- Entropie-Kodierung
-
Die Entropiekodierung ist eine Methode zur verlustfreien Datenkompression, die jedem einzelnen Zeichen eines Textes eine unterschiedlich lange Folge von Bits zuordnet. Im Gegensatz dazu stehen Stringersatzverfahren (wie LZ77 oder LZ78), die eine Folge von Zeichen des Originaltextes durch eine Folge von Zeichen eines anderen Alphabets ersetzen.
Da eine bestimmte Mindestanzahl von Bits notwendig ist, um alle Zeichen voneinander zu unterscheiden, kann die Anzahl der Bits, die den Zeichen zugeordnet werden, nicht unbegrenzt klein werden.
Die optimale Anzahl von Bits, die einem Zeichen mit einer gegebenen Wahrscheinlichkeit zugeordnet werden sollte, wird durch die Entropie bestimmt.
Entropiekodierer werden häufig mit anderen Kodierern kombiniert. Dabei dienen vorgeschaltete Verfahren dazu, die Entropie der Daten zu verringern. Häufig sind dies Prädiktionsverfahren, Verfahren wie die Burrows-Wheeler-Transformation, aber oft auch andere Komprimierer. LHarc zum Beispiel verwendet einen LZ-Kodierer und gibt die von diesem Kodierer ausgegebenen Zeichen an einen Huffman-Kodierer weiter. Auch ZIP und Bzip besitzen als letzte Stufe einen Entropiekodierer.
Inhaltsverzeichnis
Kodierung
Die Entropiekodierung bestimmt zunächst die Häufigkeit von Symbolen (Zeichen). Jedes Symbol wird durch ein bestimmtes Bitmuster dargestellt. Dabei sollen häufige Symbole durch kurze Bitmuster dargestellt werden, um die Gesamtzahl der benötigten Bits zu minimieren.
Mathematische Algorithmen zur Abschätzung der optimalen Länge des Codes eines jeden Symbols führen meist zu nicht ganzzahligen Ergebnissen. Bei der Anwendung müssen die Längen auf ganzzahlige Werte gerundet werden, wodurch man einen Teil der Verdichtung verliert.
Mit ganzen Bits
Die Shannon-Fano-Kodierung schlägt eine Möglichkeit vor, die die Anzahl der Bits auf ganze Zahlen rundet. Dieser Algorithmus liefert aber in bestimmten Fällen nicht die optimale Lösung. Deshalb wurde der Huffman-Code entwickelt, der beweisbar immer eine der optimalen Lösungen mit ganzen Bits liefert. Beide Algorithmen erzeugen einen präfixfreien Code variabler Länge, indem ein binärer Baum konstruiert wird. In diesem Baum stehen die "Blätter" für die zu kodierenden Symbole und die inneren Knoten für die abzulegenden Bits.
Neben diesen Verfahren, die individuelle Tabellen speziell angepasst auf die zu kodierenden Daten erstellen, gibt es auch Varianten, die feste Codetabellen verwenden. Der Golomb-Code kann z. B. bei Daten verwendet werden, bei denen die Häufigkeitsverteilung bestimmten Regeln unterliegt. Diese Codes haben Parameter, um ihn auf die exakten Parameter der Verteilung der Häufigkeiten anzupassen.
Verbesserung
Diese Verfahren treffen aber die von der Entropie vorgeschriebene Anzahl von Bits nur in Ausnahmefällen. Das führt zu einer nicht optimalen Kompression.
Ein Beispiel: Eine Zeichenkette mit nur 2 verschiedenen Symbolen soll komprimiert werden. Das eine Zeichen hat eine Wahrscheinlichkeit von p(A) = 0,75, das andere von p(B) = 0,25. Die Verfahren von Shannon und Huffman führen dazu, dass beide Zeichen mit je einem Bit abgespeichert werden. Das führt zu einer Ausgabe, die so viele Bits enthält wie die Eingabe an Zeichen.
Ein optimaler Entropie-Kodierer würde aber nur
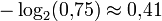 Bits für das Zeichen A verwenden und dafür − log2(0,25) = 2 Bits für B. Das führt zu einer Ausgabe, die nur
Bits für das Zeichen A verwenden und dafür − log2(0,25) = 2 Bits für B. Das führt zu einer Ausgabe, die nur 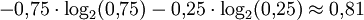 Bits pro Zeichen enthält (maximale Entropie).
Bits pro Zeichen enthält (maximale Entropie).Mit einem arithmetischen Kodierer kann man sich der optimalen Codierung weiter annähern. Dieses Verfahren sorgt implizit für eine gleichmäßigere Verteilung der Bits auf die zu codierenden Zeichen, ohne dass explizit für jedes Zeichen ein individuelles Codezeichen konstruiert wird. Aber auch mit diesem Verfahren kann nicht i. a. die maximale Entropie erreicht werden. Dies liegt daran, dass es weiterhin einen "Verschnitt" gibt, der darauf beruht, dass nur ganzzahlige Bitwerte tatsächlich auftreten können, während die Entropie meist Bruchteile von Bits erfordert. Im o. g. Beispiel erreicht auch der Arithmetische Codierer nur eine Codelänge von einem Bit. Der Verschnitt verschwindet allerdings i. a. mit zunehmender Länge der zu codierenden Daten, so dass im Grenzwert die Entropie maximiert werden kann.
Modell
Um die Anzahl der Bits für jedes Zeichen festlegen zu können, muss man zu jedem Zeitpunkt des Kodierungsprozesses möglichst genaue Angaben über die Wahrscheinlichkeit der einzelnen Zeichen machen. Diese Aufgabe hat das Modell. Je besser das Modell die Wahrscheinlichkeiten vorhersagt, desto besser die Kompression. Das Modell muss beim Komprimieren und Dekomprimieren genau die gleichen Werte liefern. Im Laufe der Zeit wurden verschiedene Modelle entwickelt.
Statisches Modell
Beim Statischen Modell wird vor der Kodierung der Zeichenfolge eine Statistik über die gesamte Folge erstellt. Die dabei gewonnenen Wahrscheinlichkeiten werden zur Kodierung der gesamten Zeichenfolge verwendet.
- Vorteile
- Kodiertabellen müssen nur einmal erstellt werden. Das Verfahren ist deshalb sehr schnell.
- Die Ausgabe ist ohne die zum Dekomprimieren notwendigen Statistiken garantiert nicht größer als der Originaltext.
- Nachteile
- Die Statistik muss an den Decoder übermittelt werden (entweder als Statistik oder in Form der Huffman- oder Shannon-Fano-Codes), was Speicher kostet.
- Die Statistik bezieht sich auf die gesamte Zeichenfolge, d.h. die Werte passen sich nicht an lokale Gegebenheiten in der Zeichenkette an.
Dynamisches Modell
In diesem Modell verändern sich die Wahrscheinlichkeiten im Laufe des Kodierungsprozesses. Dabei gibt es mehrere Möglichkeiten:
- Vorwärts dynamisch: Die Wahrscheinlichkeiten beziehen sich auf bereits kodierte Zeichen, d.h. hier wird nach dem Kodieren eines Zeichens die Wahrscheinlichkeit dieses Zeichens erhöht.
- Rückwärts dynamisch: Hier wird vor dem Kodieren ausgezählt, wie oft jedes Zeichen vorkommt. Aus diesen Zählern lassen sich genaue Wahrscheinlichkeiten ermitteln. Im Laufe des Kodierungsprozesses wird für jedes kodierte Zeichen der dazu gehörende Zähler um 1 verringert. Da gegen Ende die Zähler für alle Zeichen gegen 0 streben, werden die Wahrscheinlichkeiten für nicht mehr vorkommende Zeichen auch 0. Diese Zeichen können nicht mehr kodiert werden. Andere Zeichen können dafür mit weniger Bits kodiert werden, da deren Wahrscheinlichkeit steigt. Die Kodiereffizienz steigt auf diese Weise so weit an, dass das letzte Zeichen mit 0 Bits kodiert werden kann.
- Vorteile
- Anpassung des Modells an lokale Gegebenheiten
- Statistik-Informationen müssen im vorwärts-dynamischen Modell nicht übertragen werden.
- Nachteile
- Tabellen müssen nach jedem Zeichen überarbeitet werden. Das kostet Rechenzeit.
- Die Statistik eilt den wahren Gegebenheiten hinterher. Im schlimmsten Fall stimmt die Statistik nie mit den wahren Wahrscheinlichkeiten überein, was dazu führt, dass mehr Bits benötigt werden.
Normalerweise arbeitet man bei dynamischen Modellen nicht mit Wahrscheinlichkeiten, sondern mit den Häufigkeiten der Zeichen.
Dynamische Modelle lassen auch noch andere Variationsmöglichkeiten zu.
Man kann Statistik-Daten altern, indem man von Zeit zu Zeit die Häufigkeiten der Zeichen halbiert. Damit verringert man den Einfluss von weit zurückliegenden Zeichen.
Für noch nie vorgekommene Zeichen gibt es mehrere Varianten:
- Man nimmt eine Häufigkeit von mindestens 1 für jedes Zeichen an, so dass alle Zeichen kodiert werden können.
- Man fügt dem Alphabet ein neues Zeichen hinzu. Dieses Zeichen deutet ein Verlassen des Kontextes an. Nachdem diese Zeichen kodiert wurden, können alle Zeichen des Alphabetes mit einem festen Code geschrieben oder gelesen werden. Das Zeichen wird normalerweise Escape-Zeichen genannt. Einige der besten Komprimieralgorithmen, die der Familie PPM, benutzen dieses Vorgehen.
Level des Modells
Das Level eines Modells bezieht sich darauf, wie viele Zeichen der Historie vom Modell für die Berechnung der Wahrscheinlichkeiten herangezogen werden. Ein Level 0 Modell betrachtet keine Historie und gibt die Wahrscheinlichkeiten global an. Ein Level 1 Modell dagegen betrachtet das Vorgängerzeichen und trifft in Abhängigkeit von diesem Zeichen seine Aussage über die Wahrscheinlichkeit. (Soll deutscher Text kodiert werden, ist zum Beispiel die Wahrscheinlichkeit des Buchstabens "U" nach einem "Q" viel höher, oder die Wahrscheinlichkeit eines Großbuchstabens in der Mitte eines Wortes viel kleiner als nach einem Leerzeichen). Das Level kann theoretisch beliebig hoch sein, erfordert dann aber enormen Speicherplatz und große Datenmengen, um aussagekräftige Statistiken zu erhalten.
PPM-Algorithmen verwenden einen arithmetischen Kodierer mit einem dynamischen Modell des Levels 5.
Literatur
- Mark Nelson, Jean-Loup Gailly: The Data Compression Book, 2nd edition. M & T Books, New York 1996, ISBN 1-55851-434-1.
- Dieses Buch bereitet einen relativ guten Einstieg. Es beschäftigt sich allerdings mehr mit der Implementierung in C als mit der Theorie der Datenkompression.
- Khalid Sayood: Introduction to Data Compression, 2nd edition. Morgan Kaufmann Publishers, San Francisco 2005, ISBN 1-55860-558-4.
- Dieses Buch ist ein Standardwerk zu den theoretischen und anwendungsrelevanten Grundlagen der Datenkompression.
Weblinks
- Compression Pointers - Enthält eine lange Liste mit Links zum Thema Datenkomprimierung, u.a. auch für PPM.
- Vorteile
Wikimedia Foundation.