- Erbinformation
-
Als Genom oder auch Erbgut eines Lebewesens wird die Gesamtheit der vererbbaren Informationen einer Zelle bezeichnet, die als Desoxyribonukleinsäure (DNA) vorliegt. Einige Viren nutzen statt DNA RNA als Speichermedium. Das Genom enthält die Informationen, die zur Entwicklung (Ontogenese) und zur Ausprägung der spezifischen Eigenschaften des Lebewesens oder Virus notwendig sind. Diese Informationen sind in der Basensequenz der DNA enthalten.
Der Begriff wurde 1920 von Hans Winkler geprägt und mit Genom bezeichnet. Die Erforschung des Genoms und die Wechselwirkung der darin enthaltenen Gene wird als Genomik bezeichnet (englisch Genomics).
Inhaltsverzeichnis
Chemische Grundlagen
Die für die Vererbung von Eigenschaften und Merkmalen erforderlichen und auf der Ebene der Zellen und der Individuen weitergegebenen Informationen sind in den Desoxyribonukleinsäuren (DNA, von englisch deoxyribonucleic acid) enthalten, und zwar in Form von Sequenzen der DNA-Basen Adenin, Guanin, Cytosin und Thymin. Die DNA-Moleküle können in Abschnitte mit kodierenden und nicht-kodierenden Sequenzen eingeteilt werden. Die kodierenden Abschnitte (Gene) enthalten die Erbinformationen für bestimmte Proteine. Daneben gibt es DNA-Abschnitte, die der Genregulation dienen. Pseudogene sind durch Mutationen funktionslos gewordene und vom Organismus nicht mehr abgelesene Gene. Bei Eukaryoten findet durch das alternative Splicing eine Datenkompression statt, so dass die Genomgröße (in Basenpaaren gemessen) kleiner sein kann als die Anzahl der durch das Genom kodierten Merkmale.
Bei allen Organismen, die komplexer als Viren sind, gibt es außerhalb der chromosomalen DNA (bei Eukaryoten Karyom genannter Teil des Genoms) weitere Genombestandteile in anderen Zellteilen. So finden sich bei Bakterien und Archaebakterien essentielle Plasmide, bei Eukaryoten (Pflanzen, Tiere, Pilze) gibt es selbstständig vererbte DNA-Sequenzen in den Mitochondrien (Mitochondriom) und Plastiden (Plastidom), die aber zum Gesamtgenom der Zellen gehören.
Genomgrößen
Die Angabe der Genomgröße eines Organismus bezieht sich auf die vorhandene Menge an DNA pro haploiden Zellkern, wobei entweder die Zahl der jeweils vorhandenen Basenpaare (bp) angegeben wird oder die Masse der DNA in der Einheit pg (Picogramm). 1 pg doppelsträngiger DNA besteht aus zirka 0,978·109 bp, also aus knapp einer Milliarde Basenpaaren.
Nach neueren Untersuchungen besitzt der Südamerikanische Lungenfisch (Lepidosiren paradoxa) mit 80 pg (7,84 × 1010 bp) das größte bisher bekannte tierische Genom.[1] Ältere, aber wohl ungenauere Untersuchungen zeigen mit zirka 133 pg noch größere Genome, die ebenfalls bei Lungenfischen, allerdings bei der afrikanischen Art Äthiopischer Lungenfisch (Protopterus aethiopicus) gefunden wurden.[2] Mit 0,04 pg (weniger als 50 Millionen Basenpaare) besitzt das zum primitiven Tierstamm Placozoa gehörende, auf Algen lebende, etwa 2 mm große, wenig differenzierte Trichoplax adhaerens das kleinste bisher bekannte tierische Genom.[2] Die Zahl der Basenpaare des Darmbakteriums Escherichia coli ist nur um einen Faktor 10 kleiner. Rekordhalter für das kleinste bakterielle Genom ist derzeit der Blattfloh-Endosymbiont Carsonella ruddii: er begnügt sich mit einem zirkulären Genom aus nur knapp 160.000 Basenpaaren, auf der er sämtliche Informationen speichert, die er zum Leben braucht.[3]
Vergleich der Genomgrößen Organismus Genomgröße1 Gene Gendichte2 λ-Phage 5 × 104 Blattfloh-Endosymbiont Carsonella ruddii 1,6 × 105 182 1.138 Darmbakterium Escherichia coli 4,6 × 106 4.500 900 Bäckerhefe Saccharomyces cerevisiae 2 × 107 6.000 300 Trichoplax adhaerens 4 × 107 Fadenwurm Caenorhabditis elegans 8 × 107 19.000 200 Ackerschmalwand Arabidopsis thaliana 1 × 108 25.500 255 Taufliege Drosophila melanogaster 2 × 108 13.500 70 Kugelfisch Fugu rubripes 3,65 × 108 Kohl Brassica oleracea 5,99-8,68 × 108 100.000 599-868 Mensch Homo sapiens 3,2 × 109 20.000 - 25.000 10 Teichmolch Triturus vulgaris 2,5 × 1010 1in Basenpaaren 2Anzahl der Gene pro Millionen Basenpaare Bemerkungen
- Bei Eukaryoten beziehen sich die Zahlenangaben auf den haploiden Chromosomensatz.
- Die meisten dieser Lebewesen sind Modellorganismen.
- Da die Anzahl der Gene je nach Organismus unterschiedlich genau bestimmt und Gegenstand aktueller Forschungen ist, können Angaben aus unterschiedlichen Quellen um wenige tausend Gene voneinander abweichen (Beispiel: Die Anzahl der Gene beim modernen Menschen (Homo sapiens) liegt etwa im Bereich 20.000-30.000).
- Angaben zur Gendichte sind demnach auch nur als Richtwerte zu verstehen.
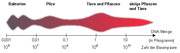 Verteilung der Genom-Größen.
Verteilung der Genom-Größen.Die DNA einer einzelnen menschlichen Zelle ist zirka 1,80 m lang. Eine Base auf einem DNA-Strang hat einen Informationsgehalt von 2 bit, da sie 22 = 4 Zustände (A/T/G/C) annehmen kann. Ausgehend von 3×109 Basenpaaren hat das Genom des Menschen einen Informationsgehalt von etwa 750 MB.
Ein Vergleich der Genom-Größe mit der Komplexität und des Organisationsgrades des Organismus ergibt einen direkten Zusammenhang: Je größer das Genom, um so komplexer ist der Organismus.
Ausnahmen bilden hierbei weniger komplexe Organismen mit hoher DNA-Menge (als „C-Wert-Paradoxon“ bezeichnet): einige Samenpflanzen, die Salamander und urtümliche Fische wie Stör, Hornhecht und Quastenflosser.
Die höchste DNA-Menge weisen einfache Eukaryoten wie einige Amöben und die Urfarne (Psilopsida) mit rund einer Billion Basenpaare auf.
Diese Arten enthalten einzelne Gene als tausendfache Kopien, und lange, nicht-Protein-kodierende Abschnitte. Auch im menschlichen Genom kommt ein etwa 300 Basenpaare langes DNA-Stück, die Alu-Sequenz in über 1.000.000 Kopien vor und macht etwas über 10 % der gesamten DNA aus.[4]
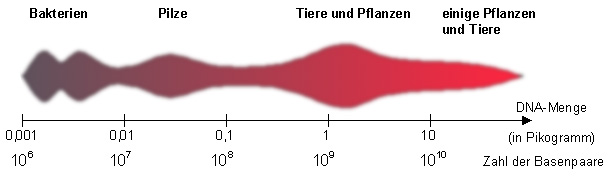
 Anteil der DNA, der nicht für Proteine kodiert.
Anteil der DNA, der nicht für Proteine kodiert.Wird dagegen der Anteil der DNA, der nicht Proteine kodiert, betrachtet, ergibt sich ein direkter Zusammenhang zur Komplexität des Organisationsgrades (Vergleiche dazu die Angaben zur Gendichte in der Tabelle oben).
Dieser Zusammenhang könnte darin begründet sein, dass diese Sequenzen zahlreiche regulatorische Aufgaben erfüllen. Zur Zeit (März 2005) wird die Möglichkeit diskutiert, dass die Komplexität eines Organismus in Zusammenhang mit der Menge an DNA steht, die zwar keine Proteine kodiert, aber dennoch transkribiert, also in RNA übertragen wird. Dabei werden Introns nicht als Reste alter Gene aufgefasst, sondern als Abkömmlinge beweglicher DNA-Abschnitte, vergleichbar mit den heutigen Gruppe-II-Introns. Diese und weitere RNA-Moleküle, die durch Transkription entstehen, und die weder m-, t- oder rRNAs sind, können Teil eines Regulationssystems sein, das neben den Proteinen die Entwicklung eines Organismus steuert. Zum Beispiel sind RNA-Signale an der Markierung des Chromatins beteiligt, wodurch die Genexpression gesteuert wird.
Bestandteile des menschlichen Genoms
Die Zahlen beziehen sich auf den haploiden Chromosomensatz des Menschen ohne mitochondriale DNA (mtDNA). Mb = 106 Basen
Die Gesamtmenge des menschlichen Genoms beträgt 3.000 Mb, das sind 3 Milliarden Basenpaare.
Der Mensch besitzt 20.000 bis 25.000 Gene[5] (andere Quellen gehen – bei vorläufiger Berechnung – von 30.000 bis 40.000 Genen aus[6]).
Gene
Ein Teil des Genoms besteht aus Sequenzen, die in einem Transkription genannten Vorgang in eine RNA übertragen werden. Diese Sequenzen werden auch als Gene bezeichnet.
Protein-kodierende Gene
Das RNA-Transkript enthält Basensequenzen, welche die Aminosäuresequenz von Proteinen kodieren. Die RNA wird dann als mRNA bezeichnet. Bei den Eukaryoten ist sie aus Exons und Introns zusammengesetzt und wird in diesem Zustand als prä-mRNA oder hnRNA bezeichnet. Sie wird noch vor der Translation bearbeitet (prozessiert), indem die nichtkodierenden Introns herausgeschnitten werden. Da die DNA der Prokaryoten keine Introns aufweist, hat auch die mRNA keine Introns und erfordert folglich auch kein Splicing.
Die Aminosäuresequenzen-kodierende DNA ist beim Menschen 90 Mb groß, das sind 3 % des Genoms. Das entspricht 25000 Genen, die ungefähr 500.000 Proteine kodieren.
Von Genen abstammende Sequenzen
Einige Basensequenzen stammen zwar von Genen ab, das Transkript wird aber nicht in eine Aminosäuresequenz übersetzt.
- Pseudogene sind veränderte Kopien funktionell aktiver Gene, die aber - durch Mutationen bedingt - nicht mehr für ein stabiles Protein kodieren können. Früher hielt man Pseuogene für grundsätzlich funktionslos (also "genetischen Müll", was sie zum größten Teil wohl auch sind), mittlerweile hat sich aber heraus gestellt, dass einige transkribierte Pseudogene an der Expressionsteuerung ihrer (funktionalen) Ursprungsgene beteiligt sein können.
- Introns werden noch im Zellkern der Eukaryoten aus der prä-mRNA herausgeschnitten. Ihre Rolle ist nicht vollständig geklärt. Einige enthalten Erkennungssequenzen für Replikationsfaktoren, die die Aktivität der RNA-Polymerase beeinflussen. Eine bisweilen geäußerte Vermutung ist, dass durch die zwischen die kodierenden Exons eingestreuten Introns die Mutationshäufigkeit in den kodierenden Sequenzen herabgesetzt ist. Dagegen spricht aber, dass auch in den Introns hochkonservierte consense-Sequenzen (siehe unten) zu finden sind, ferner macht ein solcher Mechanismus der "Mutationsabwehr" nicht wirklich Sinn. Fest steht hingegen, dass etlichen Introns eine definierte biologische Rolle zukommt: Ein großer Teil der eukaryontischen Gene kann differenziell gespleißt werden, d.h. es können von den vorhandenen Exonen unterschiedliche Kombinationen in der reifen mRNA auftauchen - verursacht durch die Auswahl unterschiedlicher Introne beim Spleißen. Auf diese Weise kann ein einziges Gen für mehrere (u.U. Dutzende) verschiedene Proteinvarianten kodieren, die allesamt etwas unterschiedliche Eigenschaften (Ligandenbindestellen, Interaktionsdomänen, Membrananker etc.) aufweisen. Introns haben in der Evolution eine wichtige Rolle gespielt, weil sie die Neukombination von Exonen durch chromosomale Rearrangements erleichtern. Die Frage, ob Introns ursprünglich sind (also so alt wie die Gene selbst), oder erst in neuerer Zeit entstanden ist nicht entschieden.
- Genfragmente (die man als eine Version von Pseudogenen betrachten muss) entstehen dann, wenn es von einem Gen mehrere Kopien im Genom gibt und eine dieser Kopien durch Deletion(en) unbrauchbar wird.
RNA-codierende Gene
Das RNA-Transkript enthält Basensequenzen, welche die Basensequenz von RNAs kodieren. Diese Moleküle werden auch als ncRNAs (nc von engl. non coding = nicht kodierend) bezeichnet und erfüllen zahlreiche Aufgaben bei der Proteinbiosynthese. Einige davon sind erst vor kurzem bekannt geworden und noch nicht genauer erforscht. Es wird vermutet, dass die ncRNAs molekulare Fossilien aus der RNA-Welt sind (siehe chemische Evolution) und damit von Bedeutung für das Verständnis der Evolution der Lebewesen sind.
- tRNAs transportieren Aminosäuren zu den Ribosomen.
- rRNAs sind Bestandteile der Ribosomen und erfüllen dort strukturelle und katalytische Aufgaben. ssRNA (ssuRNA, small subunit RNA) ist die RNA für die kleine, lsRNA (lsuRNA, large subunit RNA) die für die große Untereinheit der Ribosomen.
- snRNAs sind Bestandteile der Spliceosomen, welche aus der prä-mRNA die Introns herausschneiden.
- Ebenfalls ein junges Forschungsgebiet ist die RNA-Interferenz (RNAi), eine weitere Möglichkeit der Regulation der Proteinbiosynthese, wobei kleinere RNA-Moleküle mit Teilen der mRNA reagieren und dadurch in der Regel die Translation verhindern. Solche RNA-Moleküle sind siRNAs (si von engl. short interfering), microRNAs, von welchen das menschlichen Genom mehrere Hundert aufweist. Es gibt auch Interaktionen von RNAs mit der DNA, mit Proteinen und mit niedermolekularen Substanzen.
- Mikro-RNA: Manche Introns enthalten zueinander komplementäre Abschnitte, so dass die prä-RNA nach der Transkription Haarnadelschleifen bilden kann. Diese werden durch spezielle Proteine des „Zensursystems“ (ursprünglich ein Abwehr-System gegen virale Doppelstrang-RNA) erkannt und so abgebaut, dass einsträngige RNA-Abschnitte entstehen, die an andere mRNAs binden und somit spezifisch (zielgenau) mRNA zerstören können (RNA-Interferenz) oder ihre Translation unterdrücken. Für einzelne Moleküle ist ihre Funktion bekannt: Sie sorgen dafür, dass Stammzellen sich nicht differenzieren, und steuern Zellvermehrung und Apoptose (programmierter Zellselbstmord) beim Umbau embryonaler Gewebe.
- Antisense-RNA: Die mRNA entsteht am codogenen (Matrizen-) Strang der DNA. Wird auch der komplementäre Strang abgelesen, entsteht eine zur mRNA komplementäre RNA. Verbinden sich mRNA und Antisense-RNA zu einem Doppelstrang, kann kein Protein mehr bei den Ribosomen gebildet werden. Auch dies stellt eine Möglichkeit der Regulation der Proteinbiosynthese dar. Beim Menschen gibt es mindestens 1600 antisense-Gene.
- 7SL-RNA ist Bestandteil der signal recognition particles, das sind Protein-RNA-Komplexe, welche den zielgerichteten Transport von Proteinen in der Zelle gewährleisten.
Nichtkodierende Sequenzen
Der übrige Teil des Genoms besteht aus Sequenzen, die nicht transkribiert werden (siehe nichtkodierende Desoxyribonukleinsäure). Er wird als extragenische DNA bezeichnet und weist eine Länge von insgesamt 2100 Mb auf.
Davon besteht der größte Teil (1.680 Mb) aus einzelnen, individuellen oder nur selten wiederholten Basensequenzen. Dies sind in der Regel Sequenzen, an welche bestimmte Enzyme binden und dadurch die Replikation und Transkription steuern:
- An die Promotor-Sequenzen (TATA-Box) bindet die RNA-Polymerase
- Initiations- und Terminations-Sequenzen, markieren Beginn und Ende eines Gens
- Consense-Sequenzen sind hochkonservierte Sequenzen, die die Grenzen zwischen Exons und Introns markieren
- An Operator-Sequenzen oberhalb (engl. upstream) und unterhalb (engl. downstream) von Genen, an welche Regulatorproteine binden, um die Transkription zu beschleunigen oder zu verzögern und damit ihre Feinregulation übernehmen.
- Palindrome sind Erkennungssequenzen für Restriktionsendonukleasen.
- Bei den Abstandshaltern kommt es nicht auf die Sequenz, sondern die Zahl der Basen an. Deshalb können hier die Mutationsraten ohne Auswirkungen sehr hoch sein, solange es nicht zu Baseneinschub, oder Basenverlust kommt. Diese DNA-Abschnitte sorgen dafür, dass die Operator-Sequenzen im Falle der Transkription bei der Schleifenbildung in die richtige Position zu den Promotern gebracht werden, und so die RNA-Polymerase beeinflussen können.
- Untersuchungen an Cryptomonaden (einzelligen, Photosynthese betreibenden Eukaryonten) haben gezeigt, dass die Menge an nichtkodierender DNA proportional zur Größe des Zellkerns ist und vermutlich eine wesentliche Rolle für die Strukturierung des Zellkerns hat.
Der Rest der DNA von 420 Mb besteht aus hoch repetitiven Sequenzen.
disseminierte (verstreute) genomweite Wiederholungen
- LTR-Elemente (LTR-Retrotransposons und Retroviren) (8,5 % des Gesamtgenoms). Sie gehen zum Teil auf Genom-Überreste von integrierten Retroviren zurück und können die gewebespezifische Aktivität von Wirtsgenen steuern. Zur Zeit (2005) sind 20 Gene des Menschen bekannt, die durch virale LTRs kontrolliert werden. Insgesamt konnten mindestens 600.000 retrovirale LTRs im menschlichen Genom gefunden werden.
- DNA-Transposone (3 % des Gesamtgenoms)
- LINE-Sequenzen (LINE 1, LINE 2) (long interspersed nuclear element) (21 % des Gesamtgenoms)
- SINE-Sequenzen (short interspersed nuclear element) (13 % des Gesamtgenoms) (z. B. Alu-Sequenz, die nur bei Primaten zu finden ist) ermöglichen eine Verlagerung einer Sequenz an eine andere Stelle des Genoms. Sie sind 70 bis ca. 500 Basen lange Retroposons, d.h. Elemente, deren Ortswechsel über eine transkribierte RNA-Sequenz erfolgt, deren cDNA-Produkt an anderer Stelle ins Genom integriert wird. In Genomen von Eukaryoten findet man bis zu 104 Kopien. Das Transkript der Alu-Sequenz wird durch das sogenannte „A-zu-I-Editing“ verändert: Das Nukleosid Adenosin zum Nukleosid Inosin umgewandelt. Dies findet vor allem im Gehirn statt. Es wird ein Zusammenhang zwischen Fehlern in diesem Prozess und Epilepsie und Depression vermutet.
Tandemwiederholungen
Die Anzahl der Wiederholungen variiert von Individuum zu Individuum, die Abweichungen sind vom Verwandtschaftsgrad abhängig. Deshalb sind sie für den genetischen Fingerabdruck geeignet. Die von der Norm abweichende Zahl an Wiederholungen kann Krankheiten auslösen.
- Mikrosatelliten-DNA, z. B. (CA)n, mit einer repetitiven Einheit von 2 bis 7 Basenpaaren. Sie sind im ganzen Genom verteilt, und werden auch zur genetischen Kartierung verwendet. Mikrosatelliten weisen eine hohe Mutationsrate auf und haben damit auch eine Bedeutung in der Evolution von Organismen.
- Minisatelliten-DNA, mit einer repetitiven Einheit von 20 bis 100 Basenpaaren sind ebenfalls im ganzen Genom verteilt.
- Satelliten-DNA tritt nur im Heterochromatin auf, z.B. im Centromer. Sie besteht aus kurzen Basensequenzen, die mehrfach hintereinander wiederholt werden. (Beim Menschen 100.000).
- In den Genen des MHC-Komplexes (Haupthistokompatibilitätskomplex) von Säugetieren wurden sich wiederholende (repetitive) Folgen von GT und GA in der DNA festgestellt, die eindeutig nicht für Eiweiße kodieren können. Gleichwohl sind sie funktional, denn sie binden Zellkern-Proteine und sind vermutlich über die DNA-Protein-Interaktion an der Genregulation beteiligt.
Weitere besondere DNA-Sequenzen
- Telomere: Bei Wirbeltieren befinden sich am Ende des 3’-Stranges der DNA 250 bis 15600 repetitive Sequenzen TTAGGG, da sonst die Replikation am anderen Strang vorzeitig abbrechen würde. Diese Abschnitte werden mit jeder Zellteilung kürzer. Sie schützen auch die Chromosomen vor dem Zusammenkleben oder vor Abbau. Bei Bruch der Chromosomen kann erkannt werden, welche Enden wieder zusammengefügt werden müssen.
- Der kurze Arm von Chromosom 22 (HSA22p), enthält nur Heterochromatin, das praktisch nur aus repetitiver DNA besteht.
- Fremdgene
- HERV (human endogene Retroviren) (9 % des Gesamtgenoms) sind Fremdgene, die von inaktiven Viren stammen, die in das Genom integriert sind.
- 1998 wurde eine Mutation entdeckt, die typisch für Menschenaffen ist und auch bei Menschen vorkommt: Eine Kopie eines Stücks des mitochondrialen Genoms (Kontrollregion) ist auf ungeklärte Weise in den Zellkern gelangt und dort auf Chromosom Nr. 9 zu finden (nachgewiesen bei Gibbons, Orang-Utan, Gorilla, Schimpanse, Mensch).
- Bakterielle Sequenzen machen ungefähr 2 Promille des Gesamtgenoms aus.
- Die Untersuchung von TIREs (transposable and interspersed repetitive elements) bei verschiedenen Insekten-Arten ergab ein in hohem Grad nicht zufälliges Muster, so dass auch hier eine - noch unbekannte - Funktion postuliert wird.
Sogenannte Junk-DNA
Abschnitte der DNA, von denen man zunächst annahm, sie trügen keinerlei genetische Information, wurden von der Wissenschaft als „Junk DNA“ oder „Müll-DNA“ bezeichnet. Auch Introns, die kodierende Teile voneinander separieren, wurden der Kategorie Junk-DNA zugerechnet. Mit dem heutigen Wissensstand ist diese Ansicht überholt. Vielmehr sind in den anscheinend bedeutungslosen DNA-Sequenzen sowohl „alter Code“ als Vorstufen für Gensequenzen zu finden. Für den Organismus tatsächlich bedeutungslose Sequenzen dürften im Laufe der Evolution zum Teil verloren gegangen sein, als auch noch auf den Introns zu finden sein. (Siehe die Evolution des Y-Chromosoms).
Repetitive Sequenzen erleichtern den Austausch zwischen homologen Chromosomen während der Meiose (Crossing Over) und erhöhen damit die genetische Variabilität.
Organisation von Genomen
Prokaryotengenome
Bei den Prokaryota (Bacteria und Archaea) besteht das Genom aus einem großen, in sich geschlossenen DNA-Molekül und mehreren kleineren, ebenfalls in sich geschlossenen, in ihrer Zahl variierenden DNA-Molekülen, den Plasmiden. Diese können sich unabhängig von der Haupt-DNA verdoppeln und an andere Bakterienzellen weitergegeben werden, ein Prozess, der als Konjugation bezeichnet wird. Sie enthalten in der Regel nur wenige Gene, die zum Beispiel Resistenzen gegen Antibiotika oder Fertilität, die Fähigkeit zur Konjugation vermitteln. Manche Plasmide sind reversibel in die Haupt-DNA integriert und werden dann als Episome bezeichnet.
Eukaryotengenome
Bei den Eukaryota (im Wesentlichen Pflanzen, Pilze und Tiere) ist das Genom in mehrere strangförmige Chromosomen unterteilt, die nur im Zellkern vorkommen und deshalb als Karyom bezeichnet werden. Neben dem Karyom können Organellgenome vorhanden sein.
Organellengenome
In eukaryotischen Zellen können Organelle vorhanden sein, die ihrerseits eigene vererbbare DNA enthalten. Man spricht in solchen Fällen vom Kerngenom und den Organellgenomen. Das Kerngenom ist das eigentliche in Chromosomen organisierte Genom der Zelle, welches sich im Zellkern befindet. Ein Organellgenom ist die Gesamtheit der genetischen Information des entsprechenden Organell-Typs. Organelle, welche eigene Genome enthalten, stammen nach der Endosymbiontentheorie von Bakterien ab, die in sehr früher Zeit der Lebewesenentwicklung in andere prokaryotische Wirtszellen eingewandert sind, wodurch - zusammen mit anderen Vorgängen - Eukaryoten entstanden sind. Das trifft sowohl auf die Mitochondrien als auch auf die Plastiden (z. B. Chloroplasten) zu.
Da die Organelle von ihren Wirtszellen versorgt werden, müssen sie ihrerseits nur spezielle Funktionen übernehmen. Diese Funktionen sind bei den Mitochondrien auf die Atmung und bei den Chloroplasten auf die Photosynthese fokussiert. Die Genome sind entsprechend klein. Bemerkenswert ist die Tatsache, dass die Organelle eigene genetische Codes besitzen und spezielle Nukleotide in den tRNAs aufweisen. Entsprechend ihrer Herkunft sind Organellgenome im Grunde Prokaryotengenome, wegen ihrer Größe werden sie eher als Plasmide bezeichnet.
Die Tatsache, dass die Mitochondrien nicht an der Rekombination durch die Meiose teilnehmen und bei Menschen (weitestgehend) durch die Eizelle nicht aber durch Spermien in die Zygote gelangen, führt dazu, dass bestimmte Bereiche in mitochondrialen Genomen als „evolutionäre Marker“ in der Humangenetik bzw. Populationsgenetik Anwendung finden.
Virusgenome
Die Genome von Viren besitzen einen geringeren Umfang (1.000 bis 350.000 bp), da weniger Proteine kodiert werden müssen und oft einzelne Genomabschnitte durch überlappende Leserahmen, alternative Start- und Stopcodons und verschiedene Leseraster für verschiedene Transkripte kodieren. Dadurch ist die genetische Information auf besondere Weise im viralen Genom konzentriert.
Das Genom von Viren ist weit vielfältiger als bei anderen Gruppen: es kann als RNA- oder DNA vorliegen, jeweils einzel- oder doppelsträngig, verschiedene Leserichtungen beinhalten, linear, zirkulär oder segmentiert sein. Eine Besonderheit stellen einige RNA-Viren dar, nämlich die Retroviren, da sie ihr RNA-Genom mittels Reverser Transkription in DNA umschreiben können. Die Eigenschaft des Genoms bei Viren dient als wichtiges Kriterium zu deren Einteilung (Virus-Taxonomie).
Sequenzierte Genome im Internet
Die DNA von Genomen verschiedener Organismen, die entweder für die medizinisch-pharmazeutische oder anwendungsorientierte Forschung oder auch für die Grundlagenforschung relevant sind, wurde annähernd vollständig „sequenziert“ (man spricht auch fälschlicherweise vom „Entschlüsseln“), das heißt ihre Basensequenz wurde ermittelt (DNA-Sequenzierung). Die Basensequenzen werden über das Internet u.a. vom NCBI bereitgestellt.
- Übersichten
- Quick Guide to Sequenced Genomes (GNN) (exzellente Übersichtseite, in alphabetischer Ordnung und hervorragend organisiert findet man bisher sequenzierte Organismen mit Abbildungen, Kurzinformationen, für die Sequenzierung verantwortliche Institution und relevante Literatur mit Links)
- Genome Atlas
- Einzelne Genome
Quellenangaben
- ↑ A.E. Vinogradov: Genome size and chromatin condensation in vertebrates. Chromosoma 113, 2005; Seiten 362-369.
- ↑ a b T.R. Gregory: Animal Genome Size Database. 2005
- ↑ Petra Jacoby: Spektrum der Wissenschaft, Spektrum der Wissenschaft Verlagsgesellschaft mbH, Band 5, 2007, S. 16f
- ↑ M. A. Batzer and P. L. Deininger. Alu Repeats and Human Genomic Diversity. Nature Reviews: Genetics 3: 370-9 (May 2002)
- ↑ Internationales Humangenomprojekt (IHGSC). in: Nature. London 431, S. 931. ISSN 0028-0836 (Von den 3,08 Milliarden Basenpaaren sind zur Zeit 2,88 Milliarden bei dem öffentlichen Genomprojekt verfügbar)
- ↑ Neil A. Campbell: Biologie. Spektrum Verlag, Heidelberg 1997, S. 467; Pearson Studium, München 2006. ISBN 3-8274-0032-5, ISBN 3-8273-7180-5
- ↑ Daniel Lang, Andreas Zimmer, Stefan Rensing, Ralf Reski (2008): Exploring plant biodiversity: the Physcomitrella genome and beyond. Trends in Plant Science 13, 542-549 [1]
Literatur
- Martin Mahner & Michael Kary (1997): What Exactly Are Genomes, Genotypes and Phenotypes? And What About Phenomes? In: Journal of Theoretical Biology. Bd. 186, S. 55-63. PMID 9176637 doi:10.1006/jtbi.1996.0335
- Ernst Peter Fischer: Das Genom. Fischer Taschenbuch, Frankfurt am Main 2002, 2004. ISBN 3-596-15362-x
- W. Wayt Gibbs: Preziosen im DNA-Schrott. in: Spektrum der Wissenschaft. Heidelberg 2004,2 (Febr.), S.68-75. ISSN 0170-2971
- W. Wayt Gibbs: DNA ist nicht alles. in: Spektrum der Wissenschaft. Heidelberg 2004,3 (März), S.68-75. ISSN 0170-2971
- Günther Witzany: Natural Genome Editing Competences of Viruses. in: Acta Biotheoretica 54, 2006, S.235-253. doi:10.1007/s10441-006-9000-7
- Ernst-Ludwig Winnacker: Das Genom. Eichborn, ISBN 3-8218-3931-7
Siehe auch

Wikimedia Foundation.