- Shannon-Fano-Kodierung
-
Die Shannon-Fano-Kodierung und Huffman-Kodierung sind eine Art der Entropiekodierung.
Dieser Artikel beschreibt, wie zu einem gegebenen Satz von Zeichen-Wahrscheinlichkeits-Paaren die Kodierung erstellt werden kann, welche eine möglichst kleine mittlere Wortlänge benötigt. Dabei ist durch die Entropie (mittlerer Informationsgehalt) eine untere Schranke gegeben (Quellencodierungstheorem).
Da zu einem Entropiekodierer immer auch ein Modell gehört, sollten die zusätzlichen Informationen aus dem Artikel zur Entropiekodierung entnommen werden.
Inhaltsverzeichnis
Grundidee
Von der Entropiekodierung her ist bekannt, dass Zeichen mit einer unterschiedlichen Anzahl von Bits kodiert werden müssen, wenn man eine speichersparende Darstellung erhalten möchte. Es ist aber nicht möglich, den Zeichen einfach Bitfolgen zuzuweisen und diese auszugeben.
Wird zum Beispiel das Zeichen A mit der Bitfolge „10“, das Zeichen B mit der Folge „01“ und C mit „0“ kodiert, dann wird die Zeichenkette ABC zu „10010“. Diese Folge wird aber auch von der Zeichenkette „ACA“ erzeugt. Es ist also nicht mehr eindeutig erkennbar, für welche Zeichenfolge die Bitfolge „10010“ steht.
Um diese Mehrdeutigkeit zu verhindern, müssen die den Zeichen zugewiesenen Bitfolgen die Eigenschaft besitzen, präfixfrei zu sein, d. h. keine Bitfolge, die für ein einzelnes Zeichen steht, darf am Anfang eines anderen Zeichens stehen. Diese Eigenschaft ist im oberen Beispiel nicht erfüllt, da die Bitfolge „0“, die für C steht, am Anfang der B zugewiesenen Folge steht.
Wie kann nun ein präfixfreier Code erzeugt werden?
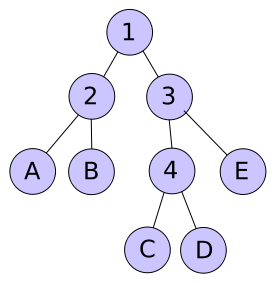
Die Grundidee ist, einen vollen binären Baum für die Darstellung des Codes zu verwenden. In dem Baum stehen die Blätter für die zu kodierenden Zeichen, während der Pfad von der Wurzel zum Blatt die Bitfolge bestimmt.
Das Bild zeigt einen Baum, der von der gewünschten Form ist. Die inneren Knoten sind durchnummeriert, um sie benennen zu können.
Um nun die Bitfolge zu ermitteln, die für eines der Zeichen stehen soll, muss festgelegt werden, wie die Abzweige kodiert werden sollen. Eine Variante ist, zu sagen, dass linke Teilbäume mit einer 0 und rechte mit einer 1 kodiert werden. Daraus folgen für den Beispielbaum folgende Bitfolgen:
A B C D E 00 01 100 101 11 Genauso gut ist aber auch eine Menge von anderen Kodierungen möglich. Hier nur noch ein paar Beispiele:
A B C D E 10 11 000 001 01 11 10 010 011 00 11 10 001 000 01 Will man nun eine Zeichenfolge kodieren, so werden die den entsprechenden Zeichen zugewiesenen Bitfolgen hintereinander ausgegeben. Die Zeichenfolge „ACDC“ wird mit der ersten Kodierung zu der Bitfolge „00100101100“.
Um diese Bitfolge zu dekodieren, wird sie Bit für Bit abgearbeitet. Der Dekodierer muss sich dabei die aktuelle Position im Baum merken. Gestartet wird an der Wurzel, also im Knoten 1. Dann wird das erste Bit gelesen, eine 0. Das bedeutet bei dieser Kodierung nach links, der aktuelle Knoten wird also 2. Es folgt ein weiteres 0-Bit. Der aktuelle Knoten ist jetzt A. Es wird A ausgegeben und der aktuelle Knoten wieder auf 1 gesetzt. Das als nächstes gelesene 1-Bit führt dazu, dass der aktuelle Knoten die 3 ist usw.
Das nun zu lösende Problem ist es, einen solchen Baum zu erstellen, bei dem die durchschnittliche Anzahl der Fragen, bis ein Zeichen eindeutig ermittelt ist, im Mittel möglichst klein ist, also möglichst dicht an der Entropie liegt.
Shannon-Fano-Kodierung und Huffman-Kodierung sind zwei unterschiedliche Algorithmen zur Konstruktion dieser Bäume.
Shannon-Fano
Der nach Claude Shannon und Robert Fano benannte Algorithmus arbeitet mit folgender Vorschrift:
- Sortiere die Zeichen nach ihrer Häufigkeit.
- Teile die Zeichen entlang dieser Reihenfolge so in 2 Gruppen, dass die Summe der Häufigkeiten in den beiden Gruppen möglichst gleich ist. Die beiden Gruppen entsprechen dem linken und rechten Teilbaum des zu erstellenden Shannon-Baumes. Die dabei entstandene Partitionierung ist nicht unbedingt die beste, die mit den gegebenen Häufigkeiten zu erreichen ist. Die beste Partitionierung ist auch gar nicht gesucht, da diese nicht zwangsweise zu einem besseren Ergebnis führt. Der Huffman-Baum, der weiter unten mit den gleichen Häufigkeiten erzeugt wird, hat sogar eine schlechtere Partitionierung. Worauf es ankommt ist, dass die mittlere Abweichung von der Entropie der Zeichen möglichst klein ist.
- Befindet sich mehr als ein Zeichen in einer der entstandenen Gruppen, wende den Algorithmus rekursiv auf diese Gruppe an.
Das wichtige Element an diesem Algorithmus ist der erste Schritt. Dieser sorgt dafür, dass Zeichen mit ähnlichen Wahrscheinlichkeiten oft im selben Teilbaum enden. Das ist wichtig, da Knoten im selben Baum Bitfolgen mit ähnlichen Codelängen erhalten (der maximale Unterschied kann nur die Anzahl der Knoten in diesem Baum betragen). Sind die Wahrscheinlichkeiten nun sehr unterschiedlich, kann man keine Bitfolgen mit den notwendigen Längenunterschieden erzeugen. Das führt dazu, dass seltene Zeichen zu kurze Bitfolgen und häufige Zeichen zu lange Bitfolgen erhalten.
Beispiel
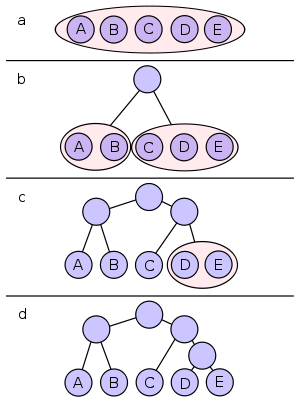 Shannon-Fano-Beispiel
Shannon-Fano-Beispiel
Das Beispiel zeigt die Konstruktion des Shannon-Codes für ein kleines Alphabet. Die gleichen Werte werden weiter unten auch für den Huffman-Code verwendet, damit die Ergebnisse vergleichbar sind. Die fünf zu kodierenden Zeichen haben folgende Häufigkeiten:
-
Zeichen A B C D E Häufigkeit 15 7 6 6 5
Sortiert sind die Werte schon, also direkt zu Schritt 2, dem Partitionieren. Am Anfang sind alle Zeichen in einer Partition (im Bild a).
Die Hälfte der Wahrscheinlichkeitssumme ist 19,5. 15 ist 4,5 unter diesem Halbwert, 15+7 hingegen nur 2.5 darüber - eine bessere Partitionierung gibt es nicht. Das Alphabet wird also so in 2 Teile unterteilt, dass der eine Teil die Zeichen A und B und der andere Teil den Rest (C, D und E) enthält (Bild b). Beide Partitionen enthalten noch mehr als 1 Zeichen, müssen also weiter zerteilt werden. Die Partition mit A und B kann nur in 2 Teile mit je einem Zeichen zerlegt werden. Die andere Gruppe hat 2 Möglichkeiten. 6+6 ist weiter von der Mitte entfernt, als 6 alleine. Also wird in die 2 Partitionen mit C und D+E unterteilt (Bild c). Schließlich wird noch D und E zerteilt. Der entstandene Entscheidungsbaum ist im Bild Abschnitt d dargestellt.
Den Zeichen A, B und C wurden also 2 Bits, D und E 3 Bits zugeordnet. Die Auftrittswahrscheinlichkeit von A beträgt 15/39, von B 7/39, von C sowie D 6/39 und von E 5/39. Somit ergibt sich für die mittlere Codewortlänge:
Da die Zuweisung, wie oben besprochen, nicht eindeutig ist, hier nur ein Beispiel für eine mögliche Kodierung aufgrund dieses Baumes:
Zeichen A B C D E Kodierung 00 01 10 110 111 Huffman-Code
Der vom Shannon-Fano-Algorithmus erzeugte Baum ist nicht immer optimal. David A. Huffman gab 1952 einen anderen Algorithmus an, der beweisbar immer einen optimalen Baum für gegebene Wahrscheinlichkeiten liefert.[1] Während der Shannon-Fano-Baum von der Wurzel zu den Blättern erstellt wird, arbeitet dieser Algorithmus zur Konstruktion des Huffman-Baums in entgegengesetzter Richtung.
- Erstelle einen Wald mit einem Baum für jedes Zeichen. Jeder dieser Bäume enthält nur einen einzigen Knoten: das Zeichen. Schreibe die Häufigkeit an die Kante.
- Suche die beiden Bäume, die die geringste Häufigkeit haben. Fasse beide Bäume zusammen, indem sie die Teilbäume einer neuen Wurzel werden. Benutze die Summe der Häufigkeiten dieses neuen Baumes zur weiteren Analyse.
- Wiederhole Schritt 2 so oft, bis nur noch ein Baum übrig ist.
Beispiel
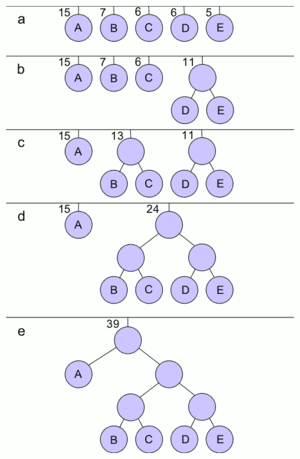 Huffman-Code-Beispiel
Huffman-Code-BeispielDas gleiche Beispiel wie bei Shannon-Fano-Code führt zu folgenden Schritten.
Der Wald wird erstellt. Im Bild ist in Abschnitt a der Zustand zu sehen. Am oberen Ende sind die Häufigkeiten für jeden dieser Bäume angezeigt, da diese vom Algorithmus benötigt werden.
Die beiden Bäume mit den geringsten Häufigkeiten sind C und E oder D und E. Diese werden entfernt (im Beispiel D und E), ein neuer Baum mit einer Häufigkeit von 5+6=11 wird erstellt und in den Wald eingefügt (Bild b).
Als nächstes werden B und C zusammengefasst. Der neue Baum hat die Häufigkeit 13 (Bild c).
Nun werden die 2 bereits zusammengefassten Bäume ein weiteres Mal verbunden (Bild d).
Schließlich wird A mit dem Rest zu einem Baum verbunden (Bild e). Der Algorithmus ist hiermit beendet, da nur noch ein Baum im Wald vorhanden ist.
Die Codelängen für die einzelnen Zeichen sind diesmal 1 Bit für A und 3 Bit für alle anderen Zeichen. Dies führt zu einer mittleren Codewortlänge von:
Im Vergleich zu 2,28 Bits pro Zeichen, wie bei Shannon-Fano, ist das eine Verbesserung.
Beweis der Optimalität des Huffman-Baumes
Dazu zuerst ein paar Definitionen:
Σ ist das Alphabet, für das der Code erstellt werden soll. Es enthält | Σ | = n Zeichen.
 sind die einzelnen Zeichen des Alphabets. Jedes Zeichen hat eine Wahrscheinlichkeit von p(σ).
sind die einzelnen Zeichen des Alphabets. Jedes Zeichen hat eine Wahrscheinlichkeit von p(σ).l(σ) ist die Länge des zu verwendenden Codes, bzw. die Tiefe des Zeichens im Baum.
 ist die durchschnittliche Codelänge für das gesamte Alphabet für einen bestimmten Baum T. B(T) ist die Größe, die für den Huffman-Baum minimal sein soll.
ist die durchschnittliche Codelänge für das gesamte Alphabet für einen bestimmten Baum T. B(T) ist die Größe, die für den Huffman-Baum minimal sein soll.Da es nur endlich viele verschiedene Binärbäume mit n Blättern gibt existiert somit auch ein Baum T, für den B(T) minimal ist.
Für den Beweis werden 2 Hilfssätze benötigt:
Lemma 1: Jeder innere Knoten hat in einem Huffman-Baum zwei Kind-Knoten.
Beweis: Angenommen, es gibt einen Baum T, in dem ein innerer Knoten nur ein Kind hat. Dann lässt sich ein Baum T' konstruieren, indem man diesen Knoten entfernt und stattdessen den Kindknoten an die Stelle des Knoten hängt.
Für diesen neuen Baum gilt:
 , wobei A alle Zeichen enthält, die in dem verschobenen Teilbaum liegen.
, wobei A alle Zeichen enthält, die in dem verschobenen Teilbaum liegen.Da die Wahrscheinlichkeiten größer 0 sind, gilt B(T') < B(T) was im Widerspruch zur Annahme steht.
Lemma 2: Wenn σ1 und σ2 die beiden Buchstaben mit den kleinsten Wahrscheinlichkeiten sind, so existiert ein Huffman-Baum, in dem diese beiden Zeichen Kinder desselben Vaters sind.
Beweis: Angenommen es gibt einen Baum T, in dem die beiden Zeichen nicht Nachbarn mit dem gleichen Vater sind. Das Zeichen in der größeren Tiefe im Baum (σ1) hat einen Nachbarbaum Tn.
σ2 kann nicht in diesem Baum liegen, da es dann entweder der Nachbar von σ1 wäre oder seine Tiefe größer wäre, was wir ausgeschlossen hatten.
Die Summe der Häufigkeiten aller Zeichen in Tn ist größer oder gleich der Wahrscheinlichkeit von σ2, da der Baum mindestens ein Zeichen enthält und alle Zeichen eine Wahrscheinlichkeit größer oder gleich der von σ2 sind.
Tauscht man nun in T den Baum Tn mit dem Zeichen σ2, so erhält man einen Baum T' für den gilt:

Der neue Baum hat also eine durchschnittliche Codelänge gleich oder kürzer der des originalen Baumes. Damit ist auch der Baum ein Huffman-Baum.
Lemma 3: In einem gegebenen Huffman-Baum T sind die beiden seltensten Zeichen σ1 und σ2 Nachbarn. Aus diesem Baum wird ein Baum T' konstruiert, in dem die beiden Zeichen σ1 und σ2 entfernt werden. Der Vaterknoten wird zu einem Blattknoten, der ein neues Zeichen ω mit der Wahrscheinlichkeit p(ω) = p(σ1) + p(σ2) darstellt.
Dieser neue Baum ist ein Huffman-Baum für das modifizierte Alphabet Σ' aus dem σ1 und σ2 entfernt und ω eingefügt wurde.
Beweis: In Baum T' kann man durch Ersetzen des Knotens für ω einen Codebaum für das ursprüngliche Problem erhalten, wobei gilt: B(T) = B(T') + p(σ1) + p(σ2). Ist nun T' kein Huffman-Baum, so existiert nun ein Baum T'', in dem B(T'') < B(T') ist. Dies kann aber nicht sein, da die Konstruktion eines Baumes für das Originalproblem aus T'' zu einem effizienteren Baum führen würde, als der Ursprungsbaum, der bereits optimal war.
Der eigentliche Beweis läuft nun über vollständige Induktion.
Induktionsanfang: Der Algorithmus liefert offensichtlich einen optimalen Baum für 2 Zeichen.
Induktionsschritt: Wird durch Lemma 3 bewiesen. Angenommen, der Algorithmus liefert einen optimalen Baum für das vorhandene Problem mit den zwei seltensten Zeichen, dann liefert er auch einen für das gegebene Problem, da er genau diese Ersetzung durchführt.
Implementierungsdetails
Die zeiteffiziente Implementierung scheitert oft an den vielen Bitoperationen, die notwendig sind, um Bytes aus den einzelnen Bits zu bilden, die einzelnen Bits beim Dekodieren auszuwerten und den Weg im Baum nachzuvollziehen.
Es gibt aber effiziente Algorithmen, um diese Prozesse zu beschleunigen (siehe zlib-Bibliothek).
Dynamische Huffman-Bäume
Soll ein Kodierer programmiert werden, der mit einem dynamischen Modell arbeitet, so muss der Baum regelmäßig für das neue Modell neu erstellt, oder aktualisiert werden. Auch dafür gibt es effiziente Algorithmen, die die häufigste Veränderung, die Erhöhung der Häufigkeit eines Zeichens um 1, effizient am Huffman-Baum ausführen können, ohne den gesamten Baum neu erstellen zu müssen: FGK-Algorithmus nach Faller-Gallager-Knuth, V-Algorithmus nach Vitter[2].
Daneben gibt es auch noch andere Ansätze, die nicht mit Huffman-Bäumen arbeiten, sondern die Zeichen wie die in den AVL-Bäumen benutzten Rotationsoperationen in ihrer Höhe den aktuellen Häufigkeiten anpassen (siehe Splay-Baum).
Übertragung des Baumes
Muss so ein Kodierungsbaum in der kodierten Datei mit an den Decoder übergeben werden, wie es bei statistischen Verfahren (siehe Entropiekodierung) notwendig ist, braucht man eine möglichst kompakte Repräsentation.
Dazu werden ein paar Beobachtungen ausgenutzt.
- Die genaue Lage eines Zeichens im Baum ist nicht von Bedeutung, so lange die Tiefe, also der Abstand von der Wurzel demjenigen im Huffman-Baum entspricht.
- Durch Austauschen von Knoten kann man den Baum immer in eine Form bringen, bei der die Knoten von links nach rechts in ihrer Tiefe aufsteigend angeordnet sind.
- Diese Operationen verändern zwar die den Zeichen zugewiesenen Bitfolgen, nicht aber die Optimalität des Codes.
Ein auf diese Art sortierter Baum kann ausgegeben werden, indem man nur ausgibt, welche Zeichen mit wie vielen Bits verschlüsselt werden. Die innere Struktur des Baumes wird dadurch vollständig beschrieben.
Im Beispielfall vom Huffman-Algorithmus müsste man also ausgeben, dass es 1 Zeichen mit Länge 1, nämlich A, und 4 Zeichen mit Länge 3 gibt. Das könnte man mit der Zeichenkette
"\x01A\x00\x04BCDE"erledigen (C-Syntax: \xyy steht für das Zeichen mit dem hexadezimalen ASCII Code yy). Diese Zeichenkette wird folgendermaßen interpretiert: \x01 bedeutet, dass es ein Zeichen mit Kodelänge 1 gibt. Das Zeichen folgt: A. \x00 bedeutet, dass es kein Zeichen mit Kodelänge 2 gibt. \x04: es gibt 4 Zeichen mit Kodelänge 3, diese folgen.Dieses Verfahren wird z. B. von JPEG bei der optimierten Ausgabe von Bildern benutzt. Hier wird anstatt einer der vorgegebenen festen Kodierungen ein optimaler Code (Huffman) erzeugt und auf diese Weise dem Dekodierer mitgegeben. In den Spezifikationen von ISO steht mehr zu diesem Thema.
Verbesserungsmöglichkeiten
Die vorgestellten Algorithmen verwenden immer eine ganzzahlige Anzahl von Bits, um ein Zeichen darzustellen. Das führt zwangsweise zu einer nicht optimalen Kodierung (im Sinne der Entropie), außer für den sehr seltenen Fall, dass die Wahrscheinlichkeiten aller Zeichen von der Form
 ist.
ist.Die verwendeten Verfahren weichen unter folgenden Bedingungen besonders vom Optimum ab:
- Die Wahrscheinlichkeit eines Zeichens ist größer als 0,5. Da die kürzeste mögliche Bitfolge 1 Bit lang ist, ist diese zu lang, was sich bei einem sehr häufigen Zeichen natürlich besonders auswirkt.
- Die Wahrscheinlichkeit eines Zeichens ist sehr klein. So klein, dass die von der Entropie vorgeschriebene Bitzahl größer als die Anzahl der Zeichen im Alphabet ist. Da die maximale Bitlänge für ein Zeichen im Baum nicht länger als die Anzahl der Zeichen sein kann, muss diesen Zeichen eine zu kurze Bitfolge zugewiesen werden.
- Außerdem gehen bei jedem Zeichen einige Bruchteile von Bits verloren, wenn die Wahrscheinlichkeit des Zeichens nicht genau ist, da diese dann mit einer nicht ganzen Anzahl von Bits kodiert werden müssten.
Diese Probleme können mit einer „Umstrukturierung“ des Alphabets vermindert werden.
- Man kann die Wahrscheinlichkeit von Zeichen senken, indem man neue Zeichen in das Alphabet einfügt, die für mehrere dieser häufigen Zeichen stehen oder für die Verknüpfung des häufigen Zeichens mit einem weiteren.
- Extrem seltenen Zeichen kann man nur gerecht werden, indem man das Alphabet mit neuen Zeichen, die für nützliche Zeichengruppen stehen, vergrößert, bis die Größe des Alphabets ausreicht, um Bäume mit der notwendigen Tiefe zu erstellen. Diese neuen Zeichen sollten Wahrscheinlichkeiten haben, die zwischen dem niedrigen Wert und den Werten der anderen Zeichen liegen.
- Um den Verschnitt zu senken, der zwangsläufig auftritt durch die Tatsache, dass ein Zeichen immer mit einer ganzzahligen Bitlänge gespeichert wird, kann man auch neue Zeichen einfügen, die für Zeichenketten stehen. Im einfachsten Fall erstellt man ein neues Alphabet, in dem jedes Zeichen für genau 2 Zeichen des Originalalphabets steht. „MISSISSIPPI!“ wird also als MI SS IS SI PP I! behandelt.
Oder man vermeidet diese Probleme und verwendet Arithmetisches Kodieren.
Weblinks
- Ein Programm zum Testen der Huffman-Kodierung (Java-Applet)
- Eine Huffman-Bäume erzeugende Webapp
- Erklärung
- Lernprogramm für die Huffman- und Shannon-Fano-Kodierung (Java)
Einzelnachweise
- ↑ D.A. Huffman: A method for the construction of minimum-redundancy codes. (PDF) In: Proceedings of the I.R.E.. September 1952, S. 1098-1101.
- ↑ Michael Brückner: Dynamisches Huffman-Verfahren. Seminar-Papier SS 2001, Professur Theoretische Informatik und Informationssicherheit, TU Chemnitz (Online-Dokument, PDF)




Wikimedia Foundation.