- Primärstruktur
-
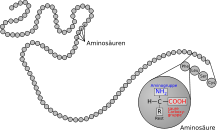 Die Primärstruktur eines Proteins ist die Abfolge seiner Aminosäuren (Aminosäuresequenz)
Die Primärstruktur eines Proteins ist die Abfolge seiner Aminosäuren (Aminosäuresequenz)
Unter Primärstruktur versteht man in der Biochemie die unterste Ebene der Strukturinformation eines Biopolymers oder auch synthetischen Polymers (Kunststoff), d. h. die Sequenz der einzelnen Bausteine. Bei Proteinen ist dies die Abfolge der Aminosäuren (Aminosäuresequenz), bei Nukleinsäuren (DNA und RNA) die der Nukleotide (Nukleotidsequenz).
Aus der Primärstruktur eines Proteins leiten sich seine weiteren Strukturen zwingend ab. Zur Zeit existiert jedoch keine verlässliche Methode, aus dieser in der Primärstruktur enthaltenen Information fehlerfrei abzuleiten, wie die resultierende Kette räumlich angeordnet ist. In der Regel lassen sich meist jedoch aus Erfahrungswerten sowohl Voraussagen über wahrscheinliche Strukturelemente als auch über die Funktion des Proteins treffen.
Aus der Basensequenz einer Nukleinsäure kann – da der genetische Code bekannt ist, und jedes Codon für eine Aminosäure codiert – die Primärsequenz des resultierenden Proteins ermittelt werden. Umgekehrt ist das nicht ohne weiteres möglich, da die meisten Aminosäuren mehr als nur ein Codon haben. Man sagt aus diesem Grund auch, der genetische Code ist degeneriert.[1]
Für die Angabe der Primärstruktur existieren vereinbarte Konventionen[2]
- Proteine werden vom aminoterminalen Ende (N-Terminus) zum carboxylterminalen Ende (C-Terminus) geschrieben.
- Nukleinsäuren (DNA, RNA) werden vom 5'-Phosphat-Ende zum 3'-Hydroxyl-Ende geschrieben.
Inhaltsverzeichnis
Analyse der Primärstruktur
Proteine
Die klassische Methode zur Sequenzierung von Proteinen wurde von Pehr Edman entwickelt. Der Edman-Abbau hat im Wesentlichen drei Schritte:
- Markierung der ersten N-terminalen Aminosäure durch Phenylisothiocyanat.
- Abspaltung der markierten Aminosäure.
- Identifikation der abgespalteten Aminosäure, z. B. durch HPLC oder durch Ionenaustauschchromatographie
Dann beginnt ein neuer Zyklus.
Die Methode wurde weitgehend automatisiert und funktioniert für Peptide bis zu einer Länge von ca. 50 Aminosäuren. Größere Proteine werden vor der Analyse in Fragmente gespalten, die getrennt sequenziert werden. In letzter Zeit gewinnen auch verstärkt massenspektroskopische Methoden an Bedeutung in diesem Bereich.[3]
Nukleinsäuren
DNA
Eine Methode zur DNA-Sequenzierung wurde 1965 von Frederick Sanger entwickelt und wird auch Didesoxy- bzw. Kettenabbruchmethode genannt. Der Einbau von Didesoxy-Nukleotiden führt zum Abbruch der Synthesereaktion - wenn man nun vier Reaktionsansätze macht, in denen zusätzlich jeweils eine Art von Didesoxy-Nukleotid eingesetzt wird, erhält man zum Beispiel im Didesoxy-Cytosin enthaltenden Ansatz ausschließlich Fragmente, die mit Cytosin enden. Die entstandenen Fragmente können nun durch parallele Agarose-Gelelektrophorese nach ihrer Länge aufgetrennt werden. Das Fragment das am schnellsten läuft, ist das kürzeste – befindet es sich beispielsweise in der Gelspur des Ansatzes mit Didesoxy-Cytosin, so ist die erste Base Cytosin.
Auch dieses Verfahren wurde weitgehend automatisiert – hier erfolgt die Auftrennung durch Elektrophorese meist in einer gemeinsamen Gelspur, die Unterscheidung der Fragmente erfolgt durch Fluoreszenzmarkierungen, die durch einen Laser detektiert werden.[4]
RNA
RNA wird in DNA umgeschrieben und als DNA sequenziert (siehe oben). Die Umschreibung erfolgt durch ein Enzym, die Reverse Transkriptase. Das Resultat dieses Vorgangs ist cDNA; siehe Herstellung von cDNA.[5]
Siehe auch
Einzelnachweise
- ↑ Löffler, Petrides, Heinrich: Biochemie und Pathobiochemie, 8. Auflage, Springer Medizin Verlag, Heidelberg (2007), S. 289, ISBN 978-3540326809.
- ↑ Löffler, Petrides, Heinrich: Biochemie und Pathobiochemie, 8. Auflage, Springer Medizin Verlag, Heidelberg (2007), S. 58, 147, ISBN 978-3540326809.
- ↑ Wilson, Walker: Principles and Techniques of Biochemistry and Molecular Biology, 6. Auflage, Cambridge University Press, New York (2005), S. 380 ff., ISBN 978-0-521-53581-6.
- ↑ Strachan, Read: Human Molecular Genetics, 4. Auflage, Garland Science, New York (2011), S. 217 ff., ISBN 978-0-815-34149-9.
- ↑ Strachan, Read: Human Molecular Genetics, 4. Auflage, Garland Science, New York (2011), S. 183, ISBN 978-0-815-34149-9.

Wikimedia Foundation.