste Programmschritt und das nächste benötigte Datenelement sich auf derselben Seite befinden wie der gerade verarbeitete Schritt und das gerade verarbeitete Element.
Auf der anderen Seite ist das Verhältnis T/t typischerweise sehr groß: RAM ist mehr als 100-mal so schnell wie Plattenspeicher.
Experimentelle Messungen und Berechnungen, die bereits in den 1960er Jahren durchgeführt wurden, ergeben unter diesen Bedingungen für w einen Wert von nicht wesentlich weniger als 0,5. Das bedeutet, dass der Auslagerungsspeicher kaum größer als der Arbeitsspeicher sein darf.
In der Praxis wird z. B. unter UNIX-Betriebssystemen für die meisten Anwendungsfälle eine Größe des Auslagerungsspeichers vom Zwei- bis Dreifachen des Arbeitsspeichers empfohlen (abhängig davon, ob das jeweilige System den Auslagerungsspeicher zusätzlich zum Arbeitsspeicher oder den Arbeitsspeicher als echte Teilmenge des Auslagerungsspeichers verwaltet).
Kriterien und Strategien für die Seitenersetzung
Verschiedene Kriterien werden zur Bewertung herangezogen:
- Zugehörigkeit der Speicherseite zum aktiven Prozess
- Es hat sich gezeigt, dass Prozess-Scheduling-Algorithmen, welche ohne Trennung der Speicherseiten nach Prozessen arbeiten, besonders wenn sich im laufenden Betrieb die Größe des Hauptspeichers ändert, effizienter sind.
- Letzter Zugriff auf die Speicherseite
- R-Bit oder Reference-Bit zeigt an, ob auf die Speicherseite zugegriffen worden ist. Je nach Implementierung werden entweder in einem bestimmten Zeitintervall alle R-Bits auf 0 gesetzt oder man speichert neben R-Bits auch Zeitstempel ab.
- Unversehrtheit der Speicherseite
- M-Bit oder Modification-Bit zeigt an, dass der Speicherinhalt des Hauptspeichers sich gegenüber dem des Inhaltes auf der Festplatte geändert hat. Wird die Speicherseite ausgelagert, muss die Änderung zurück auf die Festplatte geschrieben werden. Ansonsten entfällt das Zurückschreiben und man spart sich einen teuren I/O-Zugriff.
Seitenersetzungsstrategien
- Die optimale Seitenersetzungsstrategie
- Für jede Seite wird ermittelt, wie viele Instruktionen ausgeführt werden, bis auf die Seite zugegriffen wird. Es wird die Seite mit der größten Anzahl ausgewählt. Die optimale Seitenersetzungsstrategie kann allerdings ohne genaue Kenntnis über den Programmablauf und ggf. auftretende Anomalien, nicht implementiert werden.
Folgende Strategien werden verwendet:
- First In - First Out (FIFO)
- Die älteste Seite wird ersetzt. Betrachtet wird hierbei der Zeitpunkt des letzten Eintritts in den Hauptspeicher. Diese Strategie findet in der Praxis selten Verwendung, da hier die sogenannte Belady-Anomalie auftreten kann. Die Inklusionseigenschaft ist nicht erfüllt.
- Second Chance (SC)
- SC ist eine Weiterentwicklung von FIFO. Dabei wird geprüft, ob eine Seite referenziert wurde. Ist dies der Fall, wird ihr R-Bit gelöscht und wieder an den Anfang der Schlange gesetzt.
- Uhr/Clock
- Ist eine schnellere Implementierung von SC, da sie nicht auf Vertauschen beruht, sondern einen Zeiger benutzt, der auf die Seite zeigt, welche am längsten im Speicher ist.
- Least recently used (LRU)
- Die am längsten nicht genutzte Seite wird ausgelagert.
- Least frequently used (LFU)
- Ein Zähler pro Seite zählt mit, wie häufig auf diese Seite zugegriffen wurde. Es wird diejenige Seite entfernt, auf die am wenigsten zugegriffen wurde.
- Not recently used (NRU)
- Seiten, die innerhalb eines Zeitintervalls nicht benutzt und nicht modifiziert wurden, werden bevorzugt ausgelagert; danach Seiten, die entweder nicht benutzt oder nicht modifiziert wurden und als letzte Gruppe erst Speicherseiten, die benutzt und modifiziert wurden.
- Not frequently used (NFU)
- Seitenzugriffe werden mit dem zeitlichen Abstand zur aktuellen Anfrage korreliert und so ein Wert ermittelt. NFU ist eine Variante von LRU in Software.
- CLIMB
- Wird eine Seite, die bereits im Speicher steht, referenziert, so steigt sie um eine Position in einer Ordnung auf. Ersetzt wird immer die unterste Seite in dieser Ordnung.
Siehe auch
Wikimedia Foundation.