- Shared Memory
-
Shared Memory (dt. „gemeinsam genutzter Speicher“) wird in der Computertechnologie verwendet und kann dabei je nach Kontext eine andere Technologie beschreiben:
- Shared Memory in der Interprozesskommunikation (IPC): Hier nutzen zwei oder mehrere Prozesse einen bestimmten Teil des Hintergrundspeichers (RAM) gemeinsam.
- Shared Memory in Mehrprozessorsystemen: Hierbei teilen sich die Prozessoren des Mehrprozessorsystems einen gemeinsamen Speicher.
- Shared Memory bei Grafikkarten: Hierbei können Grafikkarten einen Teil des Hauptspeichers des Systems für sich nutzen.
Inhaltsverzeichnis
Hier nutzen zwei oder mehrere Prozesse einen bestimmten Teil des Hintergrundspeichers (RAM) gemeinsam. Für alle beteiligten Prozesse liegt dieser gemeinsam genutzte Speicherbereich in deren Adressraum und kann mit normalen Speicherzugriffsoperationen ausgelesen und verändert werden. Meist wird dies über Pagingmechanismen realisiert, indem beide Prozesse gleiche Seitendeskriptoren verwenden, wodurch die gleiche Speicherseite (Kachel) im Hintergrundspeicher verwendet wird. Die meisten modernen Betriebssysteme bieten Mechanismen zur gemeinsamen Speichernutzung an.
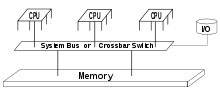
Bei MIMD (Multiple Instruction, Multiple Data)-Architekturen unterscheidet man eng gekoppelte und lose gekoppelte Systeme, wobei Mehrprozessorsysteme zur Klasse der eng gekoppelten Systeme gehören. In eng gekoppelten Mehrprozessorsystemen teilen sich die verschiedenen Prozessoren einen gemeinsamen Speicher (Shared Memory). Gegenüber lose gekoppelten MIMD-Architekturen hat dies folgende Vorteile:
- die Prozessoren haben alle dieselbe Sicht auf die Daten und können daher auf einfache Art und Weise miteinander kommunizieren
- der Zugriff auf den gemeinsamen Speicher erfolgt sehr schnell
Aus diesen Gründen ist ein eng gekoppeltes MIMD-System in der Regel einfacher zu programmieren als ein lose gekoppeltes MIMD-System. Allerdings kann der gemeinsam genutzte Speicher auch schnell zum Flaschenhals werden, wenn zu viele Prozessoren vorhanden sind, da (bei einem gemeinsam genutztem Speicherbus) zu einer Zeit immer nur ein Prozessor auf den Speicher zugreifen kann. Um dem entgegenzuwirken, werden in der Regel Caches verwendet, d.h. die Prozessoren speichern einmal gelesene Werte in einem eigenem, privatem Speicher ab und müssen diese nur dann aktualisieren, wenn sie selbst oder ein anderer Prozessor diese verändert haben. Um auch dies möglichst effizient zu bewerkstelligen, kommen Techniken wie beispielsweise Bus Snooping und Durchschreibe-Caches (engl.: write-through-caches) zum Einsatz.
Verbindungsorientierte Mehrprozessorsysteme
Selbst beim Einsatz der oben genannten Techniken kann die beschriebenen busorientierten Mehrprozessorsysteme nicht besonders gut skaliert (d.h. um weitere Prozessoren erweitert) werden, da jeder hinzugefügte Prozessor die Anzahl der Zugriffe auf den Bus erhöht. Irgendwann ist die Kapazität des Busses ausgeschöpft. Aus diesem Grunde wurde das Konzept der verbindungsorientierten Mehrprozessorsysteme entwickelt. Hierbei blockiert der Zugriff eines Prozessors auf den Speicher nicht den gesamten Speicher, sondern nur einen Teil davon. Dies wird erreicht, indem Technologien wie Kreuzschienenverteiler oder Omega-Netzwerke zum Einsatz kommen. Diese Technologien sind allerdings teuer, weshalb man in der Praxis zur Steigerung der Rechenleistung anstelle von (eng gekoppelten) verbindungsorientierten Mehrprozessorsystemen eher lose gekoppelte MIMD-Architekturen wie beispielsweise Computercluster verwendet.
siehe auch
 Shared Memory
Shared Memory
Einige Grafikkartenhersteller bieten Grafikkarten mit „Shared-Memory-Technologie“ an, dabei handelt es sich allerdings nicht um den genannten IPC-Mechanismus, sondern um ein Verfahren, bei dem die Grafikkarte den Hauptspeicher eines Computers mitbenutzt, auch als Integrated Graphics Processor bezeichnet. Dies kann einerseits eine Verlangsamung der Grafikhardware und der CPU zur Folge haben, weil nun der Speicherbus zum Flaschenhals werden kann. Andererseits hat es aber den Vorteil, dass die Grafikkarte zumeist billiger verkauft werden kann, weil sie keinen eigenen Speicher benötigt. Diese Technologie kommt überwiegend bei Notebooks zum Einsatz, wobei hierbei sogar weitere Vorzüge anzuführen sind. Durch das Einsparen von zusätzlichen Grafik-Speicher-Chips wird eine bessere Energieeffizienz erreicht und verhilft Notebooks damit in der Regel zu einer längeren Akkulaufzeit. Zudem bieten nahezu alle Shared-Memory-Anbieter, wie auch die Intel-GMA-Modelle, eine variable Nutzung des Hauptspeichers. So können zwar 256 MB angesprochen und genutzt werden, normalerweise wird jedoch nur ein Bruchteil belegt (z. B. 16 MB). Bei AMD heißt der gemeinsam genutzte Speicher UMA, wobei stets auf Techniken hingewiesen wird, die das Problem Speicherdurchsatz reduzieren.
Verstärkt kommt Shared-Memory-Technologie somit bei Business-Notebooks, ultra-portablen Notebooks (Subnotebooks) oder preiswerten Notebooks zum Einsatz. In aktuellen Systemen ist man dazu übergegangen, den Hauptspeicher über Dual-Channel-Speichercontroller anzusprechen, wodurch die Bandbreite erhöht wird. Dadurch soll die Flaschenhalsproblematik gedämpft werden, so dass beide Prozessoren schnell darauf zugreifen können.
Weiterentwicklungen
Die Bezeichnungen TurboCache (NVidia) und HyperMemory (ATI) sind marketingtechnisch aufgewertete Begriffe für Technologien bei Grafikkarten, die Shared Memory einsetzen. Sie kombinieren das Shared-Memory-Konzept mit einem (aus Kostengründen vergleichsweise kleinen) grafikkarten-eigenen Speicher, dadurch steht neben einem großen Shared Memory auch ein schneller Lokalspeicher zur Verfügung.

Wikimedia Foundation.