- Merkles Meta-Verfahren
-
Merkles Meta-Verfahren (auch Merkle-Damgård Konstruktion) ist eine Methode zur Konstruktion von kryptographischen Hash-Funktionen.
Gegeben ist eine Kompressionsfunktion
 , die kollisionssicher ist, d. h. es ist nicht mit realistischem Aufwand möglich, zwei verschiedene Eingaben zu finden, die von f auf die gleiche Ausgabe abgebildet werden. Durch die Anwendung von Merkles Meta-Verfahren ergibt sich daraus eine kollisionssichere Hash-Funktion
, die kollisionssicher ist, d. h. es ist nicht mit realistischem Aufwand möglich, zwei verschiedene Eingaben zu finden, die von f auf die gleiche Ausgabe abgebildet werden. Durch die Anwendung von Merkles Meta-Verfahren ergibt sich daraus eine kollisionssichere Hash-Funktion  , die beliebig lange Nachrichten auf einen Hashwert von b Bit Länge abbildet.
, die beliebig lange Nachrichten auf einen Hashwert von b Bit Länge abbildet.Inhaltsverzeichnis
Vorgehensweise
 Aus den Nachrichtenblöcken wird durch wiederholte Anwendung der Kompressionsfunktion der Hashwert erzeugt
Aus den Nachrichtenblöcken wird durch wiederholte Anwendung der Kompressionsfunktion der Hashwert erzeugt
Die Nachricht x wird zunächst mit einem Paddingverfahren zu
 erweitert, so dass die Länge von ein Vielfaches von a ist. Dann wird in n Blöcke der Länge a aufgeteilt:
erweitert, so dass die Länge von ein Vielfaches von a ist. Dann wird in n Blöcke der Länge a aufgeteilt: mit | xi | = a.
mit | xi | = a.
Die Kompressionsfunktion wird iterativ auf die b Bit lange Ausgabe der vorherigen Iteration und die nächsten a Bit der erweiterten Nachricht angewandt, bis diese ganz verarbeitet ist. Bei der ersten Iteration besteht die Eingabe aus einem b Bit langen Initialisierungsvektor, häufig mit dem Wert 0, und dem ersten Nachrichtenblock x1.
 .
.
Entweder nimmt man dann hn als Hash-Wert, oder es wird noch eine Finalisierungsfunktion darauf angewandt, die den Hash-Wert
 liefert.
liefert.Padding
Damit die Kollisionssicherheit der Kompressionsfunktion sich beweisbar auf die Hashfunktion überträgt, muss das Paddingverfahren bestimmte Bedingungen erfüllen. Folgende Bedingungen sind dafür hinreichend:[1]
- x ist ein Anfangsstück von , d. h. die Nachrichten werden nicht verändert, nur mit einem Endstück erweitert.
- Zwei Nachrichten der gleichen Länge werden mit gleich langen Endstücken erweitert.
- Zwei verschieden lange Nachrichten werden unterschiedlich erweitert, so dass sie sich im letzten Block, der in die letzte Kompressionsstufe eingegeben wird, unterscheiden.
Typischerweise wird beim Padden eine Codierung der Bitlänge
 an die Nachricht angehängt, und dazwischen werden ggfs. Bits mit dem Wert 0 eingefügt, damit
an die Nachricht angehängt, und dazwischen werden ggfs. Bits mit dem Wert 0 eingefügt, damit  ein Vielfaches von a ist:
ein Vielfaches von a ist:Schwächen
Eine Schwäche ist ein möglicher Erweiterungs-Angriff (Extension-Attack): Kennt man den Hashwert h(x) einer unbekannten Nachricht x, und fehlt die Finalisierungsfunktion oder kann man deren Umkehrung berechnen, dann kann man leicht den Hashwert
 einer Nachricht bestimmen, die aus der wie oben gepaddeten Nachricht durch Anfügen einer Erweiterung y hervorgeht. Man kann also Hashwerte zu Nachrichten bestimmen, die x als Anfangsstück haben, auch wenn man x nicht kennt.[2] Da ein Zufallsorakel diese Eigenschaft nicht hat, können sich daraus Angriffe auf Verfahren ergeben, die nur im Random-Oracle-Modell einen Sicherheitsbeweis haben.[3] Daraus folgt auch: wenn man einmal eine Kollision zweier Nachrichten mit gleicher Blocklänge n gefunden hat, kann man durch Erweiterung leicht weitere Kollisionen bestimmen.
einer Nachricht bestimmen, die aus der wie oben gepaddeten Nachricht durch Anfügen einer Erweiterung y hervorgeht. Man kann also Hashwerte zu Nachrichten bestimmen, die x als Anfangsstück haben, auch wenn man x nicht kennt.[2] Da ein Zufallsorakel diese Eigenschaft nicht hat, können sich daraus Angriffe auf Verfahren ergeben, die nur im Random-Oracle-Modell einen Sicherheitsbeweis haben.[3] Daraus folgt auch: wenn man einmal eine Kollision zweier Nachrichten mit gleicher Blocklänge n gefunden hat, kann man durch Erweiterung leicht weitere Kollisionen bestimmen.Mehrfachkollisionen zu finden, also mehrere Nachrichten, die alle den gleichen Hashwert haben, erfordert nur wenig mehr Aufwand als das Bestimmen einer einzelnen Kollision.[4]
Ein Herding-Angriff, also zu einem selbst gewählten Hashwert z und einem gegebenem Anfangsstück x einer Nachricht ein passendes Endstück zu finden, so dass die gesamte Nachricht zu z hasht, d. h. ein y mit
 zu finden, erfordert zwar mehr Aufwand als das Finden einer Kollision, aber wesentlich weniger, als es für ein Zufallsorakel als Hashfunktion h der Fall sein sollte.[5]
zu finden, erfordert zwar mehr Aufwand als das Finden einer Kollision, aber wesentlich weniger, als es für ein Zufallsorakel als Hashfunktion h der Fall sein sollte.[5]Ein Angriff zur Bestimmung eines zweiten Urbildes (second preimage attack), bei dem man zu einer gegebenen Nachricht x eine zweite
 mit demselben Hashwert
mit demselben Hashwert  sucht, ist bei einer Nachricht der Länge von 2k Blöcken mit dem Zeitaufwand k2b / 2 + 1 + 2b − k + 1 möglich, und damit bei langen Nachrichten erheblich schneller als durch systematisches Probieren (brute force), was etwa 2b Schritte erfordert.[6]
sucht, ist bei einer Nachricht der Länge von 2k Blöcken mit dem Zeitaufwand k2b / 2 + 1 + 2b − k + 1 möglich, und damit bei langen Nachrichten erheblich schneller als durch systematisches Probieren (brute force), was etwa 2b Schritte erfordert.[6]Verbesserungen
Um besagte Schwächen zu überwinden, hat Stefan Lucks die wide-pipe-hash-Konstruktion vorgeschlagen:[7] Um einen Hashwert von b Bit Länge zu berechnen, verwendet man eine Kompressionsfunktion
 , deren Ausgabe länger als b ist, typischerweise doppelt so lang. komprimiert also 2b Bit aus der vorherigen Iteration und einen a Bit langen Nachrichtenblock zu einer Ausgabe von 2b Bit. Nach der letzten Iteration wird die Ausgabe durch eine weitere Kompressionsfunktion von 2b auf b Bit verkürzt, falls man nicht einfach die halbe Ausgabe verwirft und die andere Hälfte als Hashwert verwendet.
, deren Ausgabe länger als b ist, typischerweise doppelt so lang. komprimiert also 2b Bit aus der vorherigen Iteration und einen a Bit langen Nachrichtenblock zu einer Ausgabe von 2b Bit. Nach der letzten Iteration wird die Ausgabe durch eine weitere Kompressionsfunktion von 2b auf b Bit verkürzt, falls man nicht einfach die halbe Ausgabe verwirft und die andere Hälfte als Hashwert verwendet.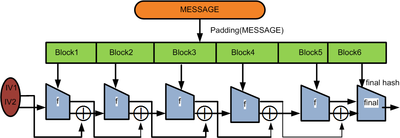 fast wide pipe hash
fast wide pipe hashNandi und Paul haben gezeigt, dass diese Konstruktion etwa doppelt so schnell gemacht werden kann (fast wide pipe hash), indem man nur b Bit aus den vorhergehenden Kompressionen in die nächste Kompression eingibt, zusammen mit einem a + b Bit langen Nachrichtenblock xi. Die andere Hälfte der 2b-Kompressionsausgabe wird mit der darauf folgenden Eingabe XOR-verknüpft:[8]
In der letzten Stufe wird die Ausgabe der vorletzten komplett verarbeitet, und der Nachrichtenblock xn ist dafür nur a Bit breit (falls man hier nicht eine andere Kompressionsfunktion mit größerer Eingabe verwendet):
 und
und  bedeuten dabei die erste bzw. die zweite Hälfte der Bittkette c.
bedeuten dabei die erste bzw. die zweite Hälfte der Bittkette c.Einzelnachweise
- ↑ Goldwasser, S. and Bellare, M. "Lecture Notes on Cryptography". Summer course on cryptography, MIT, 1996-2001
- ↑ Yevgeniy Dodis, Thomas Ristenpart, Thomas Shrimpton. Salvaging Merkle–Damgård for Practical Applications. Preliminary version in Advances in Cryptology - EUROCRYPT '09 Proceedings, Lecture Notes in Computer Science Vol. 5479, A. Joux, ed, Springer-Verlag, 2009, pp. 371–388.
- ↑ J.S. Coron, Y. Dodis, C. Malinaud, und P. Puniya. Merkle–Damgård Revisited: How to Construct a Hash Function. Advances in Cryptology – CRYPTO '05 Proceedings, Lecture Notes in Computer Science, Vol. 3621, Springer-Verlag, 2005, pp. 21–39.
- ↑ Antoine Joux. Multicollisions in iterated hash functions. Application to cascaded construction. In Advances in Cryptology - CRYPTO '04 Proceedings, Lecture Notes in Computer Science, Vol. 3152, M. Franklin, ed, Springer-Verlag, 2004, pp. 306–316.
- ↑ John Kelsey und Tadayoshi Kohno. Herding Hash Functions and the Nostradamus Attack In Eurocrypt 2006, Lecture Notes in Computer Science, Vol. 4004, S. 183–200.
- ↑ John Kelsey and Bruce Schneier. Second preimages on n-bit hash functions for much less than 2n work. In Ronald Cramer, editor, EUROCRYPT, volume 3494 of LNCS, pages 474–490. Springer, 2005.
- ↑ S. Lucks, Design Principles for Iterated Hash Functions, In: Cryptology ePrint Archive, Report 2004/253, 2004.
- ↑ Mridul Nandi and Souradyuti Paul. Speeding Up the Widepipe: Secure and Fast Hashing. In Guang Gong and Kishan Gupta, editor, Indocrypt 2010, Springer, 2010.
Literatur
- Hans Delfs, Helmut Knebl, Introduction to Cryptography, Springer 2002, S. 40, ISBN 3-540-42278-1
Kategorie:- Kryptologisches Verfahren




Wikimedia Foundation.