- R*-Baum
-
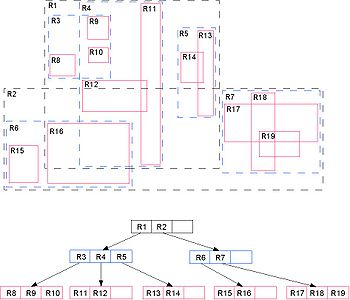 Ein Beispiel eines R-Baums
Ein Beispiel eines R-BaumsEin R-Baum (eng. R-tree) ist eine in Datenbanksystemen verwendete räumliche (man sagt auch mehrdimensionale) Indexstruktur.
Inhaltsverzeichnis
Verwendungszweck
Ein R-Baum erlaubt die schnelle Suche in mehrdimensionalen Daten. Dazu gehören Polygone im zweidimensionalen Raum und geometrische Körper im dreidimensionalen Raum. Typisch sind aber auch hochdimensionale Objekte, wie sie in der Mathematik oder Bioinformatik vorkommen. Hochdimensional bedeutet hierbei, dass die Anzahl der unabhängigen Suchkriterien in der Größenordnung von 100 - 1.000.000 liegt.
Typisches Einsatzgebiet eines R-Baum-Index sind Geodatenbanken. Hier werden z. B. Straßendaten, Grenzbereiche oder Gebäudedaten verwaltet. Diese werden als Polygone in der Datenbank gespeichert. Der R-Baum erlaubt später das effiziente Auffinden bestimmter Polygone anhand der Ortskoordinaten.
Realisierung
Ähnlich zu einem B*-Baum enthalten Blattknoten eines R-Baumes die zu indizierenden räumlichen Daten. Im Falle von zweidimensionalen Daten sind dies Polygone. Die Indexknoten enthalten rechteckige Datenregionen (minimal umgebende Rechtecke), die alle im Teilbaum darunter liegenden Datenregionen umfassen.
Realisiert wird die Speicherung eines Rechtecks durch die Angabe von Intervallen für alle seine Dimensionen. Mithilfe eines R-Baumes können Punkt- oder Enthaltenseinanfragen wie „ist Punkt P in Figur F enthalten?“, „ist Figur F1 in Figur F2 enthalten?“ oder „welche Figuren sind in Figur F enthalten?“ beantwortet werden. Durch die verwendete Näherung (minimal umgebende Rechtecke) in den Blattknoten kann es zu Fehltreffern kommen, die durch Überprüfung der Anfrage an den konkreten Polygonen aufgelöst werden müssen.
R*-Baum
Eine verbesserte Variante ist der R*-Baum. R*-Bäume haben dieselbe Struktur wie R-Bäume, verwenden jedoch einen weiterentwickelten Algorithmus zum Unterteilen minimal überdeckender Rechtecke.
Im R-Baum konnten sich die Suchräume noch überlappen. Das ist im R*-Baum nicht erlaubt (die Suchräume sind hier disjunkt). Umschließende Rechtecke werden falls notwendig an den Suchraumgrenzen "abgetrennt". Hierbei können auch Objekte "zerschnitten" werden, so dass ein Teil des Objekts sich im einen Suchraum und ein anderer Teil des Objekts sich im anderen Suchraum befindet.
Dies führt zu einem besseren Laufzeitverhalten beim Aufteilen und Suchen sowie zu einem höheren Füllgrad der Indexknoten, also zu einer besseren Speicherausnutzung. Entscheidend ist jedoch die größere Robustheit gegen Entarten der Baum-Struktur.
Siehe auch
Quadtree, K-d-Baum, UB-Baum, Bereichsbaum, Gridfile als Alternative
Literatur
- Antonin Guttman: R-Trees: A Dynamic Index Structure for Spatial Searching, Proc. ACM SIGMOD International Conference on Management of Data
- Norbert Beckmann, H.-P. Kriegel, R. Schneider, B. Seeger: The R*-Tree: An Efficient and Robust Access Method for Points and Rectangles. SIGMOD Conference 1990: 322-331
Weblinks

Wikimedia Foundation.