- Canny-Detektor
-
Der Canny-Algorithmus, benannt nach John Canny, ist ein in der digitalen Bildverarbeitung weit verbreiteter, robuster Algorithmus zur Kantendetektion. Er gliedert sich in verschiedene Faltungsoperationen und liefert ein Bild, welches idealerweise nur noch die Kanten des Ausgangsbildes enthält.
Da der Algorithmus nur auf Graubildern arbeiten kann, ist eine vorherige Überführung von farbigen Bildern in Graubilder erforderlich. In diesen Grauwertbildern sind Kanten durch große Helligkeitsschwankungen zwischen zwei benachbarten Pixeln charakterisiert. Sie können somit als eine Unstetigkeit der Grauwertfunktion g(x,y) des Ausgangsbildes aufgefasst werden. Da derartige Unstetigkeiten auch ohne das Vorhandensein von Kanten einfach durch Bildrauschen auftreten können, verwendet der Algorithmus die Normalverteilung zur Glättung des Bildes.
 Mehrdimensionale Normalverteilung
Mehrdimensionale NormalverteilungDabei wird das Originalbild mit Hilfe einer Maske gefaltet, die die Normalverteilung annähert. Der neue Grauwert eines Pixels gn(x,y) ergibt sich dabei aus den gewichteten Werten der ihn umgebenden Pixel. Ein Beispiel für eine solche Maske könnte sein:
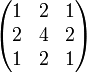
Je größer hierbei die Maske gewählt wird, desto robuster wird der Algorithmus gegenüber Rauschen.
 Ausgangsbild für den Algorithmus
Ausgangsbild für den AlgorithmusAnschließend werden die Gradienten der einzelnen Pixel ermittelt, indem das Bild mit Hilfe des Sobeloperators gefaltet wird. Dieser arbeitet entweder in X-Richtung oder in Y-Richtung und betont somit entweder horizontale oder vertikale Kanten. Auch beim Sobeloperator ergibt sich der neue Wert eines Pixels aus den gewichteten Werten der ihn umgebenden Pixel. Da für den Canny-Algorithmus der Gradient in X-Richtung gx und der Gradient in Y-Richtung gy benötigt werden, ergeben sich also nach Anwendung des Sobeloperators 2 neue Bilder.
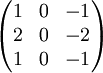 Sobeloperator in X-Richtung
Sobeloperator in X-Richtung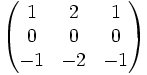 Sobeloperator in Y-Richtung
Sobeloperator in Y-Richtung Ergebnis des Sobeloperators in X-Richtung
Ergebnis des Sobeloperators in X-Richtung Ergebnis des Sobeloperators in Y-Richtung
Ergebnis des Sobeloperators in Y-RichtungMithilfe der beiden so ermittelten Gradienten lässt sich der Anstieg einer potentiellen Kante durch einen Pixel leicht errechnen. Es gilt:
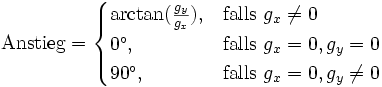 .
.Da ein Pixel jedoch nur 8 Nachbarn hat, ergeben sich lokal lediglich 4 mögliche Kantenrichtungen: 0°, 45°, 90° und 135°. Die soeben errechneten Anstiege werden also auf einen dieser Werte gerundet.
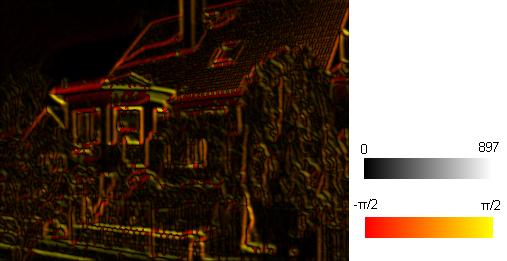
 Errechneter Anstieg potentieller Kanten im jeweiligen Punkt
Errechneter Anstieg potentieller Kanten im jeweiligen Punkt Errechneter Anstieg potentieller Kanten im jeweiligen Punkt mit Darstellung der Kantenstärke (s.u.)
Errechneter Anstieg potentieller Kanten im jeweiligen Punkt mit Darstellung der Kantenstärke (s.u.)Als drittes muss noch ein Bild der absoluten Kantenstärken berechnet werden. Dabei wird der Wert eines einzelnen Pixels aus dem euklidischen Betrag der beiden Gradienten gebildet.
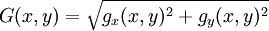
In der Praxis wird zur Steigerung der Effizienz oftmals eine Approximation verwendet:
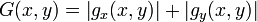
Um sicherzustellen, dass eine Kante nicht mehr als einen Pixel breit ist, sollen im folgenden Schritt einzig die Maxima entlang einer Kante erhalten bleiben. Dafür wird vom Bild mit den absoluten Kantenstärken ausgegangen und für jeden Pixel die Werte G(x,y) mit denjenigen seiner 8 Nachbarn verglichen. Keiner der benachbarten Pixel darf einen höheren Wert aufweisen, es sei denn, der betreffende Nachbarspixel liegt entlang der berechneten Kantenrichtung. Ist dies nicht gegeben, wird der Grauwert auf Null gesetzt. Diese Technik wird "non-maximum suppression" genannt. Errechneter Anstieg (gerundet)
Errechneter Anstieg (gerundet) Errechneter Anstieg (gerundet) mit Darstellung der Kantenstärke
Errechneter Anstieg (gerundet) mit Darstellung der Kantenstärke Verbleibende Pixel (lokale Maxima)
Verbleibende Pixel (lokale Maxima)Abschließend muss natürlich noch festgestellt werden, ab welcher Kantenstärke ein Pixel zu einer Kante zu zählen ist. Um das Aufbrechen einer Kante durch Schwankungen in der errechneten Kantenstärke zu vermeiden wird ein Hysterese genanntes Verfahren angewendet. Bei diesem Verfahren verwendet man zwei Schwellwerte T1 < T2. Man scannt das Bild durch bis ein Pixel gefunden wird dessen Stärke größer T2 ist. Dieser Kante folgt man dann beidseitig. Alle Pixel entlang dieser Kante mit Stärke größer T1 werden als Kantenelement markiert.
Nach diesem letzten Schritt ist der Algorithmus beendet und liefert eine Menge von Punkten, die bei geeigneter Wahl der Schwellwerte die im Ausgangsbild vorhandenen Kanten aufzeigen.
 Ergebnis der Kantenextraktion
Ergebnis der KantenextraktionDiese Menge von Punkten kann auf viele verschieden Arten verwendet werden, um weitere Informationen aus dem Bild zu extrahieren (z.B. Hough-Transformation zur Erkennung einfacher geometrischer Objekte oder Waltz-Algorithmus zur Erkennung von dreidimensionalen Objekten im Bild).








Wikimedia Foundation.