- Visual Analytics
-
 Die Bandbreite von Visual Analytics [1]
Die Bandbreite von Visual Analytics [1]
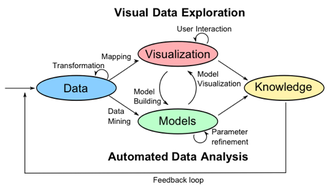 Der Visual Analytics Prozess [2]
Der Visual Analytics Prozess [2]Visual Analytics ist ein interdisziplinärer Ansatz, der die Vorteile aus unterschiedlichen Forschungsgebieten verbindet. Das Ziel der Visual Analytics-Methode ist, Erkenntnisse aus extrem großen und komplexen Datensätzen zu gewinnen. Der Ansatz kombiniert die Stärken der automatischen Datenanalyse mit den Fähigkeiten des Menschen, nämlich schnell Muster oder Trends visuell zu erfassen. Durch geeignete Interaktionsmechanismen können Daten visuell exploriert und Erkenntnisse gewonnen werden. Er wurde 2004 eingeführt und ein Jahr später in dem Buch "Illuminating the Path" beschrieben.[3]
Inhaltsverzeichnis
Motivation
Die stetig wachsende Menge an zu verarbeitenden Daten hat dazu geführt, dass immer größere Speichermedien entwickelt wurden. Häufig wird die gesammelte Datenmenge für die spätere Verarbeitung allerdings weder gefiltert noch bereinigt sondern als Rohdaten abgespeichert. Diese Daten sind für sich genommen nutzlos, können allerdings wichtige Informationen beinhalten. Mit Hilfe des Visual Analytics-Ansatzes wird diese Datenflut elektronisch analysiert, wobei der Mensch stets Einfluss auf die automatisch generierten Ergebnisse hat. Mittels geeigneter interaktiver Visualisierungen kann der Mensch den Analyseprozess beliebig lenken. Im Gegensatz zur reinen Informationsvisualisierung werden dem Menschen also nicht nur Resultate präsentiert, sondern darüber hinaus wird ihm die Möglichkeit gegeben, in die Analyse einzugreifen und die Algorithmen zu beeinflussen.
Prozess
Data: Heterogene Datenquellen müssen vor der visuellen oder automatischen Analyse zuerst vorverarbeitet werden (z.B. bereinigen, normalisieren, etc.).
Models: Mit Hilfe von Data Mining-Techniken werden Modelle der Originaldaten generiert, welche daraufhin zu Evaluationszwecken oder für weitere Verbesserungen visualisiert werden.
Visualization: Um die Modelle durch einen Benutzer zu überprüfen werden Visualisierungen generiert, welche mit Interaktionstechniken für eine Analyse angereichert werden.
Die Vorgehensweise orientiert sich dabei an folgendem Paradigma:
„Analyse First – Show the Important – Zoom, Filter and Analyse Further – Details on Demand“[4]
Dabei ist ein stetiger Wechsel zwischen visuellen und automatischen Vorgängen eine wichtige Eigenschaft des Visual Analytics-Prozesses. Verfälschte Resultate können dadurch frühzeitig erkannt werden, um ein besseres und vertrauenswürdigeres Endergebnis zu erhalten.
Anwendungsgebiete
Anwendungsbereiche in denen große Mengen an Daten verarbeitet und visualisiert werden müssen profitieren von Visual Analytics.
Das sind zum Beispiel:
- Physik und Astronomie. Das Erkennen von unerwarteten Phänomenen in riesigen und dynamischen Datenströmen.
- Katastrophenschutz. Die Analyse einer Notsituation um geeignete Gegenmaßnahmen zu entwickeln, die helfen den Schaden einzugrenzen (Naturkatastrophen, etc.).
- Biologie und Medizin. Die Analyse großer Mengen an Bio-Daten (das menschliche Genom, etc.).
- Business-Intelligence. Analyse von Kundendaten.
Forschungseinrichtungen
- Pacific Northwest National Laboratory (PNNL)
- National Center for Visual Analytics (NCVA)
- Chair for Databases, Data Analysis and Visualization, University of Konstanz
Einzelnachweise
- ↑ Keim D. A, Mansmann F, Schneidewind J, Thomas J, Ziegler H: Visual analytics: Scope and challenges. Visual Data Mining: 2008, S. 76-90.
- ↑ Keim D. A, Kohlhammer J., Ellis, G. P. and Mansmann F.:Mastering The Information Age - Solving Problems with Visual Analytics. Eurographics, 2010.
- ↑ Keim D, North S, Panse C, Sips M: Visual Data Mining in Large Geo-Spatial Point Sets. In: IEEE Computer Graphics and Application. Nr. 12, 2004, S. 36–44.
- ↑ Keim D. A, Mansmann F, Schneidewind J, Thomas J, Ziegler H: Visual analytics: Scope and challenges. Visual Data Mining: 2008, S. 82.
Literatur
- Thomas, J.J. and Cook, K.A. eds., 2005. Illuminating the path: The research and development agenda for visual analytics. IEEE Computer Society


Wikimedia Foundation.