- Nukleotidsequenz
-
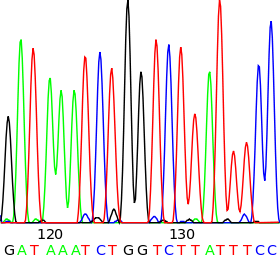 Ausschnitt aus dem Chromatogramm einer automatischen DNA-Sequenzierung.
Ausschnitt aus dem Chromatogramm einer automatischen DNA-Sequenzierung.
Die Nukleotidsequenz oder Basensequenz ist die Abfolge der Nukleotide einer Nukleinsäure.
Bei der Notation werden für die Nukleinbasen der Nukleotide die Anfangsbuchstaben ihrer Bezeichnungen verwendet: für Adenin A, Guanin G, Thymin T, Uracil U und Cytosin C. Bei der Desoxyribonukleinsäure (DNA) kommen die vier Basen Adenin, Guanin, Thymin und Cytosin vor, bei der RNA Adenin, Guanin, Uracil und Cytosin.
Übereinkunftsgemäß wird die Nukleotidsequenz vom 5'-Ende zum 3'-Ende des Stranges gelesen, in der gleichen Richtung, in der die Polymerase die Nukleinsäure synthetisiert.
Bestimmung
Eine Nukleotidsequenz von DNA wird durch DNA-Sequenzierung ermittelt. Nukleotidsequenzen von DNA werden unter anderem in großen öffentlichen Sequenzdatenbanken wie z. B. GenBank gespeichert.
Statistische Analyse
Aufgrund der Darstellung als Symbolfolge lässt sich die DNA statistisch gut untersuchen. Es kann beispielsweise die Häufigkeit so genannter n-Tupel, d. h. das Vorkommen von Teilwörtern der Länge n untersucht werden. So taucht im menschlichen Genom im Mittel die Folge "CG" deutlich seltener auf als alle anderen 2er-Wörter. Die lokalen Häufigkeitsverteilungen verschiedener Nukleotidwörter können erste Hinweise auf die Funktionen bestimmter DNA-Abschnitte geben (CpG-Inseln, Stoppcodons, Sequenzenden von Introns).
Siehe auch

Wikimedia Foundation.