- Warl
-
Wahrscheinlich Annähernd Richtiges Lernen (WARL) oder englisch Probably approximately correct learning (PAC learning) ist ein Framework für das maschinelle Lernen, das von Leslie Valiant in seinem Paper A theory of the learnable[1] eingeführt wurde.
In diesem Framework erhält die lernende Einheit Beispiele, die gemäß einer bestimmten Funktion klassifiziert sind. Das Ziel des Trainings ist es, mit großer Wahrscheinlichkeit eine Annäherung dieser Funktion zu finden. Man erwartet von der lernenden Einheit, das Konzept mit einer beliebigen Annäherungsrate, einer beliebigen Erfolgswahrscheinlichkeit und einer beliebigen Verteilung der Beispiele zu lernen.
Inhaltsverzeichnis
Definition
Das PAC-Framework erlaubt eine genaue mathematische Analyse von Lernverfahren. H sei der endliche Hypothesenraum. ε sei die gewünschte Genauigkeit des vom Lernverfahren erzeugten Klassifikators bei ungesehenen Daten. δ sei die Wahrscheinlichkeit, dass das Lernverfahren so einen Klassifikator nicht erzeugen kann. Es gelte 0 < ε < 0.5 und 0 < δ < 0.5. Einem konsistenten Lernverfahren reichen dann m Trainingsbeispiele aus, um einen Klassifikator mit den Anforderungen von ε und δ zu lernen. Mit anderen Worten, m Trainingsbeispiele reichen aus, um mit der Wahrscheinlichkeit von 1 − δ ein PAC-lernbares Problem so zu lernen, dass auf neuen Daten eine Fehlerrate von maximal 1 − ε zu erhalten. Für m gilt dabei
Herleitung
Die Abschätzung für m ist eng mit dem Versionsraum verbunden. Ein konsistentes Lernverfahren gibt definitionsgemäß eine Hypothese aus dem Versionsraum aus. Jede Hypothese im Versionsraum ist konsistent mit den Trainingsdaten, kann jedoch auf ungesehenen Daten Fehler machen. Seien
 die Hypothesen, die einen echten Fehler mit Wahrscheinlichkeit größer ε machen. So eine Hypothese ist mit Wahrscheinlichkeit 1 − ε mit einem zufälligen Beispiel und mit Wahrscheinlichkeit (1 − ε)m mit m Beispielen konsistent. Existiert mindestens eine solche Hypothese, dann ist sie Teil des Versionsraums und könnte von einem konsistenten Lernverfahren als Hypothese ausgegeben werden. Die Wahrscheinlichkeit, dass im Versionsraum eine solche Hypothese enthalten ist, ist nach oben beschränkt durch
die Hypothesen, die einen echten Fehler mit Wahrscheinlichkeit größer ε machen. So eine Hypothese ist mit Wahrscheinlichkeit 1 − ε mit einem zufälligen Beispiel und mit Wahrscheinlichkeit (1 − ε)m mit m Beispielen konsistent. Existiert mindestens eine solche Hypothese, dann ist sie Teil des Versionsraums und könnte von einem konsistenten Lernverfahren als Hypothese ausgegeben werden. Die Wahrscheinlichkeit, dass im Versionsraum eine solche Hypothese enthalten ist, ist nach oben beschränkt durch 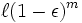 . Man benötigt eine Abschätzung in Abhängigkeit von der Anzahl an Trainingsbeispielen. Es gilt
. Man benötigt eine Abschätzung in Abhängigkeit von der Anzahl an Trainingsbeispielen. Es gilt 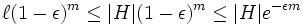 . In mindestens 1 − δ aller Fälle soll nach obiger Forderung keine Hypothese mit echtem Fehler größer als ε im Versionsraum enthalten sein, d.h. 1 − | H | e − εm > 1 − δ. Damit folgt
. In mindestens 1 − δ aller Fälle soll nach obiger Forderung keine Hypothese mit echtem Fehler größer als ε im Versionsraum enthalten sein, d.h. 1 − | H | e − εm > 1 − δ. Damit folgt 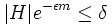 und Auflösung nach m ergibt
und Auflösung nach m ergibt-
 .
.
Die Abschätzung für die Anzahl benötigter Beispiele m ist meist sehr grob und in der Praxis reichen weniger Beispiele aus. Dieses Modell wurde noch erweitert, um mit Rauschen, also falsch klassifizierten Beispielen, umgehen zu können.
Referenzen
- ↑ L. G. Valiant: A Theory of the Learnable. In: Communications of the ACM. 27(11), 1984, S. 1134-1142.
Literatur
- M. Kearns, U. Vazirani: An Introduction to Computational Learning Theory. MIT Press, 1994, ISBN 0262111934.
- Tom M. Mitchell: Machine Learning. McGraw-Hill Education, 1997, ISBN 0071154671.
Weblinks
- Probably Approximately Correct Learning - Einführung in dieses Themengebiet
-
Wikimedia Foundation.