- Fuzzy C-Means
-
Der Fuzzy C-Means Algorithmus ist ein unüberwachter Clustering-Algorithmus, der eine Erweiterung des k-Means Clustering Algorithmus ist. In einer generalisierten Form wurde er von Bezdek (1981) vorgestellt.[1]
Inhaltsverzeichnis
Grundidee
Im k-Means Clustering wird die Zahl der Cluster C zunächst festgelegt (im k-Means Clustering wird die Zahl der Cluster mit k statt mit C bezeichnet). Im ersten Schritt werden zufällig Clusterzentren vi (Kreise unten in der Grafik) festgelegt. Im zweiten Schritt wird jedes Objekt (Rechtecke unten in der Grafik) dem nächsten Clusterzentrum zugeordnet. Danach werden die (quadrierten) Abstände zwischen jedem Objekt und seinem zugeordneten Clusterzentrum berechnet und für alle Beobachtungen aufsummiert (Jkmeans). Das Ziel ist es den Wert von Jkmeans so klein wie möglich zu machen, d.h. Positionen für die Clusterzentren zu finden, so dass der Abstand zwischen jedem Objekt und seinem zugehörigen Clusterzentrum klein ist. Im dritten Schritt werden daher die Clusterzentren aus den Objekten, die zu einem Cluster gehören, neu berechnet. Im vierten Schritt wird wieder jedem Objekt sein nächstes Clusterzentrum zugeordnet. Dieses Verfahren wird iteriert bis sich eine stabile Lösung findet. Wie die folgende Grafik zeigt, können Objekte im Verlauf des Iterationsprozesses durchaus verschiedenen Clustern zugeordnet werden; vergleiche die Grafik zu Schritt 2 und Schritt 4.
- k-Means Clustering
-
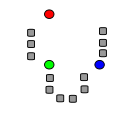
Schritt 1: Zufällige Wahl der Clusterzentren
-
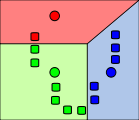
Schritt 2: Zuordnung der Objekte zu einem Clusterzentrum
-

Schritt 3: Neuberechnung der Clusterzentren
-
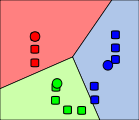
Schritt 4: Erneute Zuordnung der Objekte zu einem Clusterzentrum
Der Nachteil des k-Means Clustering ist, dass jedes Objekt in jedem Schritt eindeutig einem Clusterzentrum zugeordnet wird. Das führt dazu, dass die endgültige Lösung stark von der Wahl der Position der Clusterzentren am Anfang abhängen kann. Natürlich ist man an einer eindeutigen Lösung interessiert, möglichst unabhängig von der Position der Clusterzentren am Anfang,
Im Fuzzy C-Means wird daher jedes Objekt nicht eindeutig einem Clusterzentrum zugeordnet sondern jedem Objekt wird ein Satz Gewichte
 zugeordnet, die angeben wie stark die Zugehörigkeit zu einem bestimmten Cluster ist. Z.B könnte für das rote Objekt in Schritt 2 die Gewichte
zugeordnet, die angeben wie stark die Zugehörigkeit zu einem bestimmten Cluster ist. Z.B könnte für das rote Objekt in Schritt 2 die Gewichte- ublau = 0,1 für den blauen Cluster
- ugruen = 0,1 für den grünen Cluster und
- urot = 0,8 für den roten Cluster sein.
Diese Gewichte werden dann auch benutzt um den gewichteten Abstand zu allen Clusterzentren zu berechnen. In der Endlösung werden dann Objekte, die nahe einem bestimmten Clusterzentrum liegen, große Gewichte für diesen Cluster haben. Das blaue Objekt nahe dem blauen Clusterzentrum in Schritt 4 könnte z.B. die Gewichte ublau = 0,90, ugruen = 0,05 und urot = 0,05 haben. Die beiden blauen Objekte nahe der Grenze zum grünen Cluster könnten dann z.B. die Gewichte ublau = 0,5, ugruen = 0,45 und urot = 0,05 haben.
Die Gewichte
für jedes Objekt stellen sogenannte Fuzzy-Zahlen dar. Die Gewichte müssen sich auch nicht für jedes Objekt zu Eins aufaddieren (wie es in diesem Abschnitt zum besseren Verständnis gemacht wurde). Aus der Ableitung vom k-Means Clustering stammt auch der Name Fuzzy C-Means.Mathematische Beschreibung des Algorithmus
Der Begriff fuzzy beschreibt dabei eine Methode der Clusteranalyse, die es erlaubt, ein Objekt mehr als nur einem Cluster zuzuordnen. Ermöglicht wird dies dadurch, dass ein Grad der Zugehörigkeit (membership degree) uik des Objekts xk (k = 1,...,N) zu jedem Cluster i (i = 1,...,C) verwendet wird. Jedes uik liegt dabei im Intervall [0,1]. Je größer uik, desto stärker ist die Zugehörigkeit von xk zu i.
Die Zielfunktion des Fuzzy C-Means-Algorithmus lautet:
Dabei gibt
 die quadrierten (euklidischen) Distanzen zwischen den Punkten xk und den Clusterzentren (Prototypen) vi aus der Matrix V an. Die Partitionsmatrix U gibt die membership degrees uik wieder. C ist die Anzahl an Clustern und N die Größe des Datensatzes. Der "fuzzifier" m(>1) bestimmt, wie scharf die Objekte den Clustern zugeordnet werden. Lässt man m gegen unendlich laufen, so nähern sich die uik dem Wert
die quadrierten (euklidischen) Distanzen zwischen den Punkten xk und den Clusterzentren (Prototypen) vi aus der Matrix V an. Die Partitionsmatrix U gibt die membership degrees uik wieder. C ist die Anzahl an Clustern und N die Größe des Datensatzes. Der "fuzzifier" m(>1) bestimmt, wie scharf die Objekte den Clustern zugeordnet werden. Lässt man m gegen unendlich laufen, so nähern sich die uik dem Wert  an, d.h. die Zugehörigkeit der Punkte ist zu allen Clustern gleich groß. Liegt m nahe bei 1, so ist das Clustering scharf, d.h. die Zugehörigkeiten liegen näher bei 0 oder 1. In der Praxis haben sich für m Werte zwischen 1 und 2,5 als geeignet herausgestellt (vgl. Stutz (1999)). Die Werte uik und vi werden durch Minimierung der Zielfunktion J bestimmt. Die Objekte werden den Clustern also so zugeordnet, dass die Summe der quadrierten Abstände
an, d.h. die Zugehörigkeit der Punkte ist zu allen Clustern gleich groß. Liegt m nahe bei 1, so ist das Clustering scharf, d.h. die Zugehörigkeiten liegen näher bei 0 oder 1. In der Praxis haben sich für m Werte zwischen 1 und 2,5 als geeignet herausgestellt (vgl. Stutz (1999)). Die Werte uik und vi werden durch Minimierung der Zielfunktion J bestimmt. Die Objekte werden den Clustern also so zugeordnet, dass die Summe der quadrierten Abstände  minimal wird. Die Optimierung findet unter Nebenbedingungen statt:
minimal wird. Die Optimierung findet unter Nebenbedingungen statt:- Für jeden Punkt ist die Summe der Zugehörigkeiten zu allen Clustern gleich 1, d.h. für alle k gilt
 ,
, - Die Cluster sind nicht-leer, d.h. für alle i gilt
 0" border="0">.
0" border="0">.
Zur Lösung des Minimierungs-Problems wird das Lagrangeverfahren angewandt. Die Lagrangefunktion
wird nach u,v, und λ abgeleitet. Als Lösung ergibt sich:
und
Der Algorithmus besteht dann aus den folgenden Schritten:
- Initialisiere eine Start-Partitionsmatrix U0
- Berechne die Prototypen Vr = [vi] im Iterationsschritt r
- Berechne die Partitionsmatrix Ur = [uik] im Iterationsschritt r
- Falls
 dann Stopp. Sonst zurück zu Schritt 2
dann Stopp. Sonst zurück zu Schritt 2
Dabei gibt
 einen kleinen Schwellenwert an.
einen kleinen Schwellenwert an.Beispiel
 1000 Schweizer Franken Banknote.
1000 Schweizer Franken Banknote.
Der Schweizer Banknoten Datensatz besteht 100 echten und 100 gefälschten Schweizer 1000 Franken Banknoten.[2] An jeder Banknote wurden sechs Variablen erhoben:
- Die Breite der Banknote (WIDTH),
- die Höhe an der Banknote an der linken Seite (LEFT),
- die Höhe an der Banknote an der rechten Seite (RIGHT),
- der Abstand des farbigen Drucks zur Oberkante der Banknote (UPPER),
- der Abstand des farbigen Drucks zur Unterkante der Banknote (LOWER) und
- die Diagonale (links unten nach rechts oben) des farbigen Drucks auf der Banknote (DIAGONAL).
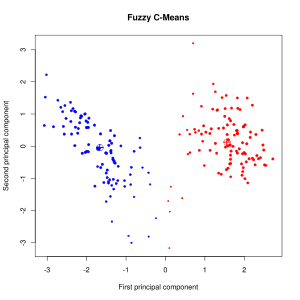
Die beiden Grafiken unten zeigen das Ergebnis der k-Means Cluster Analyse (links) und der Fuzzy C-Means Cluster Analyse (rechts) auf den ersten beiden Hauptkomponenten der Schweizer Banknoten Daten. Die beiden Clusterzentren sind in beiden Grafiken jeweils mit dem Kreuz im Kreis markiert. Der kompakte Cluster rechts enthält die echten Banknoten und der Rest sind die gefälschten Banknoten.
- K-means Clustering
- Im k-Means Clustering sind die echten und falschen Banknoten fast richtig klassifiziert worden. Nur eine falsche Banknote ist dem blauen Cluster zugeordnet worden. Dabei ist beachten, dass das Clustering mit allen sechs Variablen stattgefunden hat während die Grafik nur zwei Dimensionen darstellt.
- Fuzzy C-Means Clustering
- Hier sind noch mehr Beobachtungen (in der Mitte unten) dem Cluster mit den echten Banknoten zugeordnet worden. Auf den ersten Blick scheint das Fuzzy C-Means Clustering schlechter zu sein als das k-Means Clustering. Die Grösse der Datenpunkte in der Grafik gibt jedoch den Wert der Membership Funktion an: Je größer der Datenpunkt desto eindeutiger wird er einem Cluster zugeordnet, je kleiner der Datenpunkt desto unsicherer ist der Algorithmus über die Zuordnung zu einem Cluster. Betrachtet man die Datenpunkte unten in der Mitte, so sieht man, das sowohl im roten als auch im blauen Cluster die Datenpunkte sehr klein sind, d.h. die Werte der Membershipfunktion liegen hier für beide Cluster bei ca. 0,5. Also ist sich der Fuzzy C-Means eigentlich sehr unsicher darüber welchem Cluster diese Datenpunkte zuzuordnen sind.
- Tatsächlich ist es so, dass die echten Banknoten von einer Vorlage (Druckplatte) gedruckt wurden während die gefälschten Banknoten aus verschiedenen Quellen und damit wahrscheinlich auch von verschiedenen gefälschten Druckplatten stammen.
Ergebnis der k-Means Cluster Analyse (links) und der Fuzzy C-Means Cluster Analyse (rechts) auf den Schweizer Banknoten Daten. 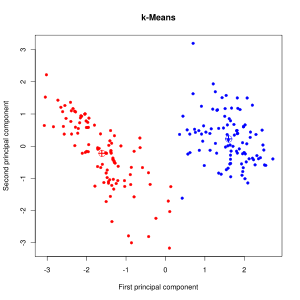
Einzelnachweise
- ↑ J.C. Bezdek: Pattern recognition with fuzzy objective function algorithms. Plenum Press, New York 1981.
- ↑ Bernhard Flury, Hans Riedwyl: Multivariate Statistics : A Practical Approach. 1. Auflage. Chapman & Hall, London 3. März 1988, ISBN 978-0412300301.
Literatur
- Christiane Stutz: Anwendungsspezifische Fuzzy-Clustermethoden (Dissertation zur künstlichen Intelligenz, TU München). Infix, Sankt Augustin 1999.
Weblinks
- A Tutorial on Clustering Algorithms: Online Tutorial mit interaktivem Demo für den Fuzzy C-Means Algorithmus.
- Fuzzy C-means cluster analysis: Artikel auf Scholarpedia (englisch)











Wikimedia Foundation.