- Fehlerreduktionsmaße
-
Inhaltsverzeichnis
Proportionale Fehlerreduktionsmaße geben indirekt die Stärke des Zusammenhangs zwischen zwei Variablen X und Y an. Definiert werden sie als ,
,wobei E1 der Fehler bei der Vorhersage der abhängigen Variablen Y ohne Kenntnis des Zusammenhangs und E2 der Fehler bei der Vorhersage der abhängigen Variablen Y mit Kenntnis des Zusammenhangs mit X ist.
Da
 gilt, folgt
gilt, folgt  . Ein Wert von Eins bedeutet, dass unter Kenntnis der unabhängigen Variable, der Wert der abhängigen Variable perfekt vorhergesagt werden kann. Ein Wert von Null bedeutet, dass die Kenntnis der unabhängigen Variablen keine Verbesserung in der Vorhersage der abhängigen Variable ergibt.
. Ein Wert von Eins bedeutet, dass unter Kenntnis der unabhängigen Variable, der Wert der abhängigen Variable perfekt vorhergesagt werden kann. Ein Wert von Null bedeutet, dass die Kenntnis der unabhängigen Variablen keine Verbesserung in der Vorhersage der abhängigen Variable ergibt.Der Vorteil ist, dass damit alle proportionalen Fehlerreduktionsmaße in gleicher Weise unabhängig vom Skalenniveau interpretiert werden können. Als Vergleichsmaßstab kann daher das Bestimmtheitsmaß dienen, da es ein proportionales Fehlerreduktionsmaß ist, oder folgende Daumenregel[1]:
- PRE < 0,1: Keine Beziehung,
 : Schwache Beziehung,
: Schwache Beziehung, : Mittlere Beziehung und
: Mittlere Beziehung und : Starke Beziehung.
: Starke Beziehung.
Der Nachteil ist, dass
- die Richtung des Zusammenhangs nicht berücksichtigt werden kann, da Richtungen nur bei ordinalen oder metrischen Skalenniveau angeben werden können und
- die Größe der Fehlerreduktion davon abhängt, wie die Vorhersage unter Kenntnis des Zusammenhangs gemacht wird. Ein kleiner Wert des proportionalen Fehlerreduktionmaßes bedeutet nicht, dass es keinen Zusammenhang zwischen den Variablen gibt.
Da eine Variable abhängig und die andere unabhängig ist, unterscheidet man zwischen symmetrischen und asymmetrischen proportionalen Fehlerreduktionsmaßen:
Skalenniveau der Maß unabhängigen Variable X abhängigen Variable Y Name Bemerkung nominal nominal Goodman und Kruskals λ[2] Es gibt ein symmetrisches und ein asymmetrisches Maß. nominal nominal Goodman und Kruskals τ[2] Es gibt ein symmetrisches und ein asymmetrisches Maß. nominal nominal Unsicherheitskoeffizient oder Theils U[3] Es gibt ein symmetrisches und ein asymmetrisches Maß. ordinal ordinal Goodman und Kruskals γ[2] Es gibt nur ein symmetrisches Maß. nominal metrisch η2 Es gibt nur ein asymmetrisches Maß. metrisch metrisch Bestimmtheitsmaß R2 Es gibt nur ein symmetrisches Maß. Bestimmtheitsmaß
Für die Vorhersage unter Unkenntnis des Zusammenhangs zwischen zwei metrischen Variablen X und Y dürfen nur Werte der abhängigen Variablen Y benutzt werden. Der einfachste Ansatz ist
 und mit
und mit  gilt und es folgt
gilt und es folgt  dem arithmetische Mittel. Daher ist der Vorhersagefehler unter Unkenntnis des Zusammenhangs
dem arithmetische Mittel. Daher ist der Vorhersagefehler unter Unkenntnis des Zusammenhangs .
.Für die Vorhersage unter Kenntnis des Zusammenhangs nutzen wir die lineare Regression
 aus:
aus:
 .
.Das Bestimmtheitsmaß R2 ist dann ein proportionales Fehlerreduktionsmaß, da gilt

Werden die Rollen der abhängigen und unabhängigen Variable vertauscht, so ergibt sich der gleiche Wert für R2. Daher gibt es nur ein symmetrisches Maß.
Goodman und Kruskals λ und τ
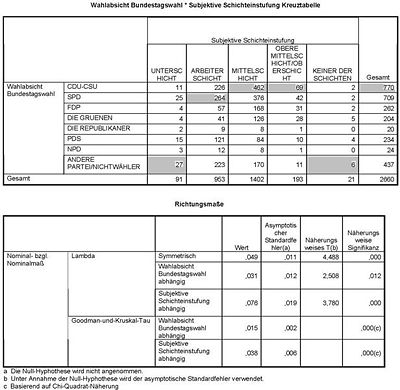 Berechnung von Goodman und Kruskals λ und τ für die Variablen "Subjektive Schichteinstufung des Befragten" und "Wahlabsicht in der Bundestagswahl" der ALLBUS Daten 2006.
Berechnung von Goodman und Kruskals λ und τ für die Variablen "Subjektive Schichteinstufung des Befragten" und "Wahlabsicht in der Bundestagswahl" der ALLBUS Daten 2006.
Goodman und Kruskals λ
Die Vorhersage unter Unkenntnis des Zusammenhangs ist die Modalkategorie der abhängigen Variable und der Vorhersagefehler

mit hM die absolute Häufigkeit in der Modalkategorie und n die Anzahl der Beobachtungen.
Die Vorhersage unter Kenntnis des Zusammenhangs ist die Modalkategorie der abhängigen Variable in Abhängigkeit von den Kategorien der unabhängigen Variablen und der Vorhersagefehler ist

mit
 die absolute Häufigkeit für die jeweilige Kategorie der unabhängigen Variablen und hM,j die absolute Häufigkeit der Modalkategorie in Abhängigkeit von den Kategorien der unabhängigen Variablen.
die absolute Häufigkeit für die jeweilige Kategorie der unabhängigen Variablen und hM,j die absolute Häufigkeit der Modalkategorie in Abhängigkeit von den Kategorien der unabhängigen Variablen.Beispiel
Im Beispiel rechts ergibt sich für die abhängige Variable "Wahlabsicht Bundestagswahl" bei Unkenntnis des Zusammenhangs als der Vorhersagewert "CDU/CSU" und damit eine Fehlervorhersage E1 = 1 − 770 / 2660 = 0,711.
Je nach Ausprägung der Variablen "Subjektive Schichteinstufung" ergibt sich für die abhängige Variable "Wahlabsicht Bundestagswahl" der Vorhersagewert "CDU/CSU" (Kategorie: Mittelschicht, Obere Mittelschicht/Oberschicht), "SPD" (Kategorie: Arbeiterschicht) oder "Andere Partei/Nichtwähler" (alle anderen Kategorien). Der Vorhersagefehler E2 = 91 / 2660 * (1 − 27 / 91) + 953 / 2660 * (1 − 264 / 953) + ... + 21 / 2660 * (1 − 6 / 21) = 0,689 und λ = 1 − 0,689 / 0,711 = 0,031.
Das heißt, im vorliegende Beispiel kann der Fehler bei der Vorhersage der Wahlabsicht der Bundestagswahl des Befragten um 3,1% reduziert werden, wenn man seine eigene subjektive Schichteinstufung kennt.
Goodman und Kruskals τ
Bei Goodman und Kruskals τ wird als Vorhersagewert statt der Modalkategorie ein zufälliger gezogener Wert aus der Verteilung von Y angenommen, d.h. mit Wahrscheinlichkeit
 wird Kategorie 1 gezogen, mit Wahrscheinlichkeit
wird Kategorie 1 gezogen, mit Wahrscheinlichkeit  wird Kategorie 2 gezogen und so weiter. Der Vorhersagefehler ergibt sich dann als
wird Kategorie 2 gezogen und so weiter. Der Vorhersagefehler ergibt sich dann als
mit
 die absolute Häufigkeit der Kategorie k der abhängigen Variablen. Analog ergibt sich der Vorhersagefehler E2, nur das jetzt die Vorhersage entsprechend für jede Kategorie der unabhängigen Variablen gemacht wird und der Vorhersagefehler E2 ergibt sich als Summe der gewichteten Vorhersagefehler in jeder Kategorie der unabhängigen Variablen.
die absolute Häufigkeit der Kategorie k der abhängigen Variablen. Analog ergibt sich der Vorhersagefehler E2, nur das jetzt die Vorhersage entsprechend für jede Kategorie der unabhängigen Variablen gemacht wird und der Vorhersagefehler E2 ergibt sich als Summe der gewichteten Vorhersagefehler in jeder Kategorie der unabhängigen Variablen.
mit hk,j die absolute Häufigkeit für das gemeinsame Auftreten der Kategorien i und j.
Symmetrische Maße
Für Goodman und Kruskals λ und τ können die Vorhersagefehler
 und
und  , wenn Y die abhängige Variable ist, und
, wenn Y die abhängige Variable ist, und und
und  , wenn X die abhängige Variable ist,
, wenn X die abhängige Variable ist,
berechnet werden. Die symmetrischen Maße für Goodman und Kruskals λ und τ ergeben sich dann als
 .
.Unsicherheitskoeffizient
Entropie
Der Unsicherheitskoeffizient misst die Unsicherheit der Information mit Hilfe der Entropie. Wenn fk die relative Häufigkeit des Auftretens der Kategorie k ist, dann ist die Entropie oder Unsicherheit definiert als

Die Unsicherheit U ist Null, wenn für alle möglichen Kategorien bis auf eine fk = 0 ist. Die Vorhersage, welchen Kategorienwert eine Variable annimmt, ist dann trivial. Ist fk = 1 / k (Gleichverteilung), dann ist die Unsicherheit U = log(k) und auch maximal.
Asymmetrischer Unsicherheitskoeffizient
Das Fehlermaß unter Unkenntnis des Zusammenhangs ist daher die Unsicherheit UY für die abhängige Variable

Das Fehlermaß unter Kenntnis des Zusammenhangs ist die gewichtete Summe der Unsicherheit für jede Kategorie der abhängigen Variablen
![E_2 = \sum_j \frac{h_{\bullet,j}}{n} \underbrace{\left[-\sum_k \frac{h_{k,j}}{h_{\bullet,j}} \log\left(\frac{h_{k,j}}{h_{\bullet,j}}\right)\right]}_{\begin{matrix}\mbox{Unsicherheit in Kategorie j} \\ \mbox{der unabhängigen Variable}\end{matrix}}.](8/1f8aee11c3a157191df439f75ac7cf8a.png)
Dieser Ausdruck lässt auch schreiben als
![E_2 = U_{XY}-U_X = \left[-\sum_{j,k} \frac{h_{k,j}}{n} \log\left(\frac{h_{k,j}}{n}\right)\right]-\left[-\sum_j\frac{h_{\bullet,j}}{n} \log\left(\frac{h_{\bullet,j}}{n}\right)\right]](b/ecb057af25b1972db6a92590c3aee9b7.png)
mit UXY die Unsicherheit basierend auf der gemeinsamen Verteilung von X und Y und UX die Unsicherheit der unabhängigen Variable X.
Der Unsicherheitskoeffizient ergibt sich dann als

Symmetrischer Unsicherheitskoeffizient
Für den Unsicherheitskoeffizient können die Vorhersagefehler
- und , wenn Y die abhängige Variable ist, und
- und , wenn X die abhängige Variable ist,
berechnet werden. Der symmetrische Unsicherheitskoeffizient ergibt sich, wie bei Goodman and Kruskals λ und τ, als
 .
.Goodman und Kruskals γ
C sei die Zahl konkordanten Paare (xi < xj und yi < yj) und D die Zahl diskordanten Paare (xi < xj und yi > yj). Wenn wir keine gemeinsamen Rangzahlen (Ties) haben und n die Anzahl der Beobachtungen ist, dann gilt C + D = n(n − 1) / 2.
Unter Unkenntnis des Zusammenhangs können wir keine Aussage darüber machen, ob ein Paar konkordant oder diskordant ist. Daher sagen wir Wahrscheinlichkeit 0,5 ein konkordantes bzw. diskordantes Paar vorher. Der Gesamtfehler für alle möglichen Paare ergibt sich als

Unter Kenntnis des Zusammenhangs wird immer Konkordanz vorhergesagt, falls
 , oder immer Diskordanz, wenn C < D. Der Fehler ist
, oder immer Diskordanz, wenn C < D. Der Fehler ist
und es folgt

Der Betrag von Goodman and Kruskals γ ist damit ein symmetrisches proportionales Fehlerreduktionsmaß.
η2
 Berechnung von η für die Variablen "Nettoeinkommen des Befragten" (abhängig) und "Subjektive Schichteinstufung des Befragten" (unabhängig) der ALLBUS Daten 2006.
Berechnung von η für die Variablen "Nettoeinkommen des Befragten" (abhängig) und "Subjektive Schichteinstufung des Befragten" (unabhängig) der ALLBUS Daten 2006.Wie bei dem Bestimmtheitsmaß ist der Vorhersagewert für die abhängige metrische Variable unter Unkenntnis des Zusammenhangs
 und der Vorhersagefehler
und der Vorhersagefehler .
.Bei Kenntnis zu welcher der Gruppen der nominale oder ordinale unabhängigen Variable die Beobachtung gehört, ist der Vorhersagewert gerade der Gruppenmittelwert
 . Der Vorhersagefehler ergibt sich als
. Der Vorhersagefehler ergibt sich als mit
mit 
, wenn die Beobachtung i zur Gruppe k gehört und sonst Null. Damit ergibt sich
 .
.Die Rollen der abhängigen und unabhängigen Variablen kann nicht vertauscht werden, da sie unterschiedliches Skalenniveau haben. Deswegen gibt es nur ein (asymmetrisches) Maß.
In Cohen (1998)[1] wird als Daumenregel angegeben:- η2 < 0,01 kein Zusammenhang,
 geringer Zusammenhang,
geringer Zusammenhang, mittlerer Zusammenhang und
mittlerer Zusammenhang und starker Zusammenhang.
starker Zusammenhang.
Beispiel
In dem Beispiel kann der Fehler bei der Vorhersage des Nettoeinkommens bei Kenntnis der Schichteinstufung um 0,3062 = 0,094, also knapp 10%, reduziert werden. Das zweite η ergibt sich, wenn man die Rolle der Variablen vertauscht, was aber hier unsinnig ist. Daher muss dieser Wert ignoriert werden.
Literatur
- Y.M.M. Bishop, S.E. Feinberg, P.W. Holland (1975). Discrete Multivariate Analysis: Theory and Practice. Cambridge, MA: MIT Press.
- L.C. Freemann (1986). Order-based Statistics and Monotonicity: A Family of Ordinal Measures of Association. Journal of Mathematical Sociology, 12(1), S. 49-68
- J. Bortz (2005). Statistik für Human- und Sozialwissenschaftler (6. Auflage), Springer Verlag.
- B. Rönz (2001). Skript "Computergestützte Statistik II", Humboldt-Universität zu Berlin, Lehrstuhl für Statistik.
Einzelnachweise
- ↑ a b J. Cohen (1988). Statistical Power Analysis for Behavioral Science. Erlbaum, Hilsdale
- ↑ a b c L.A. Goodman, W.H. Kruskal (1954). Measures of association for cross-classification. Journal of the American Statistical Association, 49, S. 732-764.
- ↑ H. Theil (1972), Statistical Decomposition Analysis, Amsterdam: North-Holland Publishing Company (diskutiert den Unsicherheitskoeffizient).

Wikimedia Foundation.