- Verfahren von Quine und McCluskey
-
Das Verfahren nach Quine und McCluskey (QMCV, nach Willard Van Orman Quine und Edward J. McCluskey) ist eine Methode, um Boolesche Funktionen zu minimieren. Der Kern des Verfahrens wurde bereits von Quine vollständig beschrieben. Die Verfeinerungen von McCluskey betreffen im wesentlichen die praktische algorithmische Durchführbarkeit. Die Minimierung ist u. a. deshalb wichtig, weil dadurch die hardwaretechnische Realisierung einfacher und daher kostengünstiger wird. Der Vorteil dieses Verfahrens ist, dass es sich verhältnismäßig leicht in ein Computerprogramm fassen und so mittels eines Computers ausführen lässt. Das Verfahren benötigt im schlechtesten Fall exponentielle Laufzeit, um eine minimale Lösung zu finden. Das Verfahren findet immer eine minimale Lösung, es ist jedoch möglich, dass es noch andere (gleichwertige) Lösungen gibt, die nicht gefunden werden. Da das zugrunde liegende Problem NP-vollständig ist, und unter der Annahme, dass P!=NP gilt, gibt es kein in diesem Sinne effizientes Verfahren.
Das Verfahren bezieht sich zunächst nur auf Funktionsdarstellungen in kanonischer disjunktiver Normalform (KDNF). Ausdrücke in konjunktiver Normalform (KNF) lassen sich jedoch ohne weiteres über die Verneinung der betrachteten Funktion zunächst in eine DNF umwandeln, dann wie unten beschrieben minimieren und schließlich durch erneute Verneinung in eine KNF zurücktransformieren.
Inhaltsverzeichnis
Beschreibung des Verfahrens
Grundprinzip
Das Grundprinzip des Quine-McCluskey-Verfahrens beruht auf der folgenden Eigenschaft von Konjunktionstermen: Unterscheiden sich zwei durch Disjunktion verknüpfte Konjunktionsterme nur durch die Negation einer einzigen Variablen, so kann man diese beiden Terme verschmelzen und dabei die betreffende Variable entfernen. Diese Eigenschaft erklärt sich aus folgendem algebraischen Zusammenhang:
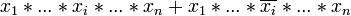
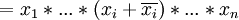
- = x1 * ... * xi − 1 * 1 * xi + 1 * ... * xn
- = x1 * ... * xi − 1 * xi + 1 * ... * xn
In diesem Zusammenhang ist es zweckmäßig, eine Boolesche Funktion unter dem Aspekt der Mengenlehre zu betrachten. (Es werden hier nur vollständig definierte Funktionen berücksichtigt):
- Eine Boolesche Funktion ist als Menge von Konjunktionen aller unabhängigen Variablen darstellbar. Dies entspricht den Funktionswerten der Wahrheitstabelle und ist die Gesamtmenge. Für n unabhängige Variablen beträgt ihre Mächtigkeit 2n Elemente.
- Die Elemente werden hierbei auch Elementarkonjunktionen genannt. Dies ist also ein einzelner Funktionswert.
- Diese Menge teilt sich in zwei Teilmengen auf. Ein Teil, welcher die Funktion zur wahren Aussage macht und ein Teil, welcher die Funktion nicht erfüllt. (Bei Verwendung von '0' und '1' also die Teilmenge der '1' und die Teilmenge der '0' in der Wahrheitstabelle).
- Eine Konjunktion ist eine Teilmenge dieser Gesamtmenge. Es gibt 3n mögliche Konjunktionen. (incl. der Gesamtmenge selbst).
Ein Element der Gesamtmenge ist Element einer Konjunktion, wenn die Belegung der in der Konjunktion enthaltenen Variablen mit den entsprechenden Werten des Elements (Elementarkonjunktion) die Konjunktion zur wahren Aussage macht.
Beispiel:
Erstellen der kanonischen disjunktiven Normalform
Das Quine-McCluskey-Verfahren geht nun von einer algebraischen Darstellung der Formel in kanonischer disjunktiver Normalform (KDNF) aus. Eine solche KDNF besteht aus einer Disjunktion von Mintermen. Eine andere Darstellung muss also zuerst in diese Form gebracht werden.
Da in diesem Schritt unter Umständen bis zu 2n Terme erzeugt werden, gibt es auch Varianten des Verfahrens, die nur eine DNF (statt einer KDNF) benötigen, wie z. B. die Resolventenmethode.
Ermitteln der Primterme
Alle Minterme werden jetzt nach aufsteigender Klasse sortiert, in einer Tabelle aufgelistet. Die Klasse einer Konjunktion ist die Anzahl der darin vorkommenden nicht negierten Variablen.
Man vergleicht nun alle Minterme benachbarter Klassen daraufhin, ob sie sich paarweise um eine einzige Negation unterscheiden. Ist dies der Fall, so verschmilzt man die beiden Terme zu einem neuen Term (der dann freilich kein Minterm mehr ist) und trägt ihn in eine zweite Tabelle ein. Die beiden verwendeten Terme werden (z. B. durch Abhaken) gekennzeichnet, sind aber auch weiterhin für Vergleiche heranzuziehen.
Auf die verschmolzenen Terme wendet man das Verfahren rekursiv in mehreren Stufen so lange an, bis keine weiteren Verschmelzungen mehr möglich sind. Es ist darauf zu achten, dass beide Terme (Tabellenzeilen) die gleichen Variablen enthalten. Während dieses Vorganges verbleiben einige Terme, die nicht verschmolzen werden konnten. Diese Terme bezeichnet man als Primterme bzw. Primkonjunktionen.
Hierbei treten ab der zweiten Minimierungsstufe die gleichen Konjunktionen mehrfach auf, sie sind jedoch nur einmal in die neue Tabelle einzutragen.
Erstellen der Primtermtabelle
Es ist durchaus möglich, dass nicht alle Primterme benötigt werden. Um herauszufinden, welche Primterme man unbedingt benötigt, erstellt man eine sogenannte Primtermtabelle. Als Spaltenköpfe der Tabelle werden die Minterme verwendet. Als Zeilenköpfe trägt man die Primterme ein. Die einzelnen Zellen der Tabelle sind also Kreuzungspunkte bestimmter Minterme mit bestimmten Primtermen.
Man trägt nun immer dann eine Markierung in der jeweiligen Zelle ein, wenn der Minterm Element des Primterms ist (s. o.).
Dominanzprüfung
Bei der Dominanzprüfung werden obsolete Zeilen und Spalten ermittelt.
Spaltendominanzprüfung
Die Spalten werden paarweise darauf verglichen, ob nicht eine Spalte existiert, in der die markierten Primterme eine Teilmenge der markierten Primterme der anderen Spalte sind. Ist dies der Fall, so kann die Spalte mit der Obermenge gestrichen werden, denn es müssen alle Konjunktionen erfasst werden und daher ist die Konjunktion mit der Obermenge durch Auswahl der Konjunktion mit der Teilmenge ebenfalls erfasst.
Beispiel:
In einer Tabelle stehen u. A. die beiden Spalten
- Ka = P1 + P2 + P4
- Kb = P1 + P4
Hier kann Ka gestrichen werden, weil er von Kb vollständig dominiert wird. Ka ist daher obsolet und wird ab jetzt nicht mehr berücksichtigt.
Zeilendominanzprüfung
Jetzt vergleicht man die Zeilen (Primterme) der Tabelle paarweise, ob nicht eine Zeile existiert, in denen die markierten Minterme eine Teilmenge der markierten Minterme der anderen Zeile sind. Ist dies der Fall, so kann der Primterm mit der Teilmenge gestrichen werden, denn man kann für jede Markierung des gestrichenen Primterms den anderen Primterm als Ersatz nehmen. Die Relation ist hier also genau umgekehrt wie bei der Spaltendominanz.
Beispiel:
In einer Tabelle stehen u. A. die beiden Zeilen
- Pa = K1 + K2 + K6 + K7
- Pb = K1 + K2
Hier kann Pb gestrichen werden, weil er von Pa vollständig dominiert wird. Pb ist daher obsolet und wird ab jetzt nicht mehr berücksichtigt.
Diese beiden Prüfungen werden solange abwechselnd wiederholt, bis bei einer Prüfung keine Zeile/Spalte mehr gestrichen werden kann, mindestens jedoch je einmal.
Auswahl der Primterme
Die verbleibenden Primterme muss man jetzt so auswählen, dass alle Minterme abgedeckt werden. Hierfür kann es mehrere (ggf. gleichwertige) Möglichkeiten geben. Man wählt dabei möglichst wenige und kleine Primterme, da man ja eine optimierte Funktion erreichen möchte, die schließlich mit möglichst wenigen Schaltgattern technisch realisiert werden kann.
Beispiel
Es folgt ein Beispiel, um die Methode zu erklären:
Darstellung als kanonische disjunktive Normalform
Wir gehen von einer Booleschen Funktion f mit vier Eingangsvariablen
 aus, deren kanonische disjunktive Normalform so aussieht:
aus, deren kanonische disjunktive Normalform so aussieht:In anderer Schreibweise:
Ermitteln der Primterme
Die Auswahltabellen Die Ausgangstabelle: Die erste Zusammenfassung ergibt: Es dürfen nur Zeilen zusammengefasst werden, die die "-" an den gleichen Positionen haben (!) Dritte Zusammenfassung Tabelle 1 mx x3 x2 x1 x0 OK m0 0 0 0 0 √ m1 0 0 0 1 √ m4 0 1 0 0 √ m8 1 0 0 0 √ m5 0 1 0 1 √ m6 0 1 1 0 √ m9 1 0 0 1 √ m7 0 1 1 1 √ m11 1 0 1 1 √ m15 1 1 1 1 √ Tabelle 2 mx + my x3 x2 x1 x0 OK m0 + m1 0 0 0 - √ m0 + m4 0 - 0 0 √ m0 + m8 - 0 0 0 √ m1 + m5 0 - 0 1 √ m1 + m9 - 0 0 1 √ m4 + m6 0 1 - 0 √ m4 + m5 0 1 0 - √ m8 + m9 1 0 0 - √ m5 + m7 0 1 - 1 √ m6 + m7 0 1 1 - √ m9 + m11 1 0 - 1 P1 m7 + m15 - 1 1 1 P2 m11 + m15 1 - 1 1 P3 Tabelle 3 mw + mx + my + mz x3 x2 x1 x0 OK m0 + m1 + m4 + m5 0 - 0 - P4 m0 + m1 + m8 + m9 - 0 0 - P5 m4 + m6 + m5 + m7 0 1 - - P6 Keine weiteren Zusammenfassungen möglich.
Es ergeben sich daher sechs Primterme:Erstellen der Primtermtabelle
Die Primtermtabelle sieht so aus:
m0 m1 m4 m5 m6 m7 m8 m9 m11 m15 P1 • • P2 • • P3 • • P4 • • • • P5 • • • • P6 • • • • Dominanzprüfung
Die erste Spaltendominanzprüfung ergibt:
- Streichen von m0, m1 und m9 wegen Spalte m8
- Streichen von m4, m5 und m7 wegen Spalte m6
Danach sieht die Tabelle so aus:
m6 m8 m11 m15 P1 • P2 • P3 • • P4 P5 • P6 • Die Zeilendominanzprüfung ergibt:
- Streichen von P4 (leer).
- Streichen von P2 wegen P3
- Streichen von P1 wegen P3
Somit erhält man:
m6 m8 m11 m15 P3 • • P5 • P6 • Eine Zweite Spaltendominanzprüfung ergibt:
- Streichen von m15 wegen m11
Ergebnis:
m6 m8 m11 P3 • P5 • P6 • Eine zweite Zeilendominanzprüfung ergibt keine Streichungen mehr. Damit ist die Dominanzprüfung beendet.
Auswahl der Primterme
Die Auswahl geeigneter Primterme ist hier jetzt sehr einfach, da es nur eine Möglichkeit gibt: Benötigt werden die Primterme P3, P5 und P6.
Verknüpfung der gewählten Primterme
Jetzt müssen die ausgewählten Primterme mittels Disjunktion zur Lösungsgleichung verknüpft werden:
Anmerkung
Das Problem, eine minimale Anzahl von Primtermen aus der Primtermtabelle auszuwählen, ist NP-vollständig; d.h., für viele Fälle ist kein wesentlich besseres Verfahren bekannt, als alle möglichen Auswahlen auszuprobieren. Deshalb bietet es sich an, das Minimum nur näherungsweise zu bestimmen. Beispielsweise wählt man zuerst die Spalten mit nur einer Markierung aus (diese sind zwingend notwendig), danach sucht man in den Spalten mit wenig Markierungen oder in Zeilen mit vielen Markierungen nach geeigneten Termen.
Das Verfahren hat insbesondere bei höherer Variablenzahl Vorteile gegenüber dem Karnaugh-Veitch-Diagramm (KVD). Als Faustregel gilt: Bis fünf Variablen ist das KVD besser, ab sechs Variablen das QMCV.
Weblinks
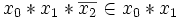
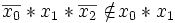
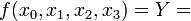
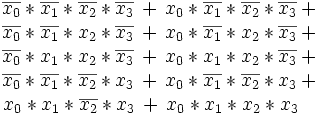
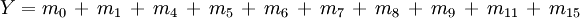
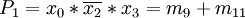
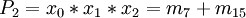
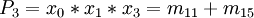
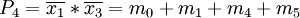
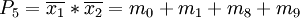
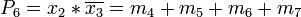
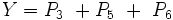
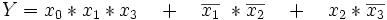
Wikimedia Foundation.