- Entropie (Informationstheorie)
-
Entropie ist ein Maß für den mittleren Informationsgehalt oder auch Informationsdichte eines Zeichensystems. Der Begriff in der Informationstheorie ist in Analogie zur Entropie in der Thermodynamik und Statistischen Mechanik benannt.
Das informationstheoretische Verständnis des Begriffes Entropie geht auf Claude E. Shannon zurück und existiert seit etwa 1948. In diesem Jahr veröffentlichte Shannon seine fundamentale Arbeit A Mathematical Theory of Communication[1] und prägte damit die moderne Informationstheorie.Die Bezeichnung H für die Entropie rührt aus einer Verwechslung mit dem ursprünglich gewählten großen Eta (Η) für das Kunstwort εντροπία.[2]
Definition
Claude Elwood Shannon definierte die Entropie H einer diskreten gedächtnislosen Quelle (diskreten Zufallsvariable) X über einem endlichen Alphabet
 wie folgt: Zunächst ordnet man jeder Wahrscheinlichkeit p eines Ereignisses seinen Informationsgehalt I(p) = − log 2p zu. Dann ist die Entropie eines Zeichens definiert als der Erwartungswert des Informationsgehalts
wie folgt: Zunächst ordnet man jeder Wahrscheinlichkeit p eines Ereignisses seinen Informationsgehalt I(p) = − log 2p zu. Dann ist die Entropie eines Zeichens definiert als der Erwartungswert des Informationsgehalts ,
,
Sei
 , dann ist pz = P(X = z) die Wahrscheinlichkeit, mit der das Zeichen z des Alphabets auftritt, oder gleichwertig
, dann ist pz = P(X = z) die Wahrscheinlichkeit, mit der das Zeichen z des Alphabets auftritt, oder gleichwertig ,
,
dabei wird
 gesetzt (entsprechend dem Grenzwert
gesetzt (entsprechend dem Grenzwert  ). Summanden mit verschwindender Wahrscheinlichkeit tragen daher per Definition nicht zur Summe bei.
). Summanden mit verschwindender Wahrscheinlichkeit tragen daher per Definition nicht zur Summe bei.Die Entropie Hn für Wörter w der Länge n ergibt sich durch
 ,
,
wobei pw = P(X = w) die Wahrscheinlichkeit ist, mit der das Wort w auftritt. Die Entropie H ist dann der Limes
 davon:
davon: .
.
Wenn die einzelnen Zeichen voneinander stochastisch unabhängig sind, dann gilt Hn = nH1 für alle n, also H = H1 (vgl. Blockentropie)
Interpretation
Entropie ist ein Maß für den mittleren Informationsgehalt pro Zeichen einer Quelle, die ein System oder eine Informationsfolge darstellt. In der Informationstheorie spricht man bei Information ebenso von einem Maß für beseitigte Unsicherheit. Je mehr Zeichen im Allgemeinen von einer Quelle empfangen werden, desto mehr Information erhält man und gleichzeitig sinkt die Unsicherheit über das, was hätte gesendet werden können.
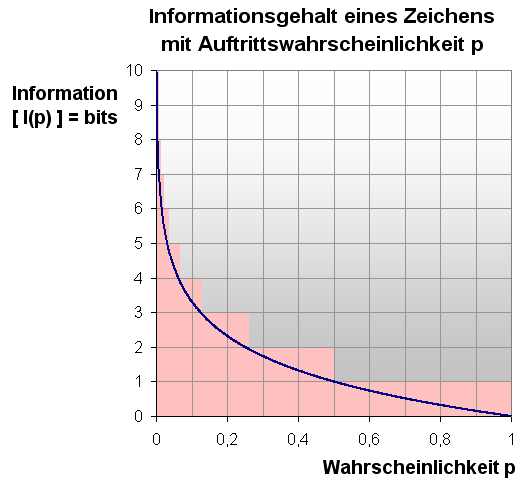
 Je kleiner die Auftrittswahrscheinlichkeit eines Zeichens ist, desto höher ist seine Information. Andersherum ist die Information eines Zeichens gering, wenn es oft vorkommt.
Je kleiner die Auftrittswahrscheinlichkeit eines Zeichens ist, desto höher ist seine Information. Andersherum ist die Information eines Zeichens gering, wenn es oft vorkommt.
Anschaulich lässt sich die Definition des Informationsgehalts wie folgt begründen: Wenn ein unabhängiges Ereignis, das mit Wahrscheinlichkeit pi eintreten kann, tatsächlich eintritt, dann wird dadurch ein konkretes Ereignis aus einer hypothetischen Menge von
 gleich wahrscheinlichen unabhängigen Ereignissen ausgewählt. Um diese Anzahl von Ereignissen unterscheiden zu können benötigt man
gleich wahrscheinlichen unabhängigen Ereignissen ausgewählt. Um diese Anzahl von Ereignissen unterscheiden zu können benötigt man  Binärbits. Dieser Wert gibt also den Informationsgehalt eines speziellen Ereignisses in Bits an. Gewichtet man den tatsächlichen Informationsgehalt der möglichen Ereignisse mit der jeweiligen Eintrittswahrscheinlichkeit, so erhält man den mittleren oder erwarteten Informationsgehalt eines Zeichens.
Binärbits. Dieser Wert gibt also den Informationsgehalt eines speziellen Ereignisses in Bits an. Gewichtet man den tatsächlichen Informationsgehalt der möglichen Ereignisse mit der jeweiligen Eintrittswahrscheinlichkeit, so erhält man den mittleren oder erwarteten Informationsgehalt eines Zeichens.Die Einheit 1 Shannon ist definiert als der Informationsgehalt eines Ereignisses mit der Wahrscheinlichkeit p = 0,5. Ein Beispiel für ein solches Ereignis ist das Ergebnis Kopf eines Münzwurfs.
Die Basis 2 für den Logarithmus ist willkürlich. Es stellt sich nur heraus, dass sich Bits (Binärziffern) besonders einfach technisch handhaben lassen. Würde eine andere Basis gewählt werden, zum Beispiel 3, so erhielte man ternäre Ziffern (Trits). Der Informationsgehalt lässt sich leicht durch Multiplikation mit dem Modulus log 32 von Bits auf Trits umrechnen.
Die mindestens notwendige Anzahl von Bits, die zur Darstellung der Information (des Textes) notwendig sind, ergibt sich aus dem Produkt des durchschnittlichen Informationsgehalts eines Zeichens H(X) und der Anzahl N verschiedener Zeichen im Informationstext (=Alphabetgröße): H(X) | Z | bzw. H(X)N.
Shannons ursprüngliche Absicht, die Entropie als das Maß der benötigten Bandbreite eines Übertragungskanals zu nutzen, wurde schnell verallgemeinert. Die Entropie wurde generell als ein Maß für den Informationsgehalt betrachtet. Bei einer kleinen Entropie enthält der Informationstext Redundanzen oder statistische Regelmäßigkeiten.
Die Entropie ist im Allgemeinen nicht durch (1) gegeben. Beispielsweise ist die Wahrscheinlichkeit, eine 0 oder 1 in der Zeichenkette
 zu finden, genauso groß, wie in einer Zeichenkette, die durch statistisch unabhängige Ereignisse (etwa wiederholten Münzwurf) entstanden ist. Daher ist die Entropie H1 einzelner Zeichen für beide Zeichenketten gleich, obwohl die erste Kette weniger zufällig ist. Bereits H2 zeigt einen Unterschied: Die erste Zeichenkette liefert H2 = 1 / 2, die zweite liefert H2 = 4. Man kann das auch so deuten: Die Wahrscheinlichkeit eines Zeichens hängt vom vorangegangenen Zeichen ab. Stochastische Unabhängigkeit ist also nicht gegeben.
zu finden, genauso groß, wie in einer Zeichenkette, die durch statistisch unabhängige Ereignisse (etwa wiederholten Münzwurf) entstanden ist. Daher ist die Entropie H1 einzelner Zeichen für beide Zeichenketten gleich, obwohl die erste Kette weniger zufällig ist. Bereits H2 zeigt einen Unterschied: Die erste Zeichenkette liefert H2 = 1 / 2, die zweite liefert H2 = 4. Man kann das auch so deuten: Die Wahrscheinlichkeit eines Zeichens hängt vom vorangegangenen Zeichen ab. Stochastische Unabhängigkeit ist also nicht gegeben.Für aufeinander folgende Ereignisse, die nicht stochastisch unabhängig sind, reduziert sich die Entropie aufeinander folgender abhängiger Ereignisse fortlaufend. In einem solchen Fall kann man auch mit der bedingten Entropie und der Quellentropie arbeiten, die beide auf Verbundwahrscheinlichkeiten aufbauen.
In engem Zusammenhang mit bedingter Entropie steht auch die Transinformation, welche die Stärke des statistischen Zusammenhangs zweier Zufallsgrößen angibt.
Noch einfacher formuliert, ist die Entropie die durchschnittliche Anzahl von Entscheidungen (bits), die benötigt werden, um ein Zeichen aus einer Zeichenmenge zu identifizieren oder zu isolieren.
Es ist sinnvoll, dass ein Alphabet aus mindestens zwei verschiedenen Zeichen vorliegt. Eine Alphabetsgröße von eins bedeutet, dass man weder über neu ankommende Zeichen aus der Senderquelle neue Information erhält, noch die Unsicherheit über das vorangegangene Zeichen verringern kann.
Maximaler Entropiewert und Normierung
Möchte man ein normiertes Maß für die Entropie einer beliebigen diskreten Verteilung haben, ist es von Vorteil, die maximal mögliche Entropie, die bei Gleichverteilung der pi erreicht wird, zur Normierung heranzuziehen. Sei N = | Z | die Anzahl der Zeichen in X über dem Alphabet Z, dann ist die maximale Entropie Hmax gegeben durch:
Daraus folgt beispielsweise Hmax = 1 für eine Binärverteilung (Z = {0,1}), also benötigt man ein Bit pro Zeichen und | I | Zeichen für die komplette Information I. Dieser Wert wird erreicht, wenn Nullen und Einsen gleich häufig vorkommen. Normiert man nun die Entropie einer beliebigen Verteilung mit N = | Z | verschiedenen Zeichen mit Hmax erhält man:
Die so erhaltene Entropie wird immer maximal gleich 1.
Um die Entropien von Nachrichten unterschiedlicher Länge vergleichen zu können, hat man die Entropierate eingeführt, die die Entropie auf das einzelne Zeichen bezieht (siehe dort).
Beispiel Alphabet
Bei gleichmäßiger Verteilung kann bei einem Alphabet auf kein Zeichen verzichtet werden. Dagegen ist die Buchstabenhäufigkeit in der deutschen Sprache ungleichmäßig. Beispielsweise ist der Buchstabe E sieben Mal so häufig wie M oder O, was zu Redundanz im Alphabet führt. Nun möchte man herausbekommen, wie groß diese Redundanz ist.
Sei N = 26 die Größe des Alphabets. Die Redundanz R berechnet sich mit R = Hmax - H. Für das deutsche Alphabet errechnet man anhand der Buchstabenhäufigkeit eine Entropie H von 4,0629 bit/Zeichen. Die maximale Entropie beträgt Hmax = log2|26| = 4,7004 bit/Zeichen. Damit folgt eine Redundanz von R = 4,7004 - 4,0629 = 0,6375 bit/Zeichen. Berechnet man weiter die gesamte Redundanz, die sich aus der Summe der Redundanzen eines jeden Zeichens ergibt, so erhält man R⋅N = 16,575 Bits. Nun wäre interessant zu wissen, wie vielen Zeichen dies aus unserem Alphabet entspricht. Dividiert man die redundanten Bits durch den durchschnittlichen Informationsgehalt eines gleichverteilten Zeichens, so erhält man (R⋅N)/Hmax = 3,53 Zeichen → 3 Zeichen (ohne Redundanzen). Rechnet man allerdings (R⋅N)/H = 4,08 (⇒ 4 Zeichen), so bestimmt man die Anzahl von Zeichen mit einer Redundanz, wie sie auch im Alphabet vorhanden ist.
Ohne Informationsverlust könnte das Alphabet also um vier Buchstaben reduziert werden. Diese Überlegung berücksichtigt nur die statistische Verteilung der Buchstaben. Häufige Buchstabenkombinationen wie SCH oder ST bleiben genauso unberücksichtigt (bedingte Entropie) wie gleich klingende Buchstaben (Q, K).
Beispiel Münzwurf
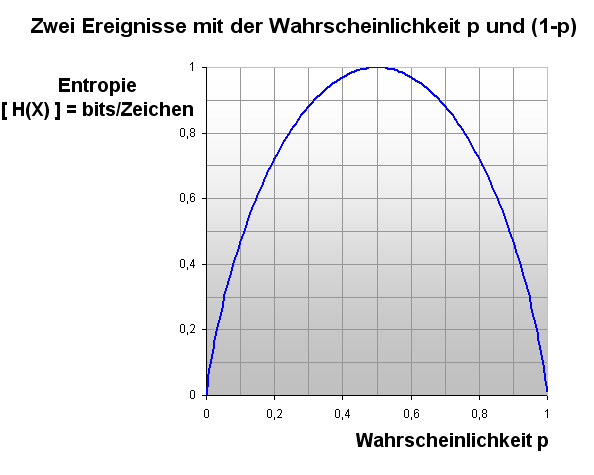
 Maximale Entropie bei p=0.5
Maximale Entropie bei p=0.5Bei einem Münzwurf sind idealerweise Kopf oder Zahl gleich wahrscheinlich. Wenn man die Entropie als Maß für die Ungewissheit auffasst, wird sie hier einen maximalen Wert aufweisen. Es ist völlig ungewiss, ob beim nächsten Wurf Kopf oder aber Zahl geworfen wird.
Sei X eine diskrete Zufallsvariable und der Erwartungswert
 mit
mit (Kopf) und
(Kopf) und (Zahl),
(Zahl),
so ergibt sich aus obiger Definition Entropie H = 1 bit.
Anders bei einer gezinkten Münze, etwa einer Münze, die im Mittel in 60 % der Fälle Kopf und nur in 40 % der Fälle Zahl anzeigt. Die Ungewissheit ist hier geringer als bei der normalen Münze, da man eine gewisse Präferenz für Kopf hat. Gemessen als Entropie liegt die Ungewissheit bei nur noch etwa 0,971.
Die Summe der Wahrscheinlichkeiten ist immer 1.
- p + q = 1
Die Entropie lässt sich in diesem Fall mit folgender Formel berechnen:
Ersetzt man q durch den Ausdruck 1 − p, so erhält man die Formel
Dies kann man grafisch folgendermaßen darstellen:
Für jedes p kann man daraus die Entropie direkt ablesen. Die Funktion ist symmetrisch zur Geraden p = 0,5. Sie fällt bei p = 0 steil zu einem Entropie-Wert von 0 ab. Auch bei Werten, die sich dem sicheren Ereignis von p = 1 nähern, fällt die Entropie auf 0 ab.
Dieser Zusammenhang gilt jeweils für ein Zufallsereignis. Bei mehreren Zufallsereignissen muss man die einzelnen Entropien zusammenzählen und man kann so leicht Entropiewerte über 1 erreichen. Die Wahrscheinlichkeit p dagegen bleibt auch bei Wiederholungen definitionsgemäß immer zwischen 0 und 1.
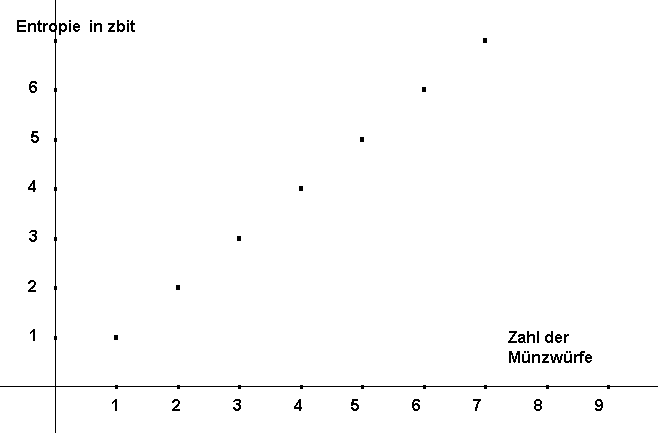
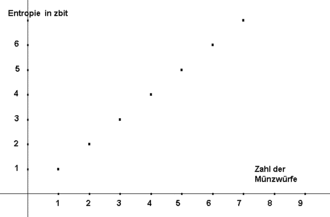 Entropie in Abhängigkeit von der Zahl der Münzwürfe
Entropie in Abhängigkeit von der Zahl der MünzwürfeWiederholt man den Münzwurf zweimal, wächst die Zahl der Möglichkeiten auf vier. Die Wahrscheinlichkeit jeder einzelnen Möglichkeit liegt bei 0,25. Die Entropie des zweimaligen Münzwurfes ist dann 2 Sh. Wenn man einen idealen Münzwurf mehrfach wiederholt, dann addiert sich die Entropie einfach. Die Entropie einer Reihe von 20 idealen Münzwürfen berechnet sich einfach:
 . Dies ist im Bild dargestellt.
. Dies ist im Bild dargestellt.Man kann nicht einfach aus einem Wert der Wahrscheinlichkeit die Entropie ausrechnen. Die Entropie betrifft den gesamten Zufallsprozess. Jede Teilwahrscheinlichkeit eines möglichen Ergebnisses geht in die Berechnung der Entropie des Gesamtprozesses ein. Die Angabe einer Teilentropie für jedes mögliche Ergebnis ist dabei wenig sinnvoll. In der Shannonschen Entropieformel sollte also die Summe der Wahrscheinlichkeiten 1 ergeben, sonst kann das Ergebnis missverständlich sein.
Speichert man eine Folge von Münzwürfen als Bitfolge, dann bietet es sich an, Kopf stets durch 0 und Zahl stets durch 1 zu repräsentieren (oder umgekehrt). Bei der gezinkten Münze sind kompaktere Kodierungen möglich. Diese erhält man beispielsweise durch den Huffman-Kode.
Beispiel idealer Würfel
Bei einem Wurf eines idealen Würfels mit sechs Möglichkeiten ist die Entropie größer als 1. Im Allgemeinen ist die Entropie größer als 1 für ein Zufallsereignis mit stochastisch unabhängigen Zufallsvariablen aus einem Zufallsexperiment mit mehr als zwei gleichberechtigten Möglichkeiten im Ergebnisraum. Ihr Wert wird bei gleichwahrscheinlichen Möglichkeiten im Ergebnisraum folgendermaßen berechnet:
Anzahl der Möglichkeiten: N, damit ergibt sich für die Wahrscheinlichkeiten
 und für die Entropie
und für die Entropie .
.
Beim idealen Würfel sind sechs Möglichkeiten im Ergebnisraum. Daraus folgt die Entropie für einmaliges Werfen:
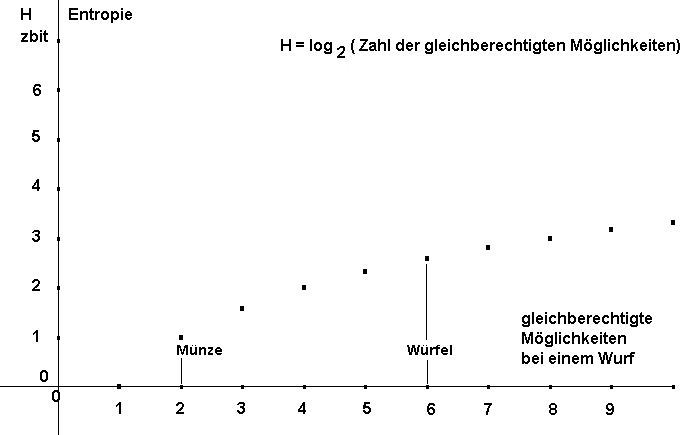
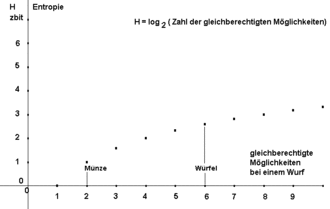 Entropie vs. Zahl der Möglichkeiten
Entropie vs. Zahl der MöglichkeitenEinfach zu berechnen ist die Entropie eines Wurfes eines idealen Achterwürfels: Er hat acht gleichberechtigte Möglichkeiten.
Die Entropie eines Wurfes mit dem idealen Achterwürfel entspricht der Entropie von drei Würfen mit der idealen Münze.
Die Abbildung stellt den Zusammenhang zwischen der Entropie und der Zahl der gleichberechtigten Möglichkeiten eines Zufallsexperimentes dar.
Entropietests
Um zu testen, wie gut Daten komprimierbar sind, oder um Zufallszahlen zu testen, werden Entropietests verwendet. Als Zufallszahltest wird die Entropie einer bestimmen Anzahl von Zufallszahlen bestimmt und ab einem Mindestwert, beispielsweise 7 Bit je Byte, gilt er als bestanden. Allerdings gibt es viele solcher Tests, da die Entropie nicht eindeutig ist; sie kann beispielsweise bitbasiert oder bytebasiert definiert sein.
Ein einfaches Beispiel:
Eine Quelle, etwa ein Spielwürfel oder eine Münze, gebe nur die Werte 0xAA (dezimal 170) und 0x55 (dezimal 85) aus, beide mit gleicher Wahrscheinlichkeit. Bitweise ist die Ausgabe zu 50 % 0 oder 1, byteweise ist sie zu 50 % 0xAA oder 0x55. Die bitweise Entropie ist (mit log = ln)

während die byteweise Entropie mit

deutlich kleiner ist.
Der Hersteller dieses Zufallszahlengenerators wird natürlich als Entropie des Geräts die bitweise Entropie, also 1, angeben. Analog wird ein Programmierer eines Kompressionsprogramms möglichst diejenige Basis wählen, bei der die Entropie minimal ist (hier Bytes), sich also die Daten am besten komprimieren lassen.
Dieses Beispiel ist wenig realistisch, da nur zwei von 256 möglichen Werten verwendet werden, aber wenn auch die anderen Bytes mit einer kleinen Wahrscheinlichkeit von beispielsweise 1/123456789 ausgegeben werden, so ändert dies an der bitweisen Entropie nichts und die byteweise wird kaum größer; sie bleibt unter 1/2. Erst mit Annäherung der Byte-Wahrscheinlichkeiten an 1/256 erreicht die byteweise Entropie den Wert 1, aber dann kann es noch Korrelationen der Bytes geben, also etwa die Folge 0xaaaa viel häufiger sein als die Folge 0x5555. Dies ist der Hauptgrund, weshalb es viele verschiedene Zufallszahlentests gibt.
Diese Mehrdeutigkeit ist nicht möglich beim Entropiebelag, da dort nicht nur über Wahrscheinlichkeiten summiert wird, sondern über ergodische Wahrscheinlichkeiten von Zuständen, Zustandsübergangswahrscheinlichkeiten und bedingte Wahrscheinlichkeiten. Berechnet wird er mit der Theorie der Markow-Kette. Allerdings ist der Rechenaufwand dafür bei realen Zufallszahlengeneratoren hoch.
Datenkompression und Entropie
Die Entropiekodierung ist ein Kompressionsalgorithmus, um Daten verlustfrei zu komprimieren.
In diesem Zusammenhang spielen die Kreuzentropie sowie die Kullback-Leibler-Divergenz als Maß für die durch eine schlechte Kodierung ausgelösten Verschwendungen von Bits eine Rolle.
Beispiel:
- Gegeben sei die Zeichenkette ABBCAADA (siehe auch Entropiekodierung).
- Die Buchstaben-Wahrscheinlichkeit: pA = 4 / 8 = 0,5; pB = 0,25; pC = pD = 0,125

- Maximalentropie (pA = pB = pC = pD = 0,25):

- Die Maximalentropie lässt sie ebenso mit der Formel der maximalen Entropie berechnen:

Alternative Möglichkeiten der Informationsquantifizierung
Ein anderer Zugang, den Informationsgehalt einer Nachricht zu messen, ist durch die Kolmogorow-Komplexität gegeben, worin der kürzestmögliche Algorithmus zur Darstellung einer gegebenen Zeichenkette die Komplexität der Nachricht angibt. Ähnlich ist die Logische Tiefe definiert, die sich aber auf die Zeitkomplexität eines Algorithmus zur Erzeugung der Daten bezieht. Gregory Chaitin ist ebenfalls über die Shannonsche Definition der Entropie einer Information hinausgegangen (siehe Algorithmische Informationstheorie).
Ähnlichkeit zur Entropie in der Physik
In der Physik (siehe Thermodynamik) spielt eine gleich benannte Größe, die (physikalische) Entropie eine wesentliche Rolle[3]. Die Ähnlichkeiten sind in der Tat mehr als formal: die physikalische Entropie unterscheidet sich von der Shannon'schen Informationsentropie nur durch einen zusätzlichen Normierungsfaktor
 die sog. Boltzmannsche Konstante, und durch die Ersetzung der im Logarithmus benutzten Basis (der duale Logarithmus wird durch den natürlichen Logarithmus ersetzt).
die sog. Boltzmannsche Konstante, und durch die Ersetzung der im Logarithmus benutzten Basis (der duale Logarithmus wird durch den natürlichen Logarithmus ersetzt).Siehe auch
Literatur
- Rolf Johannesson: Informationstheorie, Addison-Wesley 1992, ISBN 3-89319-465-7
- Claude Elwood Shannon und Warren Weaver: The Mathematical Theory of Communication, University of Illinois Press 1963, ISBN 0-252-72548-4 (Softcover) und ISBN 0-252-72546-8 (Hardcover)
- Norbert Bischof: Struktur und Bedeutung, 1998, ISBN 3-456-83080-7 (Das Buch ist für Sozialwissenschaftler geschrieben und erklärt mathematische Zusammenhänge Nicht-Mathematikern in sehr verständlicher Weise. Das Kapitel 2 widmet sich der Informationstheorie.)
- Sven P. Thoms: Ursprung des Lebens. Fischer, Frankfurt a.M. 2005, ISBN 3-596-16128-2 (Das Buch ist aus biologischer und chemischer Perspektive geschrieben. Ein Kapitel behandelt den Zusammenhang von Leben und Entropie.)
- Thomas Cover: Elements of Information Theory, Wiley-Interscience 2006, ISBN 0-471-24195-4 (Das Buch ist nur auf Englisch erhältlich. Es behandelt ausführlich die Informationstheorie und ist mathematisch gehalten.)
- Martin Werner: Information und Codierung, Vieweg 2002, ISBN 3-528-03951-5
Weblinks
-
 Wikibooks: Entropie – Lern- und Lehrmaterialien
Wikibooks: Entropie – Lern- und Lehrmaterialien - Einführung der Entropie als Gesamtzufallsmenge mit vielen Beispielen und Erklärungen zur Formel von Shannon
- Entropie und Information
- A Mathematical Theory of Communication, Shannons Originalarbeit (englisch)
- Owen Maroney: Information Processing and Thermodynamic Entropy, in: Stanford Encyclopedia of Philosophy (englisch, inklusive Literaturangaben)
Einzelnachweise
- ↑ C. E. Shannon, “A mathematical theory of communication,” ACM SIGMOBILE Mobile Computing and Communications Review 5, no. 1 (2001): 3–55.
- ↑ Károly Simonyi: Kulturgeschichte der Physik. In: Urania-Verlag, Leipzig 1990, ISBN 3-332-00254-6, S. 372.
- ↑ Konkrete Ähnlichkeiten zwischen der Shannon'schen Informationsentropie und der thermodynamischen Entropie werden u.a. behandelt in: U. Krey, A. Owen, Basic Theoretical Physics - A Concise Overview, Berlin, Springer 2007, ISBN 978-3-540-36804-5 und in: Arieh Ben-Naim: Statistical Thermodynamics Based on Information: A Farewell to Entropy. 2008, ISBN 978-981-270-707-9






Wikimedia Foundation.