- Chain Code Pictures
-
Ketten-Kode-Bilder (Chain Code Pictures) sind Bilder, die in erster Linie mit Hilfe von formalen Grammatiken erzeugt werden. Die von solchen Grammatiken generierten Wörter werden hierbei jeweils als genau ein Bild interpretiert, indem die einzelnen Buchstaben als Richtungen gedeutet werden und damit ein Zeichnen in einem Koordinatensystem beschrieben wird.
Inhaltsverzeichnis
Grundlagen
Gegeben sei das ganzzahlige Koordinatensystem
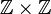 und für jeden Punkt
und für jeden Punkt 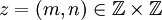 seine Nachbarpunkte mit
seine Nachbarpunkte mitu(z) = (m,n + 1), d(z) = (m,n − 1), r(z) = (m + 1,n), l(z) = (m − 1,n),
wobei u, d, r bzw. l intuitiv für den oberen (up), unteren (down), rechten (right) bzw. linken (left) Nachbarpunkt stehen.
Die Menge π von Richtungen sei mit π = {u,d,r,l} definiert.
Weiterhin versteht man unter einer Einheitsstrecke die Strecke, die durch zwei benachbarte Punkte verbunden wird. Das heißt, für jeden Punkt
und jede Richtung 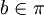 gibt es eine Strecke zwischen z und b(z) (diagonale Strecken sind damit ausgeschlossen). Eine Einheitsstrecke wird mit dem Punktepaar (z,b(z)) repräsentiert, wobei (z,b(z)) und (b(z),z) geometrisch gesehen gleich sind.
gibt es eine Strecke zwischen z und b(z) (diagonale Strecken sind damit ausgeschlossen). Eine Einheitsstrecke wird mit dem Punktepaar (z,b(z)) repräsentiert, wobei (z,b(z)) und (b(z),z) geometrisch gesehen gleich sind.Ein (einfaches) Bild p sei eine endliche Menge von Einheitsstrecken und
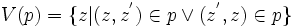 die Menge aller Punkte von p.
die Menge aller Punkte von p.Man nennt das Tripel (z,p,z'), wobei p ein einfaches Bild ist und
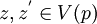 Anfangs- und Endpunkt heißen, gezeichnetes Bild.
Anfangs- und Endpunkt heißen, gezeichnetes Bild.Zwei einfache Bilder p und p' sind genau dann äquivalent – man schreibt
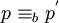 –, wenn zwei Zahlen
–, wenn zwei Zahlen 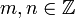 existieren, sodass
existieren, sodass 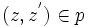 dann und nur dann, wenn
dann und nur dann, wenn 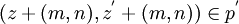 . Analog heißen zwei gezeichnete Bilder q = (z1,p,z2) und
. Analog heißen zwei gezeichnete Bilder q = (z1,p,z2) und 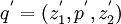 genau dann äquivalent – man schreibt
genau dann äquivalent – man schreibt 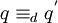 –, wenn zwei Zahlen existieren, sodass dann und nur dann, wenn und
–, wenn zwei Zahlen existieren, sodass dann und nur dann, wenn und 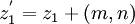 ,
, 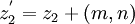 . Intuitiv sind Bilder also bis auf Verschiebung im Koordinatensystem gleich. Wie man leicht zeigen kann, sind
. Intuitiv sind Bilder also bis auf Verschiebung im Koordinatensystem gleich. Wie man leicht zeigen kann, sind 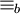 und
und 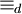 Äquivalenzrelationen über der Menge aller einfachen bzw. gezeichneten Bilder.
Äquivalenzrelationen über der Menge aller einfachen bzw. gezeichneten Bilder.Man bezeichnet ein einfaches Bild p als (einfaches) Unterbild des einfachen Bildes q, wenn ein einfaches Bild p' mit
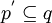 und existiert.
und existiert.Ein Bild p ist ein (einfaches) Ketten-Kode-Bild, wenn eine endliche Folge von Einheitsstrecken
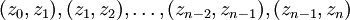 mit
mit 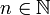 und zi = bi(zi − 1),
und zi = bi(zi − 1),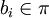 ,
, 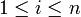 existiert, sodass
existiert, sodass 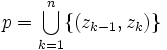 gilt. Folglich ist ein Ketten-Kode-Bild stets zusammenhängend.
gilt. Folglich ist ein Ketten-Kode-Bild stets zusammenhängend.Generierung durch formale Grammatiken
Ketten-Kode-Bilder und Wörter
Auf Grund der Definition von Ketten-Kode-Bildern können jene mit Wörtern (Ketten-Kodes bzw. chain codes) über π assoziiert werden, indem einem Ketten-Kode-Bild p mit der Folge
und zi = bi(zi − 1), , das Wort 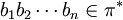 zugewiesen wird.
zugewiesen wird.Andererseits weist man jedem Wort
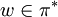 ein gezeichnetes Ketten-Kode-Bild (drawn chain code picture) dccp(w) induktiv wie folgt zu:
ein gezeichnetes Ketten-Kode-Bild (drawn chain code picture) dccp(w) induktiv wie folgt zu:- falls w = ε, dann
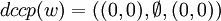
- falls w = w'b,
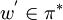 , und dccp(w') = ((0,0),p,z), dann
, und dccp(w') = ((0,0),p,z), dann 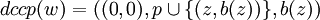
Mit dccp(w) = ((0,0),p,z) ist bccp(w) = p das einfache Ketten-Kode-Bild (basic chain code picture) von w.
Nun können mit einer formalen Grammatik G = (N,π,P,S) Wörter erzeugt und als Ketten-Kode-Bilder interpretiert werden. Die Menge aller von G generierten Bilder sei
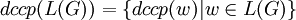 bzw.
bzw. 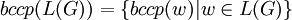 , wobei L(G) die von G erzeugte Sprache (siehe Von G erzeugte Sprache) ist – man nennt sie auch Ketten-Kode-Bild-Sprache.
, wobei L(G) die von G erzeugte Sprache (siehe Von G erzeugte Sprache) ist – man nennt sie auch Ketten-Kode-Bild-Sprache.Beispiel
Sei
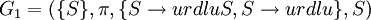 eine gegebene formale Grammatik. Die von G1 erzeugte Sprache ist
eine gegebene formale Grammatik. Die von G1 erzeugte Sprache ist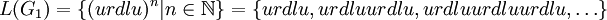 .
.Die Menge dccp(L(G1)) der von G1 erstellten Bilder ist in der nachstehenden Abbildung dargestellt:
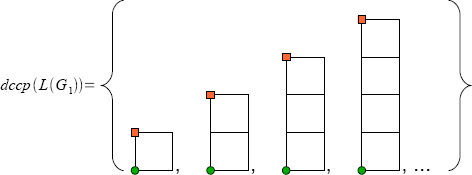 Die Ketten-Kode-Bild-Sprache dccp(L(G1)). Der Anfangspunkt (0,0) eines Bildes ist mit einem grünen Kreis gekennzeichnet und der Endpunkt mit einem orangen Rechteck.
Die Ketten-Kode-Bild-Sprache dccp(L(G1)). Der Anfangspunkt (0,0) eines Bildes ist mit einem grünen Kreis gekennzeichnet und der Endpunkt mit einem orangen Rechteck.Man erhält also abzählbar viele Stapel beliebiger aber fester Höhe, die aus Quadraten der Kantenlänge 1 bestehen.
Hierarchie der Ketten-Kode-Bild-Sprachen
Analog zu formalen Sprachen wird eine Ketten-Kode-Bild-Sprache B regulär oder kontextfrei oder monoton (bzw. kontextsensitiv) oder rekursiv aufzählbar genannt, wenn es eine reguläre oder kontextfreie oder monotone (bzw. kontextsensitive) oder rekursiv aufzählbare formale Grammatik G gibt, sodass B = bccp(L(G)) gilt (siehe Chomsky-Hierarchie). Mit
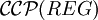 ,
, 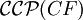 ,
, 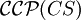 und
und 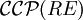 bezeichnet man die Mengen (auch Familien) aller regulären, kontextfreien, monotonen und rekursiv aufzählbaren Ketten-Kode-Bild-Sprachen.
bezeichnet man die Mengen (auch Familien) aller regulären, kontextfreien, monotonen und rekursiv aufzählbaren Ketten-Kode-Bild-Sprachen.Eine wichtige Erkenntnis ist die Gültigkeit der Inklusionen bzw. Gleichheit
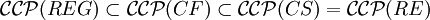 . Somit betrachtet man in der Tat nur drei echte Familien.
. Somit betrachtet man in der Tat nur drei echte Familien.Entscheidungsprobleme für Ketten-Kode-Bild-Sprachen
Klassische Entscheidungsprobleme
Wie für formale Sprachen lassen sich in gleichartiger Weise auch für Ketten-Kode-Bild-Sprachen wichtige Entscheidungsprobleme formulieren:
Bildproblem (auch Mitgliedsproblem)
- Gegeben ist eine formale Grammatik G = (N,π,P,S) und ein Ketten-Kode-Bild p.
- Gilt
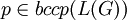 , gibt es also ein Wort
, gibt es also ein Wort 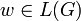 , sodass p = bccp(w) wahr wird?
, sodass p = bccp(w) wahr wird?
Das Bildproblem ist für kontextfreie formale Grammatiken G entscheidbar und für kontextsensitive formale Grammatiken G unentscheidbar. Dabei ist dieses Problem bereits für reguläre formale Grammatiken G NP-vollständig.
1. spezielles Bildproblem
- Gegeben ist eine formale Grammatik G = (N,π,P,S) und ein Ketten-Kode-Bild p.
- Ist die Menge
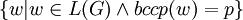 endlich?
endlich?
Man fragt also danach, ob es endlich bzw. unendlich viele Wörter gibt, die das Ketten-Kode-Bild p erzeugen. Dieses Problem ist, wie das Bildproblem, für kontextfreie formale Grammatiken G entscheidbar und für kontextsensitive formale Grammatiken G unentscheidbar.
2. spezielles Bildproblem
- Gegeben ist eine formale Grammatik G = (N,π,P,S) und ein Ketten-Kode-Bild p.
- Hat die Menge genau ein Element?
Somit wird gefragt, ob das Ketten-Kode-Bild p von genau einem Wort w aus L(G) generiert wird. Dieses Problem ist abermals für kontextfreie formale Grammatiken G entscheidbar und für kontextsensitive formale Grammatiken G unentscheidbar.
Unterbildproblem
- Gegeben ist eine formale Grammatik G = (N,π,P,S) und ein Ketten-Kode-Bild p.
- Gibt es ein Ketten-Kode-Bild
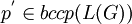 , sodass p ein Unterbild von p' ist?
, sodass p ein Unterbild von p' ist?
Das Unterbildproblem ist für kontextfreie formale Grammatiken G entscheidbar und für kontextsensitive formale Grammatiken G unentscheidbar.
Universelles Unterbildproblem
- Gegeben ist eine formale Grammatik G = (N,π,P,S) und ein Ketten-Kode-Bild p.
- Ist p ein Unterbild jedes Ketten-Kode-Bildes ?
Für reguläre formale Grammatiken G ist das universelle Unterbildproblem entscheidbar.
Leerheitsproblem
- Gegeben ist eine formale Grammatik G = (N,π,P,S).
- Ist die Menge bccp(L(G)) leer?
Das Leerheitsproblem ist für kontextfreie formale Grammatiken G entscheidbar und für kontextsensitive formale Grammatiken G unentscheidbar.
Endlichkeitsproblem
- Gegeben ist eine formale Grammatik G = (N,π,P,S).
- Ist die Menge bccp(L(G)) endlich?
Das Endlichkeitsproblem ist für kontextfreie formale Grammatiken G entscheidbar und für kontextsensitive formale Grammatiken G unentscheidbar.
Äquivalenzproblem
- Gegeben sind zwei formale Grammatiken G1 = (N1,π,P1,S1) und G2 = (N2,π,P2,S2).
- Gilt bccp(L(G1)) = bccp(L(G2)), erzeugen also beide Grammatiken über ihre Wörter dieselben Ketten-Kode-Bilder?
Das Äquivalenzproblem ist schon für reguläre formale Grammatiken G1 und G2 unentscheidbar.
Man beachte, dass auf Grund der in Abschnitt Hierarchie der Ketten-Kode-Bild-Sprachen festgestellten Inklusionen für jedes der genannten Probleme P mit der formalen Grammatik G und X = {REG,CF,CS} gilt:
- wenn P für
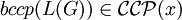 mit
mit 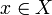 entscheidbar ist, ist P für eine formale Grammatik G' mit
entscheidbar ist, ist P für eine formale Grammatik G' mit 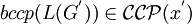 ,
, 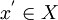 und
und 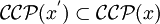 ebenso entscheidbar.
ebenso entscheidbar. - wenn P für mit unentscheidbar ist, ist P für eine formale Grammatik G' mit , und
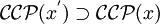 gleichfalls unentscheidbar.
gleichfalls unentscheidbar.
Geometrische Entscheidungsprobleme
Zunächst seien einige geometrische Eigenschaften eines Ketten-Kode-Bilds p im Nachstehenden definiert:
- p ist eine einfache Kurve, wenn alle Knoten von p höchstens den Grad 2 haben.
- p nennt man geschlossene einfache Kurve, wenn alle Knoten von p genau den Grad 2 haben.
- p heißt regulär, wenn alle Knoten von p den gleichen Grad besitzen.
- p wird Baum genannt, wenn es keine geschlossene einfache Kurve als Teilbild enthält.
- p ist eulersch, wenn alle Knoten von p einen graden Grad haben.
- p wird als hamiltonsch bezeichnet, wenn p eine einfache Kurve als Teilbild hat, das alle Knoten von p enthält.
Untersuchungen haben gezeigt, dass bereits für reguläre formale Grammatiken G = (N,π,P,S) unentscheidbar ist, ob bccp(L(G))
- eine einfache Kurve,
- eine geschlossene einfache Kurve,
- ein reguläres Bild,
- einen Baum,
- ein eulersches Bild,
- ein hamiltonsches Bild
beinhaltet.
Hingegen ist für reguläre formale Grammatiken G = (N,π,P,S) entscheidbar, ob
- alle Bilder von bccp(L(G)) geschlossene einfache Kurve sind,
- alle Bilder von bccp(L(G)) Rechtecke sind,
- bccp(L(G)) ein Rechteck enthält,
- bccp(L(G)) ein konvexes Bild enthält.
Weiterhin kann für eine kontextfreie formale Grammatiken G = (N,π,P,S) entschieden werden, ob alle Bilder von bccp(L(G)) Bäume sind.
Verallgemeinerungen
Im Folgenden werden einige (informale) Anmerkungen über Erweiterungen und Verallgemeinerungen von Ketten-Kode-Bildern gemacht, um in gewisser Weise bessere Bilder zu erhalten.
Hinzufügen neuer Richtungen
Ein sicherlich intuitiver Ansatz Ketten-Kode-Bilder zu erweitern, ist das Hinzufügen neuer Richtungen zu den bereits vier bekannten: oben, unten, rechts und links. So können etwa für alle
die Nachbarpunkteur(z) = (m + 1,n + 1), ul(z) = (m − 1,n + 1), dl(z) = (m − 1,n − 1), dr(z) = (m + 1,n − 1),
ergänzt werden. Entsprechend erhält man die zusätzlichen Richtungen oben rechts (up right), oben links (up left), unten rechts (down right) und unten links (down left), und damit das neue Alphabet πF = {u,d,r,l,ur,ul,dl,dr}.
Die oben stehenden unentscheidbaren Probleme bezüglich des Alphabets π bleiben unter dem Alphabet πF ebenfalls unentscheidbar. Für die entscheidbaren Probleme verhält es sich ähnlich.
Farbige Ketten-Kode-Bilder
Will man farbige Ketten-Kode-Bilder erhalten, so kann das Alphabet π wie folgt verändert werden. Statt einfach nur Buchstaben für Richtungen zu verwenden, werden ihnen noch Farben zugewiesen. Sei etwa C eine endliche Mengen von Farben. Dann erhalten wir das neue Alphabet πC mit
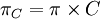 , das heißt die Buchstaben sind Paare der Form (b,c) für und
, das heißt die Buchstaben sind Paare der Form (b,c) für und 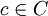 .
.Auch hier erhält man ähnliche Ergebnisse für die Un- und Entscheidbarkeit der obigen Probleme.
Nicht-zusammenhängende Ketten-Kode-Bilder
Ketten-Kode-Bilder sind stets zusammenhängend. Möchte man nicht-zusammenhängende Ketten-Kode-Bilder zulassen, kann man das Alphabet π um zwei Buchstaben erweitern, die gewissermaßen das Ab- und Ansetzen eines Zeichenstifts bedeuten. Das neue Alphabet sei dann
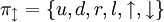 .Intuitiv steht
.Intuitiv steht 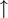 für das Absetzen des Stifts und
für das Absetzen des Stifts und 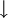 für das Ansetzen. Für ein besseres Verständnis betrachte man das nachstehende von oben abgeänderte Beispiel.
für das Ansetzen. Für ein besseres Verständnis betrachte man das nachstehende von oben abgeänderte Beispiel.Sei
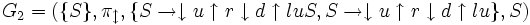
eine gegebene formale Grammatik. Die von G2 erzeugte Sprache ist
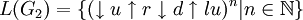 .
.Die erzeugten Bilder sehen denen vom obigen Beispiel ähnlich, nur gibt es keine horizontalen Strecken, da genau dort der Stift immer abgesetzt wurde und bei den vertikalen wieder angesetzt wurde:
 Die Menge der von G2 erzeugten Bilder. Der Anfangspunkt (0,0) eines Bildes ist mit einem grünen Kreis gekennzeichnet und der Endpunkt mit einem orangen Rechteck.
Die Menge der von G2 erzeugten Bilder. Der Anfangspunkt (0,0) eines Bildes ist mit einem grünen Kreis gekennzeichnet und der Endpunkt mit einem orangen Rechteck.Analog zu Ketten-Kode-Bildern kann man auch hier die Familie
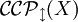 mit X = {REG,CF,CS,RE} der Typen der Chomsky-Hierarchie aufstellen und erhält
mit X = {REG,CF,CS,RE} der Typen der Chomsky-Hierarchie aufstellen und erhält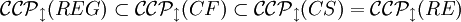
und
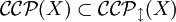 .
.Bezüglich der oben stehenden Entscheidungsprobleme ist die Situation hier aufgrund des Nicht-Zusammenhangs der Bilder deutlich schlechter.
Generierung durch andere Grammatiken
Eine weitere Möglichkeit Ketten-Kode-Bild-Sprachen zu erzeugen, besteht darin andere Grammatiken zu verwenden. So kann man beispielsweise Lindenmayer-Systeme, Schildkröten-Grammatiken, Matrix-Grammatiken und Collage-Grammatiken für die Generierung von Ketten-Kode-Bildern benutzen.
Je nach Art des verwendeten Grammatik-Typs kann es sein, dass gewisse Bilder von keiner Grammatik eines Typs erzeugt werden können, jedoch von einer Grammatik anderen Typs. Insbesondere kann man zeigen, dass es Ketten-Kode-Bilder gibt, die von formalen Grammatiken aber nicht von Collage-Grammatiken produziert werden.
Literatur
- Jürgen Dassow: Grammatical Picture Generation – Manuscript.
- falls w = ε, dann
Wikimedia Foundation.